Universal functions (ufunc)¶
通用函数(或简称为ufunc)是以逐元素方式操作ndarrays的函数,支持array broadcasting type casting和其他几个标准功能。也就是说,ufunc是一个函数的“向量化”包装器,它接受固定数量的标量输入并产生固定数量的标量输出。
在NumPy中,通用函数是numpy.ufunc类的实例。许多内置函数在编译的C代码中实现,但是ufunc实例也可以使用frompyfunc工厂函数生成。
Broadcasting¶
每个通用函数接受数组输入,并通过对输入执行元素方面的核心功能来生成数组输出。应用标准广播规则,使得不共享完全相同形状的输入仍然可以被有用地操作。广播可以通过四个规则来理解:
- 具有
ndim小于输入数组最大ndim的所有输入数组在其形状前面加上1。 - 输出形状的每个维度中的大小是该维度中所有输入大小的最大值。
- 如果输入在特定维中的大小与该维中的输出大小匹配,或者其值精确为1,则可以在计算中使用该输入。
- 如果输入的形状为维度大小为1,则该维度中的第一个数据条目将用于沿该维度的所有计算。换句话说,ufunc的步进机器将不会沿着该维度(对于该维度,stride将为0)。
广播用于整个NumPy决定如何处理不同形状的数组;例如,在ndarrays之间的所有算术运算(+,-,*,...)操作前。
如果上述规则产生有效的结果,即,下列之一为真,则将一组数组称为“可广播
- 数组都有完全相同的形状。
- 数组都具有相同的维数,每个维的长度为公共长度或1。
- 具有太少维度的数组可以使用长度为1的维度来预置其形状,以满足属性2。
例
If a.shape is (5,1), b.shape is (1,6), c.shape is (6,) and d.shape is () so that d is a scalar, then a, b, c, and d are all broadcastable to dimension (5,6); and
- a类似于(5,6)数组,其中
a[:,0]广播到其他列, - b就像一个(5,6)数组,其中
b[0,:]广播到其他行, - c类似于(1,6)数组并因此像(5,6)数组,其中
c[:]广播到每一行, - d类似于(5,6)数组,其中重复单个值。
Output type determination¶
如果所有输入参数不是ndarrays,ufunc(及其方法)的输出不一定是ndarray。
所有输出数组将被传递到定义其的输入(除了ndarrays和标量)的__array_prepare__和__array_wrap__ 具有通用函数的任何其他输入中最高的__array_priority__。ndarray的默认__array_priority__为0.0,子类型的默认__array_priority__为1.0。矩阵具有等于10.0的__array_priority__。
所有ufuncs也可以接受输出参数。如有必要,输出将被转换为所提供的输出数组的数据类型。如果将具有__array__方法的类用于输出,结果将写入由__array__返回的对象。然后,如果类也有一个__array_prepare__方法,则它被调用,因此元数据可以基于ufunc的上下文来确定(上下文由ufunc本身,传递给ufunc的参数, ufunc域。)由__array_prepare__返回的数组对象被传递到ufunc以进行计算。最后,如果类还有一个__array_wrap__方法,返回的ndarray结果将在传递控制权之前传递给调用者。
Use of internal buffers¶
在内部,缓冲区用于未对齐数据,交换数据和必须从一种数据类型转换为另一种数据类型的数据。内部缓冲区的大小可以基于每个线程设置。可以最多创建指定大小的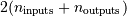 缓冲区,以处理来自ufunc的所有输入和输出的数据。缓冲区的默认大小为10,000个元素。每当需要基于缓冲区的计算,但是所有输入数组都小于缓冲区大小时,那些错误行为或不正确类型的数组将在计算进行之前被复制。因此,调整缓冲器的大小可以改变各种类型的ufunc计算完成的速度。可以使用该函数访问用于设置此变量的简单界面
缓冲区,以处理来自ufunc的所有输入和输出的数据。缓冲区的默认大小为10,000个元素。每当需要基于缓冲区的计算,但是所有输入数组都小于缓冲区大小时,那些错误行为或不正确类型的数组将在计算进行之前被复制。因此,调整缓冲器的大小可以改变各种类型的ufunc计算完成的速度。可以使用该函数访问用于设置此变量的简单界面
setbufsize(size) |
设置ufuncs中使用的缓冲区的大小。 |
Error handling¶
通用函数可以跳过硬件中的特殊浮点状态寄存器(如除以零)。如果在您的平台上可用,在计算期间将定期检查这些寄存器。错误处理是基于每个线程控制的,并且可以使用函数进行配置
seterr([all,divide,over,under,invalid]) |
设置如何处理浮点错误。 |
seterrcall(func) |
设置浮点错误回调函数或日志对象。 |
Casting Rules¶
注意
在NumPy 1.6.0中,创建了一个类型提升API来封装机制以确定输出类型。See the functions result_type, promote_types, and min_scalar_type for more details.
