Indexing¶
ndarrays可以使用标准Python x[obj]语法建立索引,其中x是数组和obj选择。有三种索引可用:字段访问,基本分片,高级索引。哪一个发生取决于obj。
注意
在Python中,x [(exp1, exp2, ..., expN)] t0>等效于x [exp1, exp2, ..., expN] t5>;后者只是前者的语法糖。
Basic Slicing and Indexing¶
基本切片将Python的切片基本概念扩展到N维。当obj是slice对象(由括号内的start:stop:step符号构造),整数或元组切片对象和整数。Ellipsis和newaxis对象也可以与这些对象穿插。为了保持与数字中的通用用法向后兼容,如果选择对象是包含slice的任何非ndarray序列(例如list),对象,Ellipsis对象或newaxis对象,但不适用于整数数组或其他嵌入序列。
使用N整数索引的最简单的情况返回表示相应项的array scalar。在Python中,所有索引都是从零开始的:对于i索引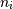 ,有效范围是
,有效范围是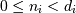 ,其中
,其中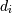 是数组的形状的第t个元素。负指数被解释为从数组结束计数(,即,如果
是数组的形状的第t个元素。负指数被解释为从数组结束计数(,即,如果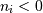 ,则意味着
,则意味着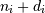 )。
)。
通过基本切片生成的所有数组始终为原始数组的views。
序列切片的标准规则适用于基于每维的基本切片(包括使用阶跃索引)。一些有用的概念要记住包括:
The basic slice syntax is
i:j:kwhere i is the starting index, j is the stopping index, and k is the step (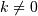 ). 这选择具有索引值i,i + k,...,i + 1的m (m-1)k t>其中
). 这选择具有索引值i,i + k,...,i + 1的m (m-1)k t>其中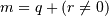 和q和r是通过将j-i k:j_i = qk + r,使得i +(m-1) j。
和q和r是通过将j-i k:j_i = qk + r,使得i +(m-1) j。例
>>> x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> x[1:7:2] array([1, 3, 5])
负i和j被解释为n + i和n + j其中n t4 >是对应维度中的元素数。负k使得向更小的指数迈进。
例
>>> x[-2:10] array([8, 9]) >>> x[-3:3:-1] array([7, 6, 5, 4])
假设n是要切片的维度中的元素数。然后,如果不给出i,则对于k>默认为0. 0和n-1,对于k 。如果没有给出j,则对于k>,默认为n 0和-1,对于k 。如果未给出k,则其默认为1。注意,
::与:相同,表示选择沿此轴的所有索引。例
>>> x[5:] array([5, 6, 7, 8, 9])
如果选择元组中的对象数小于N,则对任何后续维都假定为
:。例
>>> x = np.array([[[1],[2],[3]], [[4],[5],[6]]]) >>> x.shape (2, 3, 1) >>> x[1:2] array([[[4], [5], [6]]])
Ellipsis展开为与x.ndim相同长度的选择元组所需的:对象的数量。可能只有一个省略号。例
>>> x[...,0] array([[1, 2, 3], [4, 5, 6]])
选择元组中的每个
newaxis对象用于将生成的选择的维度扩展一个单位长度维度。添加的维度是选择元组中newaxis对象的位置。例
>>> x[:,np.newaxis,:,:].shape (2, 1, 3, 1)
整数i返回与
i:i+1相同的值,除非返回对象的维数减少1。特别地,具有p元素为整数(以及所有其他条目:)的选择元组返回具有维度N-1 。如果N = 1,则返回的对象是数组标量。这些对象在Scalars中进行了说明。If the selection tuple has all entries
:except the p-th entry which is a slice objecti:j:k, then the returned array has dimension N formed by concatenating the sub-arrays returned by integer indexing of elements i, i+k, ..., i + (m - 1) k < j,具有切片元组中的多于一个非
:条目的基本切片,像使用单个非:条目重复应用切片,其中非:条目(所有其他非:条目替换为:)。因此,在基本切片下,x[ind1,...,ind2,:]像x[ind1][...,ind2,:]警告
