N维数组(ndarray)¶
ndarray是(通常大小固定的)一个多维容器,由相同类型和大小的元素组成。数组中的维度和元素数量由其shape定义,它是由N个正整数组成的元组,每个整数指定每个维度的大小。数组中元素的类型由单独的数据类型对象 (dtype)指定,每个ndarray与其中一个对象相关联。
与Python中的其他容器对象一样,ndarray的内容可以通过索引或切片(例如使用N个整数)、以及ndarray的方法和属性访问和修改数组。
不同的ndarrays可以共享相同的数据,使得在一个ndarray中进行的改变在另一个中可见。也就是说,ndarray可以是到另一个ndarray的“view”,并且其引用的数据由“base” ndarray处理。ndarrays还可以是由Python strings或实现buffer或array接口的对象拥有的内存的视图。
例
尺寸为2×3的二维数组,由4字节整数元素组成:
>>> x = np.array([[1, 2, 3], [4, 5, 6]], np.int32)
>>> type(x)
<type 'numpy.ndarray'>
>>> x.shape
(2, 3)
>>> x.dtype
dtype('int32')
数组可以使用类似Python容器的语法进行索引:
>>> # The element of x in the *second* row, *third* column, namely, 6.
>>> x[1, 2]
例如,切片可以生成数组的视图:
>>> y = x[:,1]
>>> y
array([2, 5])
>>> y[0] = 9 # this also changes the corresponding element in x
>>> y
array([9, 5])
>>> x
array([[1, 9, 3],
[4, 5, 6]])
ndarray的内存布局¶
类ndarray的实例由计算机存储器的一维连续段(由该数组、或一些其他对象拥有)组成,结合索引方案映射N个整数为块中元素的位置。索引可以变化的范围由数组的shape指定。每个元素占用多少字节以及如何解释字节由与数组相关联的数据类型对象定义。
存储器段本质上是1维的,并且将N维数组的元素组织为1维的内存块有许多不同方案。NumPy是灵活的,ndarray对象可以适应任何strided索引方案。在一个strided方案中,N维索引 对应于偏移量(以字节为单位):
对应于偏移量(以字节为单位):
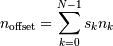
从与数组相关联的存储器块的开始。这里,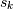 是指定数组的
是指定数组的strides的整数。column-major顺序(例如在Fortran语言和Matlab中使用)和row-major方案仅仅是特定种类的跨距方案,并且对应于可以通过步幅寻址的存储器:
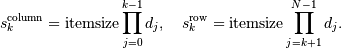
其中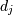 = self.shape [j]。
= self.shape [j]。
C和Fortran顺序都是contiguous,即 单段的存储器布局,其中可以访问存储器块的每个部分通过指数的一些组合。
虽然具有相应标志设置的C风格和Fortran风格的连续数组可以用上述步幅来解决,但实际的步幅可能不同。这可能发生在两种情况下:
- 如果
self.shape [k] == 1,则对于任何法定索引[k] == 0。这意味着在偏移的公式中,因此
和
- 如果数组没有元素(
self.size == 0),则没有法律索引和步长从不使用。任何没有元素的数组都可以被认为是C风格和Fortran风格的连续。
点1.意味着self和self.squeeze()始终具有相同的邻接和对齐标志值。这也意味着,即使一个高维的数组可以是C风格和Fortran风格的连续的同时。
如果所有元素的内存偏移和基本偏移本身是self.itemsize的倍数,则认为数组是对齐的。
注意
默认情况下,点(1)和(2)尚未应用。从NumPy 1.8.0开始,只有在构建NumPy时定义了环境变量NPY_RELAXED_STRIDES_CHECKING=1,它们才会一致应用。最终这将成为默认值。
你可以通过查看np.ones((10,1), order ='C')的值建立NumPy时是否启用此选项。flags .f_contiguous。如果这是True,则您的NumPy已启用宽松检查。
警告
不一般认为self.strides [-1] == self.itemsize / t1>用于C型连续数组或self.strides [0] == self.itemsize Fortran风格的连续数组是真的。
除非另有规定,否则新ndarrays中的数据处于row-major(C)顺序,但是例如basic array slicing views。
注意
NumPy中的几个算法可以处理任意跨度的数组。然而,一些算法需要单段数组。当将不规则跨度的数组传递到这样的算法中时,自动地进行复制。
Array attributes¶
数组属性反映数组本身固有的信息。通常,通过其属性访问数组允许您获取并有时设置数组的固有属性,而不创建新的数组。暴露的属性是数组的核心部分,只有其中的一些可以有意义地重置,而不创建新的数组。下面给出每个属性的信息。
Memory layout¶
以下属性包含有关数组的内存布局的信息:
ndarray.flags |
有关数组的内存布局的信息。 |
ndarray.shape |
数组维数组。 |
ndarray.strides |
遍历数组时,在每个维度中步进的字节数组。 |
ndarray.ndim |
数组维数。 |
ndarray.data |
Python缓冲区对象指向数组的数据的开始。 |
ndarray.size |
数组中的元素数。 |
ndarray.itemsize |
一个数组元素的长度(以字节为单位)。 |
ndarray.nbytes |