每个ufunc的核心是一个一维stride循环,实现特定类型组合的实际功能。当创建一个ufunc时,会给出一个内部循环的静态列表,以及ufunc操作的类型签名的相应列表。ufunc机制使用此列表来确定对于特定情况使用哪个内循环。您可以检查特定ufunc的.types属性,以查看哪些类型组合具有定义的内部循环,以及它们产生的输出类型(character codes用于所述输出简明)。
当ufunc没有提供的输入类型的核心循环实现时,必须在一个或多个输入上进行转换。如果不能找到输入类型的实现,则算法搜索具有类型签名的实现,其中所有输入可以“安全地”投射到该类型签名。在其内部循环列表中找到的第一个选择并执行,经过所有必要的型铸造。回想一下,在ufuncs(甚至是转换)期间的内部副本被限制为内部缓冲区(用户可设置)的大小。
注意
NumPy中的通用函数足够灵活,具有混合类型签名。因此,例如,可以定义与浮点和整数值一起工作的通用函数。有关示例,请参见ldexp。
通过上述描述,投射规则基本上通过何时可以将数据类型“安全地”投射到另一数据类型的问题来实现。这个问题的答案可以在Python中用函数调用:can_cast(fromtype, totype)确定。下图显示了对作者64位系统上的24种内部支持类型的调用结果。你可以使用图中给出的代码为你的系统生成这个表。
数字
代码段,显示32位系统的“可以安全转换”表。
>>> def print_table(ntypes):
... print 'X',
... for char in ntypes: print char,
... print
... for row in ntypes:
... print row,
... for col in ntypes:
... print int(np.can_cast(row, col)),
... print
>>> print_table(np.typecodes['All'])
X ? b h i l q p B H I L Q P e f d g F D G S U V O M m
? 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
b 0 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0
h 0 0 1 1 1 1 1 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0
i 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 1 1 0 1 1 1 1 1 1 0 0
l 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 1 0 1 1 1 1 1 1 0 0
q 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 1 0 1 1 1 1 1 1 0 0
p 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 1 0 1 1 1 1 1 1 0 0
B 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
H 0 0 0 1 1 1 1 0 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 0 0
I 0 0 0 0 1 1 1 0 0 1 1 1 1 0 0 1 1 0 1 1 1 1 1 1 0 0
L 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 1 1 0 1 1 1 1 1 1 0 0
Q 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 1 1 0 1 1 1 1 1 1 0 0
P 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 1 1 0 1 1 1 1 1 1 0 0
e 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0
f 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0
d 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 1 1 1 1 0 0
g 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 1 1 1 0 0
F 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0
D 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0
G 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 0 0
S 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0
U 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0
V 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0
O 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0