以上是高级索引的不 true。
你可以使用切片来设置数组中的值,但(不同于列表)你永远不能增长数组。要在
x [obj] = 值中设置的值的大小必须(可广播)形状与x[obj]相同。
注意
请记住,切片元组总是可以构造为obj并在x[obj]表示法中使用。切片对象可以在构造中用于替换[start:stop:step]符号。例如,x[1:10:5,::-1]也可以实现为obj = (slice(1,10,5), slice(None,None,-1)); x [obj]。这对于构造对任意维度的数组起作用的通用代码是有用的。
Advanced Indexing¶
当选择对象obj是非元组序列对象,ndarray(数据类型为integer或bool)或至少具有一个序列对象或ndarray(数据类型为integer或bool)。有两种类型的高级索引:integer和Boolean。
高级索引始终返回数据的副本(与返回view形成对比)。
警告
高级索引的定义意味着x[(1,2,3),]根本不同于x[(1,2,3)]。后者等效于x[1,2,3],它将触发基本选择,而前者将触发高级索引。一定要明白为什么会发生这种情况。
也认识到x[[1,2,3]]将触发高级索引,而x[[1,2,slice(None)]]
Integer array indexing¶
整数数组索引允许根据数组中的N维索引选择数组中的任意项。每个整数数组表示到该维度的索引数。
Purely integer array indexing¶
当索引包括与索引的数组具有维数一样多的整数数组时,索引是直接的,但不同于切片。
高级索引始终为broadcast,并迭代为一个:
result[i_1, ..., i_M] == x[ind_1[i_1, ..., i_M], ind_2[i_1, ..., i_M],
..., ind_N[i_1, ..., i_M]]
注意,结果形状与(广播)索引数字形状ind_1, ..., ind_N 。
例
从每一行,应该选择一个特定的元素。行索引只是[0, 1, 2],列索引指定要选择的元素对应的行,这里[0, 1, 0]。一起使用这两个任务可以使用高级索引来解决:
>>> x = np.array([[1, 2], [3, 4], [5, 6]])
>>> x[[0, 1, 2], [0, 1, 0]]
array([1, 4, 5])
为了实现类似于上面的基本切片的行为,可以使用广播。功能ix_可以帮助进行此广播。这是最好的理解与一个例子。
例
从4x3数组中,角元素应使用高级索引选择。因此,列为[0, 2]之一的所有元素,并且该行是[0 , 3]。要使用高级索引,需要明确选择所有元素。使用前面解释的方法可以写:
>>> x = array([[ 0, 1, 2],
... [ 3, 4, 5],
... [ 6, 7, 8],
... [ 9, 10, 11]])
>>> rows = np.array([[0, 0],
... [3, 3]], dtype=np.intp)
>>> columns = np.array([[0, 2],
... [0, 2]], dtype=np.intp)
>>> x[rows, columns]
array([[ 0, 2],
[ 9, 11]])
然而,由于上面的索引数组只是重复自身,所以可以使用广播(比较诸如行[:, np.newaxis] / t3> 列)以简化此操作:
>>> rows = np.array([0, 3], dtype=np.intp)
>>> columns = np.array([0, 2], dtype=np.intp)
>>> rows[:, np.newaxis]
array([[0],
[3]])
>>> x[rows[:, np.newaxis], columns]
array([[ 0, 2],
[ 9, 11]])
也可以使用功能ix_实现此广播:
>>> x[np.ix_(rows, columns)]
array([[ 0, 2],
[ 9, 11]])
注意,如果不使用np.ix_调用,将只选择对角元素,如前面的示例中所使用的那样。这个差异是使用多个高级索引建立索引时最重要的事情。
Combining advanced and basic indexing¶
当索引中有至少一个切片(:),省略号(...)或np.newaxis更多的维度比高级索引),那么行为可能更复杂。它就像连接每个高级索引元素的索引结果
在最简单的情况下,只有单个高级索引。单个高级索引可以例如替换切片,并且结果数组将是相同的,然而,其是副本并且可以具有不同的存储器布局。当可能时,切片是优选的。
例
>>> x[1:2, 1:3]
array([[4, 5]])
>>> x[1:2, [1, 2]]
array([[4, 5]])
理解情况的最简单的方法可能是根据结果形状来思考。索引操作有两个部分,由基本索引(不包括整数)定义的子空间和来自高级索引部分的子空间。需要区分两种情况的索引组合:
- 高级索引由切片,省略号或newaxis分隔。例如
x [arr1, :, arr2]。 - 高级索引都是彼此相邻的。For example
x[..., arr1, arr2, :]but notx[arr1, :, 1]since1is an advanced index in this regard.
