Standard array subclasses¶
NumPy中的ndarray是一种“新式”Python内置类型。因此,如果需要,它可以继承(在Python或C中)。因此,它可以形成许多有用类的基础。通常是否将数组对象子类化或简单地使用核心数组组件作为新类的内部部分是一个困难的决定,可能只是一个选择。NumPy有几个工具可以简化新对象与其他数组对象的交互方式,所以选择结果可能不太重要。简化问题的一种方法是询问自己是否感兴趣的对象可以替换为单个数组,或者它的核心是真正需要两个或更多数组。
请注意,asarray总是返回基类ndarray。如果你确信你使用数组对象可以处理ndarray的任何子类,那么asanyarray可以用来允许子类在你的子程序中更干净地传播。原则上,子类可以重新定义数组的任何方面,因此,在严格的指导下,asanyarray很少有用。但是,数组对象的大多数子类将不会重新定义数组的某些方面,例如缓冲区接口或数组的属性。然而,一个重要的例子是,你的子程序可能无法处理数组的任意子类,因为矩阵将“*”运算符重新定义为矩阵乘法,而不是逐个元素乘法。
Special attributes and methods¶
也可以看看
NumPy提供了几个类可以自定义的钩子:
-
class.__numpy_ufunc__(ufunc, method, i, inputs, **kwargs)¶ 版本1.11中的新功能。
任何类(ndarray子类或不)可以定义此方法来覆盖NumPy的ufuncs的行为。这与Python的
__mul__和其他二进制操作例程非常相似。- ufunc是被调用的ufunc对象。
- method is a string indicating which Ufunc method was called (one of
"__call__","reduce","reduceat","accumulate","outer","inner"). - i是输入中self的索引。
- 输入是
ufunc的输入参数的元组, - kwargs是包含ufunc的可选输入参数的字典。如果给定,
out参数始终包含在kwargs中。有关详细信息,请参阅Universal functions (ufunc)中的讨论。
如果未执行所请求的操作,则该方法应返回操作结果,或
NotImplemented。If one of the arguments has a
__numpy_ufunc__method, it is executed instead of the ufunc. 如果多个输入参数实现了__numpy_ufunc__,则会按照以下顺序尝试:子类之前的父类,否则从左到右。返回NotImplemented以外的第一个例程确定结果。如果所有__numpy_ufunc__操作返回NotImplemented,则会引发TypeError。如果
ndarray子类定义__numpy_ufunc__方法,则禁用__array_wrap__,__array_prepare__,__array_priority__注意
除了ufuncs,
__numpy_ufunc__也会覆盖numpy.dot的行为,即使它不是Ufunc。注意
如果你还定义了类中的右边二元操作符覆盖方法(例如
__rmul__)或比较操作(例如__gt__),它们优先于__numpy_ufunc__机制在解析二进制运算结果(例如ndarray_obj * your_obj技术特殊情况是:
ndarray.__mul__如果另一个对象是而不是ndarray的子类,则返回NotImplemented并定义__numpy_ufunc__和__rmul__。类似的例外适用于除乘法之外的其他操作。In such a case, when computing a binary operation such as
ndarray_obj * your_obj, your__numpy_ufunc__method will not be called. 相反,执行会按照标准的Python操作符覆盖规则传递到右侧的__rmul__操作。类似的特殊情况适用于就地操作:如果您定义
__rmul__,则ndarray_obj * = your_obj不会呼叫您的__numpy_ufunc__实作。而是默认的Python行为ndarray_obj = ndarray_obj * your_obj 。注意上面的讨论仅适用于Python的内建二进制操作机制。
np.multiply(ndarray_obj, your_obj)总是只按照预期调用您的__numpy_ufunc__。
-
class.__array_finalize__(obj)¶ 每当系统在内部从obj分配一个新的数组,其中obj是
ndarray的子类它可以用于在构造之后改变self的属性(以便例如确保2-d矩阵),或者更新来自“父”的元信息。子类继承默认实现这个方法什么也不做。
-
class.__array_prepare__(array, context=None)¶ 在每个ufunc开始时,对具有最高数组优先级的输入对象或输出对象(如果指定了一个)调用此方法。输出数组被传入,并且返回的任何内容都传递给ufunc。子类继承此方法的默认实现,它只返回未修改的数组。子类可以选择使用此方法将输出数组转换为子类的实例,并在将数组返回到ufunc之前更新元数据以进行计算。
-