M 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
m 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
你应该注意,虽然包含在表中的完整性,'S','U'和'V'类型不能由ufuncs操作。另外,请注意,在32位系统上,整数类型可能有不同的大小,导致一个稍微更改的表。
混合标量数组操作使用一组不同的转换规则,确保标量不能“上转换”数组,除非标量是基本不同类型的数据(,),在数据类型层次结构)。此规则允许您在代码中使用标量常量(作为Python类型,在ufuncs中进行相应解释),而不必担心标量常量的精度是否会导致大型(小精度)数组上的转换。
Overriding Ufunc behavior¶
类(包括ndarray子类)可以通过定义某些特殊方法来覆盖ufuncs对它们的作用。有关详细信息,请参见Standard array subclasses。
ufunc¶
Optional keyword arguments¶
所有ufuncs接受可选的关键字参数。其中大多数代表高级使用,通常不会使用。
out
版本1.6中的新功能。
第一个输出可以作为位置参数或关键字参数提供。关键字'out'参数与位置不匹配。
..versionadded :: 1.10
'out'关键字参数应该是一个元组,每个输出有一个条目(可以None用于由ufunc分配数组)。对于具有单个输出的ufunc,传递单个数组(而不是保存单个数组的元组)也是有效的。
将“out”关键字参数中的单个数组传递给具有多个输出的ufunc已弃用,并将在numpy 1.10中引发警告,并在将来的版本中引发错误。
其中
版本1.7中的新功能。
值True表示计算该位置处的ufunc,值False表示将值留在输出中。
铸造
版本1.6中的新功能。
可能是“不”,“等价”,“安全”,“same_kind”或“不安全”。有关参数值的说明,请参见
can_cast。提供允许使用何种类型的投射的政策。为了与以前版本的NumPy兼容,这对numpy默认为“不安全”在numpy 1.7中,开始到'same_kind'的转换,其中ufuncs为“不安全”规则允许的调用产生DeprecationWarning,但不在“same_kind”规则下。从numpy 1.10开始,默认值为“same_kind”。
订单
版本1.6中的新功能。
指定输出数组的计算迭代顺序/内存布局。默认为'K'。'C'表示输出应为C连续,'F'表示F连续,'A'表示F连续,如果输入是F连续的,而不是也不是C连续的,否则为C连续, '意味着尽可能接近地匹配输入的元素排序。
dtype
版本1.6中的新功能。
覆盖计算的dtype并输出数组。类似于签名。
subok
版本1.6中的新功能。
默认为true。如果设置为false,则输出将始终为严格数组,而不是子类型。
签名
数据类型,数据类型的元组或指示ufunc的输入和输出类型的特殊签名字符串。此参数允许您为1-d循环提供特定签名,以在基础计算中使用。如果为ufunc指定的循环不存在,则会引发TypeError。通常,通过将输入类型与可用的类型进行比较并搜索具有可以安全地投放所有输入的数据类型的循环,来自动地找到合适的循环。这个关键字参数让你绕过搜索并选择一个特定的循环。可用签名的列表由ufunc对象的types属性提供。对于向后兼容性,这个参数也可以被提供为sig,尽管长格式是首选。
extobj
长度为1,2或3的列表,指定ufunc缓冲区大小,错误模式整数和错误回调函数。通常,这些值在线程特定的字典中查找。在这里传递它们绕过了查找并使用为错误模式提供的低级规范。这可能是有用的,例如,作为需要在循环中的小数组上的许多ufunc调用的计算的优化。
Attributes¶
有一些通用函数拥有的信息属性。不能设置任何属性。
| __ doc __ | 每个ufunc的docstring。docstring的第一部分是从输出的数量,名称和输入的数量动态生成的。docstring的第二部分在创建时提供,并与ufunc一起存储。 |
| __ name __ | ufunc的名称。 |
ufunc.nin |
输入数量。 |
ufunc.nout |
输出数量。 |
ufunc.nargs |
参数的数量。 |
ufunc.ntypes |
类型的数量。 |
ufunc.types |
返回一个类型为input-> output的列表。 |
ufunc.identity |
身份值。 |
Methods¶
所有ufuncs有四个方法。然而,这些方法只对接受两个输入参数并返回一个输出参数的ufunc有意义。尝试在其他ufuncs上调用这些方法将导致ValueError。reduce-like方法都采用轴关键字和dtype关键字,并且数组必须都具有dimension> = 1。axis关键字指定要在其上进行缩减的数组的轴,并且可以为负数,但必须为整数。dtype关键字允许你使用{op} .reduce来处理一个非常常见的问题。有时候,你可能有一个数据类型的数组,并希望将其所有元素相加,但结果不适合数组的数据类型。如果你有一个单字节整数的数组,这通常发生。dtype关键字允许您更改发生缩减的数据类型(因此也改变输出的类型)。因此,你可以确保输出是一个精度足够大的数据类型来处理你的输出。改变reduce类型的责任主要取决于你。有一个例外:如果没有对“add”或“multiply”操作的减少给出dtype,那么如果输入类型是整数(或布尔)数据类型,大小的int_数据类型,它将在内部向上转换到int_(或uint)数据类型。