在第一种情况下,从高级索引操作得到的维度首先出现在结果数组中,然后是子空间维度。在第二种情况下,来自高级索引操作的维度被插入到结果数组中,与它们在初始数组中的位置相同(后一个逻辑是使简单的高级索引与切片行为相同)。
例
假设x.shape是(10,20,30)并且ind是(2,3,4)形索引intp数组,那么结果 = x [...,ind,:] 4,30),因为(20,)形子空间已经被(2,3,4)形广播的索引子空间替换。如果我们让(2,3,4)形子循环i,j,k,则结果[...,i,j,k, / t2> = x [...,ind [i,j,k],:] 此示例生成与x.take(ind, axis=-2)相同的结果。
例
让x.shape为(10,20,30,40,50),并假设ind_1和ind_2可以广播到形状,3,4)。然后x[:,ind_1,ind_2]具有形状(10,2,3,4,40,50),因为来自X的(20,30)形子空间已经被替换为,3,4)个子空间。但是,x[:,ind_1,:,ind_2]具有形状(2,3,4,10,30,50),因为在索引子空间中没有明确的位置,因此它是坚持到开始。始终可以使用.transpose()将子空间移动到任何需要的位置。请注意,此示例无法使用take进行复制。
Boolean array indexing¶
当obj是布尔类型的数组对象时,例如可以从比较运算符返回时,发生此高级索引。单个布尔索引数组实际上等同于x[obj.nonzero()]其中,如上所述,obj.nonzero()返回长度obj.ndim),其显示True的元素obj。但是,obj.shape == x.shape时更快。
If obj.ndim == x.ndim, x[obj] returns a 1-dimensional array filled with the elements of x corresponding to the True values of obj. 搜索顺序为row-major,C风格。如果obj在x的边界之外的条目处具有True值,则将引发索引错误。如果obj小于x,则与填充False相同。
例
一个常见的用例是过滤所需的元素值。例如,可能希望从数组中选择不是NaN的所有条目:
>>> x = np.array([[1., 2.], [np.nan, 3.], [np.nan, np.nan]])
>>> x[~np.isnan(x)]
array([ 1., 2., 3.])
或者希望向所有负面元素添加一个常数:
>>> x = np.array([1., -1., -2., 3])
>>> x[x < 0] += 20
>>> x
array([ 1., 19., 18., 3.])