class.__array_wrap__(array, context=None)¶ 在每个ufunc结束时,对具有最高数组优先级的输入对象或输出对象(如果指定了一个)调用此方法。ufunc计算的数组被传入,并且返回的任何内容都传递给用户。子类继承此方法的默认实现,它将数组转换为对象类的新实例。子类可以选择使用此方法将输出数组转换为子类的实例,并在将数组返回给用户之前更新元数据。
-
class.__array_priority__¶ 此属性的值用于确定在返回对象的Python类型有多种可能性的情况下要返回的对象类型。子类继承此属性的默认值0.0。
Matrix objects¶
matrix对象继承自ndarray,因此,它们具有与ndarrays相同的属性和方法。但是,矩阵对象有六个重要的区别,当你使用矩阵时,可能会导致意想不到的结果,但是希望它们像数组一样工作:
Matrix对象可以使用字符串符号创建,以允许使用Matlab风格的语法,其中空格分隔列和分号(';')分隔行。
矩阵对象总是二维的。这具有深远的影响,因为m.ravel()仍然是二维的(在第一维中具有1),并且项选择返回二维对象,使得序列行为从根本上不同于数组。
矩阵对象覆盖乘法为矩阵乘法。确保你理解这个你可能想要接收矩阵的函数。特别是考虑到当m是矩阵时asanyarray(m)返回矩阵的事实。
矩阵对象覆盖功率以将矩阵提升到功率。关于在使用asanyarray(...)获取数组对象的函数内部使用权力的相同警告对于这个事实保持。
矩阵对象的默认__array_priority__是10.0,因此与ndarrays的混合运算总是产生矩阵。
矩阵具有使计算更容易的特殊属性。这些是
matrix.T返回矩阵的转置。 matrix.H返回self的(复数)共轭转置。 matrix.I返回可逆self的(乘法)逆。 matrix.A将self作为 ndarray对象返回。
警告
矩阵对象覆盖乘法,'*'和幂,'**'分别为矩阵乘法和矩阵功率。如果你的子程序可以接受子类并且你不转换为基类数组,那么你必须使用ufuncs乘法和幂来确保你对所有输入执行正确的操作。
矩阵类是ndarray的Python子类,可以用作如何构建自己的ndarray子类的参考。矩阵可以从其他矩阵,字符串和任何可以转换为ndarray的其他内容创建。名称“mat”是NumPy中“matrix”的别名。
matrix |
从数组类对象或数据字符串返回一个矩阵。 |
asmatrix(data [,dtype]) |
将输入解释为矩阵。 |
bmat(obj [,ldict,gdict]) |
从字符串,嵌套序列或数组构建一个矩阵对象。 |
示例1:从字符串创建矩阵
>>> a=mat('1 2 3; 4 5 3')
>>> print (a*a.T).I
[[ 0.2924 -0.1345]
[-0.1345 0.0819]]
示例2:从嵌套序列创建矩阵
>>> mat([[1,5,10],[1.0,3,4j]])
matrix([[ 1.+0.j, 5.+0.j, 10.+0.j],
[ 1.+0.j, 3.+0.j, 0.+4.j]])
示例3:从数组创建矩阵
>>> mat(random.rand(3,3)).T
matrix([[ 0.7699, 0.7922, 0.3294],
[ 0.2792, 0.0101, 0.9219],
[ 0.3398, 0.7571, 0.8197]])
Memory-mapped file arrays¶
内存映射文件对于以常规布局读取和/或修改大文件的小段很有用,无需将整个文件读入内存。ndarray的一个简单子类使用一个内存映射文件作为数组的数据缓冲区。对于小文件,将整个文件读入内存的开销通常不重要,但对于使用内存映射的大文件,可以节省大量资源。
内存映射文件数组有一个额外的方法(除了它们从ndarray继承):.flush()它必须由用户手动调用,以确保对数组的任何更改实际写入到磁盘。
memmap |
创建存储在磁盘上的二进制文件中的数组的内存映射。 |
memmap.flush() |
将数组中的任何更改写入磁盘上的文件。 |
例:
>>> a = memmap('newfile.dat', dtype=float, mode='w+', shape=1000)
>>> a[10] = 10.0
>>> a[30] = 30.0
>>> del a
>>> b = fromfile('newfile.dat', dtype=float)
>>> print b[10], b[30]
10.0 30.0
>>> a = memmap('newfile.dat', dtype=float)
>>> print a[10], a[30]
10.0 30.0
Character arrays (numpy.char)¶
注意
存在chararray类以向后兼容Numarray,因此不推荐用于新开发。Starting from numpy 1.4, if one needs arrays of strings, it is recommended to use arrays of dtype object_, string_ or unicode_, and use the free functions in the numpy.char module for fast vectorized string operations.