Ufuncs还有第五种方法,允许使用花样索引执行原位操作。在使用花式索引的维度上不使用缓冲,因此花式索引可以多次列出项目,并且将对该项目的上一个操作的结果执行操作。
ufunc.reduce(a [,axis,dtype,out,keepdims]) |
通过沿一个轴应用ufunc,将a的尺寸减少一。 |
ufunc.accumulate(array [,axis,dtype,out]) |
累加将运算符应用于所有元素的结果。 |
ufunc.reduceat(a,indices [,axis,dtype,out]) |
使用单个轴上的指定切片执行(局部)缩减。 |
ufunc.outer(A,B) |
将ufunc op应用于所有对(a,b),其中a在A和b在B。 |
ufunc.at(a,indices [,b]) |
对由'indices'指定的元素,对操作数'a'执行无缓冲的就地操作。 |
警告
对具有“太小”范围以处理结果的数据类型的数组的类似于reduce的操作将静默换行。应该使用dtype来增加发生减少的数据类型的大小。
Available ufuncs¶
目前在numpy中定义了一种或多种类型的超过60个通用函数,涵盖各种各样的操作。Some of these ufuncs are called automatically on arrays when the relevant infix notation is used (e.g., add(a, b) is called internally when a + b is written and a or b is an ndarray). 然而,你可能仍然想要使用ufunc调用,以便使用可选的输出参数将输出放置在所选择的对象中。
回想一下每个ufunc操作一个元素一个元素。因此,每个ufunc将被描述为如果作用于一组标量输入以返回一组标量输出。
注意
即使你使用可选的输出参数,ufunc仍然返回它的输出。
Math operations¶
add(x1,x2 [,out]) |
按元素添加参数。 |
subtract(x1,x2 [,out]) |
按元素方式减去参数。 |
multiply(x1,x2 [,out]) |
逐元素乘法参数。 |
divide(x1,x2 [,out]) |
逐元素分割参数。 |
logaddexp(x1,x2 [,out]) |
输入的求和的对数。 |
logaddexp2(x1,x2 [,out]) |
以2为底的输入的乘方和的对数。 |
true_divide(x1,x2 [,out]) |
按元素方式返回输入的真正除法。 |
floor_divide(x1,x2 [,out]) |
返回小于或等于输入的除法的最大整数。 |
negative(x [,out]) |
数值负,元素。 |
power(x1,x2 [,out]) |
第一个数组元素从第二个数组提升到权力,逐元素。 |
remainder(x1,x2 [,out]) |
返回元素的除法余数。 |
mod(x1,x2 [,out]) |
返回元素的除法余数。 |
fmod(x1,x2 [,out]) |
返回除法的元素余项。 |
absolute(x [,out]) |
逐个计算绝对值。 |
fabs(x [,out]) |
按元素计算绝对值。 |
rint(x [,out]) |
数组的圆形元素到最接近的整数。 |
sign(x [,out]) |
返回数字符号的逐元素指示。 |
conj(x [,out]) |
按元素方式返回复共轭。 |
exp(x [,out]) |
计算输入数组中所有元素的指数。 |
exp2(x [,out]) |
对于输入数组中的所有p,计算2 ** p。 |
log(x [,out]) |
自然对数,逐元素。 |
log2(x [,out]) |
x的基础2对数。 |
log10(x [,out]) |
以元素为单位返回输入数组的基数10的对数。 |
expm1(x [,out]) |
对数组中的所有元素计算exp(x) - 1 |
log1p(x [,out]) |
返回一个加自然对数的输入数组,元素。 |
sqrt(x [,out]) |
按元素方式返回数组的正平方根。 |
square(x [,out]) |
返回输入的元素平方。 |
cbrt(x [,out]) |
以元素方式返回数组的多维数据集根。 |
reciprocal(x [,out]) |
元素方式返回参数的倒数。 |
小费
可选输出参数可用于帮助您节省大型计算的内存。如果您的数组大,复杂的表达式可能需要更长的时间,由于创建和(以后)销毁临时计算空间绝对必要。例如,表达式G = a * b + c等效于t1 = A * B; G = T1 + C; del t1。将更快地执行为G = A * B; t5 >与G相同的添加(G, C, G) = A * B; G + = C。
Trigonometric functions¶
所有三角函数在调用角度时使用弧度。度数与弧度的比率为
sin(x [,out]) |
三角正弦,元素。 |
cos(x [,out]) |
元素方面。 |
tan(x [,out]) |
逐元素计算切线。 |
arcsin(x [,out]) |
反正弦,元素。 |
arccos(x [,out]) |
三角反余弦,元素方式。 |
arctan(x [,out]) |
三角反正切,元素。 |
arctan2(x1,x2 [,out]) |
x1/x2的元素平方倒圆切线正确选择象限。 |
hypot(x1,x2 [,out]) |
给定直角三角形的“腿”,返回其斜边。 |
sinh(x [,out]) |