数组的元素消耗的总字节数。 |
ndarray.base |
如果内存是来自某个其他对象的基本对象。 |
Other attributes¶
ndarray.T |
与self.transpose()相同,除非self是self.ndim返回 |
ndarray.real |
数组的真实部分。 |
ndarray.imag |
数组的虚部。 |
ndarray.flat |
数组上的1-D迭代器。 |
ndarray.ctypes |
一个对象,用于简化数组与ctypes模块的交互。 |
ctypes foreign function interface¶
ndarray.ctypes |
一个对象,用于简化数组与ctypes模块的交互。 |
Array methods¶
ndarray对象有许多以某种方式对数组进行操作的方法,通常返回数组结果。下面简要解释这些方法。(每个方法的docstring有一个更完整的描述。)
For the following methods there are also corresponding functions in numpy: all, any, argmax, argmin, argpartition, argsort, choose, clip, compress, copy, cumprod, cumsum, diagonal, imag, max, mean, min, nonzero, partition, prod, ptp, put, ravel, real, repeat, reshape, round, searchsorted, sort, squeeze, std, sum, swapaxes, take, trace, transpose, var.
Array conversion¶
ndarray.item(\ * args) |
提取数组中的元素 |
ndarray.tolist() |
将数组返回为(可能是嵌套的)列表。 |
ndarray.itemset(\ * args) |
在指定位置插入标量值(修改原始数组) |
ndarray.tostring([order]) |
在数组中构造包含原始数据字节的Python字节。 |
ndarray.tobytes([order]) |
在数组中构造包含原始数据字节的Python字节。 |
ndarray.tofile(fid [,sep,format]) |
将数组作为文本或二进制(默认)写入文件。 |
ndarray.dump(file) |
将数组的pickle转储到指定的文件。 |
ndarray.dumps() |
以字符串形式返回数组的pickle。 |
ndarray.astype(dtype [,order,casting,...]) |
数组的复制,强制转换为指定的类型。 |
ndarray.byteswap(inplace) |
交换数组元素的字节 |
ndarray.copy([order]) |
返回数组的副本。 |
ndarray.view([dtype,type]) |
数组的新视图与相同的数据。 |
ndarray.getfield(dtype [,offset]) |
将给定数组的字段返回为特定类型。 |
ndarray.setflags([write,align,uic]) |
分别设置数组标志WRITEABLE,ALIGNED和UPDATEIFCOPY。 |
ndarray.fill(value) |
使用标量值填充数组。 |
Shape manipulation¶
对于重塑,调整大小和转置,单个元组参数可以替换为n整数,这将被解释为n元组。
ndarray.reshape(shape [,order]) |
返回包含具有新形状的相同数据的数组。 |
ndarray.resize(new_shape [,refcheck]) |
就地更改数组的形状和大小。 |
ndarray.transpose(\ * axes) |
返回具有轴转置的数组的视图。 |
ndarray.swapaxes(axis1,axis2) |
返回数组的视图,其中axis1和axis2互换。 |
ndarray.flatten([order]) |
将折叠的数组的副本返回到一个维度。 |
ndarray.ravel([order]) |
返回展平的数组。 |
ndarray.squeeze([axis]) |
从a形状删除单维条目。 |
Item selection and manipulation¶
对于采用轴关键字的数组方法,默认为None。如果axis None,则数组被视为1-D数组。axis的任何其他值表示操作应沿其进行的维度。
ndarray.take(indices [,axis,out,mode]) |
返回由给定索引处的a元素组成的数组。 |
ndarray.put(indices,values [,mode]) |
对于所有n,设置a.flat [n] = 在指数。 |
ndarray.repeat(repeat[,axis]) |
重复数组的元素。 |
ndarray.choose(choices [,out,mode]) |
使用索引数组从一组选择中构造新的数组。 |
ndarray.sort([axis,kind,order]) |
就地对数组进行排序。 |
ndarray.argsort([axis,kind,order]) |
返回将此数组排序的索引。 |
ndarray.partition(kth [,axis,kind,order]) |
重新排列数组中的元素,使得第k个位置的元素的值在排序数组中的位置。 |
ndarray.argpartition(kth [,axis,kind,order]) |
返回将对此数组进行分区的索引。 |
ndarray.searchsorted(v [,side,sorter]) |
查找索引,其中v的元素应插入到a以维持顺序。 |
ndarray.nonzero() |
返回非零元素的索引。 |
ndarray.compress(condition [,axis,out]) |
沿给定轴返回此数组的所选切片。 |