这些是string_类型或unicode_类型的增强数组。这些数组继承自ndarray,但特别定义了a()的+,*和%广播)。这些操作不适用于字符类型的标准ndarray。此外,chararray具有所有标准的string(和unicode)方法,在逐个元素的基础上执行它们。也许最简单的创建chararray的方法是使用self.view(chararray)其中self是str或unicode数据类型的ndarray。但是,也可以使用numpy.chararray构造函数或通过numpy.char.array函数创建chararray:
chararray |
提供了一个方便的查看数组的字符串和unicode值。 |
core.defchararray.array(obj [,itemsize,...]) |
创建chararray。 |
与str数据类型的标准ndarray的另一个区别是,chararray继承了Numarray引入的特性,即数组中任何元素末尾的白色空间将在项检索和比较操作中被忽略。
Record arrays (numpy.rec)¶
NumPy提供了允许访问作为属性的结构化数组的字段和对应的标量数据类型对象record的recarray类。
recarray |
构造一个允许使用属性进行字段访问的ndarray。 |
record |
允许字段访问作为属性查找的数据类型标量。 |
Masked arrays (numpy.ma)¶
也可以看看
Standard container class¶
为了向后兼容和作为标准的“容器”类,Numeric中的UserArray已经转换到NumPy并命名为numpy.lib.user_array.container容器类是一个Python类,其self.array属性是一个ndarray。使用numpy.lib.user_array.container比使用ndarray本身更容易多重继承,因此它默认包含在内。这里没有提到它的存在,因为你被鼓励直接使用ndarray类,如果你可以。
numpy.lib.user_array.container(data [,...]) |
用于容易多继承的标准容器类。 |
Array Iterators¶
迭代器是数组处理的强大概念。基本上,迭代器实现广义for循环。如果myiter是一个迭代器对象,那么Python代码:
for val in myiter:
...
some code involving val
...
重复调用val = myiter.next(),直到StopIteration迭代器。有几种方法可以在数组上进行迭代,这可能是有用的:默认迭代,平面迭代和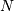 - 维度枚举。
- 维度枚举。
Default iteration¶
ndarray对象的默认迭代器是序列类型的默认Python迭代器。因此,当数组对象本身用作迭代器时。默认行为等效于:
for i in range(arr.shape[0]):
val = arr[i]
此默认迭代器从数组中选择维度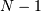 的子数组。这可以是定义递归算法的有用结构。要遍历整个数组,需要 for-loops。
的子数组。这可以是定义递归算法的有用结构。要遍历整个数组,需要 for-loops。
>>> a = arange(24).reshape(3,2,4)+10
>>> for val in a:
... print 'item:', val
item: [[10 11 12 13]
[14 15 16 17]]
item: [[18 19 20 21]
[22 23 24 25]]
item: [[26 27 28 29]
[30 31 32 33]]
Flat iteration¶
ndarray.flat |
数组上的1-D迭代器。 |
如前所述,ndarray对象的flat属性返回一个迭代器,它将以C样式连续顺序遍历整个数组。
>>> for i, val in enumerate(a.flat):
... if i%5 == 0: print i, val
0 10
5 15
10 20
15 25
20 30
在这里,我使用内置的枚举迭代器返回迭代器索引以及值。
N-dimensional enumeration¶
ndenumerate(arr) |
多维索引迭代器。 |
有时,在迭代时获得N维索引可能是有用的。ndenumerate迭代器可以实现这一点。
>>> for i, val in ndenumerate(a):
... if sum(i)%5 == 0: print i, val
(0, 0, 0) 10
(1, 1, 3) 25
(2, 0, 3) 29
(2, 1, 2) 32