双曲正弦,元素。 |
cosh(x [,out]) |
双曲余弦,元素。 |
tanh |
逐元素计算双曲正切。 |
arcsinh(x [,out]) |
逆双曲正弦元。 |
arccosh(x [,out]) |
逆双曲余弦,元素方式。 |
arctanh(x [,out]) |
逆双曲正切元素。 |
deg2rad(x [,out]) |
将角度从度转换为弧度。 |
rad2deg(x [,out]) |
将角度从弧度转换为度。 |
Bit-twiddling functions¶
这些函数都需要整数参数,并且它们操作这些参数的位模式。
bitwise_and(x1,x2 [,out]) |
计算元素方面的两个数组的逐位AND。 |
bitwise_or(x1,x2 [,out]) |
计算元素方面的两个数组的逐位OR。 |
bitwise_xor(x1,x2 [,out]) |
按元素方式计算两个数组的逐位异或。 |
invert(x [,out]) |
逐位计算逐位反转,或逐位非单元。 |
left_shift(x1,x2 [,out]) |
将整数的位向左移位。 |
right_shift(x1,x2 [,out]) |
将整数的位向右移位。 |
Comparison functions¶
greater(x1,x2 [,out]) |
逐元素地返回(x1> x2)的真值。 |
greater_equal(x1,x2 [,out]) |
逐元素地返回(x1> = x2)的真值。 |
less(x1,x2 [,out]) |
返回(x1的真值 |
less_equal(x1,x2 [,out]) |
返回(x1 =)的真值 |
not_equal(x1,x2 [,out]) |
元素方式返回(x1!= x2)。 |
equal(x1,x2 [,out]) |
元素方式返回(x1 == x2)。 |
警告
不要使用Python关键字and和or来组合逻辑数组表达式。这些关键字将测试整个数组的真值(不是逐个元素,你可能期望)。使用按位运算符&和|代替。
logical_and(x1,x2 [,out]) |
逐元素计算x1和x2的真值。 |
logical_or(x1,x2 [,out]) |
逐元素计算x1或x2的真值。 |
logical_xor(x1,x2 [,out]) |
按元素方式计算x1 XOR x2的真值。 |
logical_not(x [,out]) |
逐元素计算NOT x的真值。 |
警告
比特运算符&和|是执行逐个元素数组比较的正确方法。确保您理解运算符优先级:(a > 2) & (a 5)是正确的语法,因为a / t10> 2 & a 5导致由于首先评估2 & a的错误。
maximum(x1,x2 [,out]) |
数组元素的元素最大值。 |
小费
Python函数max()将找到一维数组的最大值,但它将使用较慢的序列接口。reduce方法的最大ufunc更快。此外,max()方法不会给出您可能期望具有大于一个维度的数组的答案。reduce的reduce方法还允许您计算数组上的总最小值。
minimum(x1,x2 [,out]) |
元素最小的数组元素。 |
警告
the behavior of maximum(a, b) is different than that of max(a, b). As a ufunc, maximum(a, b) performs an element-by-element comparison of a and b and chooses each element of the result according to which element in the two arrays is larger. 相反,max(a, b)处理对象a和b作为整体,查看a > b的(总)真值并使用它返回a或b(作为一个整体)。在最小(a, b)和min(a, b)。
fmax(x1,x2 [,out]) |
数组元素的元素最大值。 |
fmin(x1,x2 [,out]) |
元素最小的数组元素。 |
Floating functions¶
回想一下,所有这些函数在一个数组上逐个元素地工作,返回一个数组输出。描述仅详细说明一次操作。
isfinite(x [,out]) |
测试元素的有限性(不是无穷大或不是数字)。 |
isinf(x [,out]) |
对于正或负无穷大测试元素。 |
isnan(x [,out]) |
测试元素方面的NaN和返回结果作为一个布尔数组。 |
fabs(x [,out]) |
按元素计算绝对值。 |
signbit(x [,out]) |
以元素为单位返回True,其中signbit已设置(小于零)。 |
copysign(x1,x2 [,out]) |
按照元素方式将x1的符号更改为x2的符号。 |
nextafter(x1,x2 [,out]) |
将x1之后的下一个浮点值返回x2,逐个元素。 |
spacing(x [,out]) |
返回x和最近的相邻数字之间的距离。 |
modf(x [,out1,out2]) |
以元素方式返回数组的小数和整数部分。 |
ldexp(x1,x2 [,out]) |
元素方式返回x1 * 2 ** x2。 |
frexp(x [,out1,out2]) |
将x的元素分解为尾数和二进制指数。 |
fmod(x1,x2 [,out]) |
返回除法的元素余项。 |
floor(x [,out]) |
逐元素地返回输入的底。 |
ceil(x [,out]) |
元素方式返回输入的上限。 |
trunc(x [,out]) |
按元素方式返回输入的截断值。 |