ndarray.diagonal([offset,axis1,axis2]) |
返回指定的对角线。 |
Calculation¶
这些方法中的许多采用名为axis的参数。在这种情况下,
- 如果axis为None(默认值),则将数组视为1-D数组,并对整个数组执行该操作。如果self是一个0维数组或数组标量,这个行为也是默认的。(数组标量是类型/类float32,float64等的实例,而0维数组是一个包含正好一个数组标量的ndarray实例。
- 如果axis是整数,则在给定轴上进行该操作(对于可以沿给定轴创建的每个1-D子阵列)。
轴参数示例
尺寸为3×3×3的三维数组,在其三个轴中的每一个上求和
>>> x
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
>>> x.sum(axis=0)
array([[27, 30, 33],
[36, 39, 42],
[45, 48, 51]])
>>> # for sum, axis is the first keyword, so we may omit it,
>>> # specifying only its value
>>> x.sum(0), x.sum(1), x.sum(2)
(array([[27, 30, 33],
[36, 39, 42],
[45, 48, 51]]),
array([[ 9, 12, 15],
[36, 39, 42],
[63, 66, 69]]),
array([[ 3, 12, 21],
[30, 39, 48],
[57, 66, 75]]))
参数dtype指定应进行归约运算(如求和)的数据类型。默认减少数据类型与self的数据类型相同。为了避免溢出,使用较大的数据类型执行减少是有用的。
对于多个方法,还可以提供可选的out参数,结果将放置到给定的输出数组中。out参数必须是ndarray,并且具有相同数量的元素。它可以具有不同的数据类型,在这种情况下将执行转换。
ndarray.argmax([axis,out]) |
沿给定轴的最大值的返回指数。 |
ndarray.min([axis,out,keepdims]) |
沿给定轴返回最小值。 |
ndarray.argmin([axis,out]) |
沿着a的给定轴的最小值的返回指数。 |
ndarray.ptp([axis,out]) |
沿给定轴的峰到峰(最大 - 最小)值。 |
ndarray.clip([min,max,out]) |
返回值限于[min, max]的数组。 |
ndarray.conj() |
复共轭所有元素。 |
ndarray.round([decimals,out]) |
返回a,每个元素四舍五入为给定的小数位数。 |
ndarray.trace([offset,axis1,axis2,dtype,out]) |
沿数组的对角线返回总和。 |
ndarray.sum([axis,dtype,out,keepdims]) |
返回给定轴上的数组元素的总和。 |
ndarray.cumsum([axis,dtype,out]) |
返回沿给定轴的元素的累积和。 |
ndarray.mean([axis,dtype,out,keepdims]) |
返回沿给定轴的数组元素的平均值。 |
ndarray.var([axis,dtype,out,ddof,keepdims]) |
沿给定轴返回数组元素的方差。 |
ndarray.std([axis,dtype,out,ddof,keepdims]) |
返回给定轴上的数组元素的标准偏差。 |
ndarray.prod([axis,dtype,out,keepdims]) |
返回给定轴上的数组元素的乘积 |
ndarray.cumprod([axis,dtype,out]) |
返回沿给定轴的元素的累积乘积。 |
ndarray.all([axis,out,keepdims]) |
如果所有元素均为True,则返回True。 |
ndarray.any([axis,out,keepdims]) |
如果a的任何元素求值为True,则返回True。 |
Arithmetic, matrix multiplication, and comparison operations¶
对ndarrays的算术和比较操作被定义为逐元素操作,并且通常产生ndarray对象作为结果。
Each of the arithmetic operations (+, -, *, /, //, %, divmod(), ** or pow(), <<, >>, &, ^, |, ~) and the comparisons (==, <, >, <=, >=, !=) is equivalent to the corresponding universal function (or ufunc for short) in NumPy. 有关详细信息,请参阅Universal Functions部分。
比较运算符:
ndarray.__lt__ |
x.__lt__(y) <==> x |
ndarray.__le__ |
x。_ le __(y)x |
ndarray.__gt__ |
x .__ gt__(y)x> y |
ndarray.__ge__ |
x ._ge__(y)x> = y |
ndarray.__eq__ |
x .__ eq __(y)x == y |
ndarray.__ne__ |
x .__ ne __(y)x!= y |
数组的真值(bool):
ndarray.__nonzero__ |
x .__ nonzero __()x!= 0 |
注意
数组的真值测试调用ndarray.__nonzero__,如果数组中的元素数大于1,则会引发错误,因为此数组的真值是不确定的。使用.any()和.all()来清楚这些情况下的含义。(如果元素数为0,则数组的计算结果为False。)
一元操作:
ndarray.__neg__ |
x .__ neg __()-x |
ndarray.__pos__ |
x .__ pos __()+ x |
ndarray.__abs__()abs(x) |