通常,如果索引包括布尔数组,则结果将与将obj.nonzero()插入到相同位置并使用上述整数数组索引机制相同。x [ind_1, boolean_array, ind_2]等效于) + boolean_array.nonzero() + (ind_2,)]。
如果只有一个布尔数组,并且没有整数索引数组,这是直接的。必须注意确保布尔索引的精确多少维度,因为它应该使用。
例
从数组中,选择总和小于或等于两个的所有行:
>>> x = np.array([[0, 1], [1, 1], [2, 2]])
>>> rowsum = x.sum(-1)
>>> x[rowsum <= 2, :]
array([[0, 1],
[1, 1]])
但如果rowsum也有两个维度:
>>> rowsum = x.sum(-1, keepdims=True)
>>> rowsum.shape
(3, 1)
>>> x[rowsum <= 2, :] # fails
IndexError: too many indices
>>> x[rowsum <= 2]
array([0, 1])
最后一个只给出第一个元素,因为额外的维度。比较rowsum.nonzero()以了解此示例。
使用obj.nonzero()的类比可以最好地理解组合多个布尔索引数组或布尔值与整数索引数组。函数ix_也支持布尔数组,并且不会出现任何惊喜。
例
使用布尔索引选择所有行加起来为偶数。同时,应使用高级整数索引选择列0和2。使用ix_函数,可以这样做:
>>> x = array([[ 0, 1, 2],
... [ 3, 4, 5],
... [ 6, 7, 8],
... [ 9, 10, 11]])
>>> rows = (x.sum(-1) % 2) == 0
>>> rows
array([False, True, False, True], dtype=bool)
>>> columns = [0, 2]
>>> x[np.ix_(rows, columns)]
array([[ 3, 5],
[ 9, 11]])
没有np.ix_调用或只选择对角元素。
或没有np.ix_(比较整数数组示例):
>>> rows = rows.nonzero()[0]
>>> x[rows[:, np.newaxis], columns]
array([[ 3, 5],
[ 9, 11]])
Detailed notes¶
这些是一些详细的注释,这对于日常索引(没有特定的顺序)是不重要的:
- 本机NumPy索引类型为
intp,可能与默认整数数组类型不同。intp是足以安全索引任何数组的最小数据类型;对于高级索引,它可能比其他类型更快。 - 对于高级分配,通常不能保证迭代顺序。这意味着如果一个元素被多次设置,则不可能预测最终结果。
- 空(元组)索引是零维数组的完整标量索引。
x[()]如果x是零维,则返回标量,否则返回视图。另一方面,x[...]总是返回一个视图。 - 如果零索引数组存在于索引和中,它是一个完整的整数索引,结果将是一个标量,而不是零维数组。(不触发高级索引。)
- 当存在省略号(
...)但没有大小(即替换零:)时,结果仍然总是数组。如果没有高级索引的视图,否则为副本。 - 对于零维布尔数组,布尔数组的
nonzero等价性不成立。 - 当高级索引操作的结果没有元素但是单个索引超出边界时,无论是否引起
IndexError都是未定义的(例如,x [[] / t3> [123]],其中123超出范围)。 - 当在分配期间发生转换错误(例如使用字符串序列更新数值数组)时,分配给的数组可能会以不可预测的部分更新状态结束。但是,如果发生任何其他错误(例如超出范围索引),数组将保持不变。
- 高级索引结果的存储器布局针对每个索引操作进行优化,并且可以假设没有特定的存储器顺序。
- When using a subclass (especially one which manipulates its shape), the default
ndarray.__setitem__behaviour will call__getitem__for basic indexing but not for advanced indexing. 对于这样的子类,可以优选用数据上的基类 ndarray视图调用ndarray.__setitem__。如果子类__getitem__不返回视图,则此必须。
Field Access¶
如果ndarray对象是结构化数组,则可以通过用字符串索引数组来访问数组的字段。
索引x['field-name']向数组返回一个新的view,其形状与x相同字段是一个子数组),但是数据类型为x.dtype['field-name'],并且只包含指定字段中数据的一部分。此外,record array标量可以以这种方式“索引”。
索引到结构化数组也可以使用字段名称列表(例如 x[['field-name1','field-name2']]来完成。目前,这将返回一个新的数组,其中包含列表中指定字段中值的副本。从NumPy 1.7,返回一个副本被弃用,有利于返回一个视图。现在将继续返回副本,但在写入副本时将发出FutureWarning。如果你依赖于当前行为,那么我们建议显式复制返回的数组,即使用x [['field-name1','field-name2']]。copy()。这将与过去和未来版本的NumPy工作。
如果被访问的字段是子数组,则子数组的维度将附加到结果的形状。
例
>>> x = np.zeros((2,2), dtype=[('a', np.int32), ('b', np.float64, (3,3))])
>>> x['a'].shape
(2, 2)
>>> x['a'].dtype
dtype('int32')
>>> x['b'].shape
(2, 2, 3, 3)
>>> x['b'].dtype
dtype('float64')