|
ndarray.__invert__ |
x .__反转__()〜x |
算术:
ndarray.__add__ |
x .__ add __(y)x + y |
ndarray.__sub__ |
x .__ sub __(y)x-y |
ndarray.__mul__ |
x。_ mul __(y)x * y |
ndarray.__div__ |
x .__ div __(y)x / y |
ndarray.__truediv__ |
x。_ truediv __(y)x / y |
ndarray.__floordiv__ |
x .__ floordiv __(y)x // y |
ndarray.__mod__ |
x .__ mod __(y)x%y |
ndarray.__divmod__(y)divmod(x,y) |
|
ndarray.__pow__(y [,z])pow(x,y [,z]) |
|
ndarray.__lshift__ |
x .__ lshift __(y)x |
ndarray.__rshift__ |
x .__ rshift__(y)x >> y |
ndarray.__and__ |
x。和__(y)x&y |
ndarray.__or__ |
x .__或__(y)x | y |
ndarray.__xor__ |
x .__ xor __(y)x ^ y |
注意
pow的任何第三个参数被默认忽略,因为底层的ufunc只有两个参数。- 三个分区运算符都被定义;
div在默认情况下处于活动状态,truediv在__future__ - 因为
ndarray是内置类型(用C编写),所以不直接定义__r{op}__特殊方法。 - 可以使用
set_numeric_ops修改用于实现数组的许多算术特殊方法的函数。
算术,就地:
ndarray.__iadd__ |
x .__ iadd __(y)x + = y |
ndarray.__isub__ |
x .__ isub __(y)x- = y |
ndarray.__imul__ |
x .__ imul __(y)x * = y |
ndarray.__idiv__ |
x。_ idiv __(y)x / = y |
ndarray.__itruediv__ |
x .__ itruediv __(y)x / = y |
ndarray.__ifloordiv__ |
x ._ ifloordiv __(y)x // = y |
ndarray.__imod__ |
x。_ imod __(y)x%= y |
ndarray.__ipow__ |
x。_ ipow __(y)x ** = y |
ndarray.__ilshift__ |
x .__ ilshift __(y)x |
ndarray.__irshift__ |
x .__ irshift __(y)x >> = y |
ndarray.__iand__ |
x .__ iand __(y)x&= y |
ndarray.__ior__ |
x .__ ior __(y)x | = y |
ndarray.__ixor__ |
x。_ ixor __(y)x ^ = y |
警告
就地操作将使用由两个操作数的数据类型确定的精度来执行计算,但是将静默地对结果进行向下转换(如果必要的话),以便它可以适应数组。因此,对于混合精度计算,A {op} = B可以不同于 A = A {op} B。例如,假设a = ones((3,3))。Then, a += 3j is different than a = a + 3j: while they both perform the same computation, a += 3 casts the result to fit back in a, whereas a = a + 3j re-binds the name a to the result.
矩阵乘法:
ndarray.__matmul__ |
注意
在PEP465之后的Python 3.5中引入了矩阵运算符@和@=。NumPy 1.10.0具有用于测试目的的@的初步实现。更多文档可以在matmul文档中找到。
Special methods¶
对于标准库函数:
ndarray.__copy__([order]) |
返回数组的副本。 |
ndarray.__deepcopy__(() - >数组的深度副本。) |
在数组上调用copy.deepcopy时使用。 |
ndarray.__reduce__() |
酸洗。 |
ndarray.__setstate__(version,shape,dtype,...) |
用于取出。 |
基本定制:
ndarray.__new__((S,...) |
|
ndarray.__array__(...) |
如果未指定dtype,则返回对self的新引用,如果dtype与数组的当前dtype不同,则返回提供的数据类型的新数组。 |
ndarray.__array_wrap__(...) |
容器自定义:(参见Indexing)
ndarray.__len__()len(x) |
|
ndarray.__getitem__ |
x .__ getitem __(y)x [y] |
ndarray.__setitem__ |
x .__ setitem __(i,y)x [i] = y |
ndarray.__contains__ |
x .__在x中包含__(y)y |
转换;操作complex,int,long,float,oct和hex。它们只对具有一个元素的数组工作,并返回相应的标量。
ndarray.__int__()int(x) |
|
ndarray.__long__()long(x) |
|
ndarray.__float__()float(x) |
|
ndarray.__oct__()oct(x) |
|
ndarray.__hex__()hex(x) |
字符串表示:
ndarray.__str__()str(x) |
|
ndarray.__repr__()repr(x) |