带有词嵌入的循环神经网络¶
代码 — 引文 — 联系方式¶
论文¶
如果你使用本教程,请引用以下文章:
- [pdf] Grégoire Mesnil, Xiaodong He, Li Deng and Yoshua Bengio.Investigation of Recurrent-Neural-Network Architectures and Learning Methods for Spoken Language Understanding.Interspeech, 2013.
- [pdf] Gokhan Tur, Dilek Hakkani-Tur and Larry Heck.What is left to be understood in ATIS?
- [pdf] Christian Raymond and Giuseppe Riccardi.Generative and discriminative algorithms for spoken language understanding.Interspeech, 2007.
- [pdf] Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Bergstra, James, Goodfellow, Ian, Bergeron, Arnaud, Bouchard, Nicolas, and Bengio, Yoshua.Theano: new features and speed improvements.NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2012.
- [pdf] Bergstra, James, Breuleux, Olivier, Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Desjardins, Guillaume, Turian, Joseph, Warde-Farley, David, and Bengio, Yoshua.Theano: a CPU and GPU math expression compiler.In Proceedings of the Python for Scientific Computing Conference (SciPy), June 2010.
谢谢你!
联系方式¶
如果想报告或反馈任何问题,请发送电子邮件至Grégoire Mesnil (first-add-a-dot-last-add-at-gmail-add-a-dot-com)。我们很高兴收到你的来信。
任务¶
Slot-Filling(口语理解)在于根据给定的一个句子,给每个单词赋予一个标签。这是一个分类任务。
数据集¶
这项任务的基准是DARPA收集的ATIS(Airline Travel Information System)数据集,这个数据集有点老而且不大。这里是使用Inside Outside Beginning(IOB)表示的一个示例句子(或话语)。
| 输入(词) | show | flights | from | Boston | to | New | York | today |
| 输出(标签) | O | O | O | B-dept | O | B-arr | I-arr | B-date |
ATIS官方的划分在训练/测试集中包含4,978/893个句子,总共有56,590/9,198个词(平均句子长度为15)。类别(不同的槽)的数量是128,包括O标签(NULL)。
作为微软研究人员,对于测试集中未见过的词的处理方式,我们将训练集中仅有一次出现的词标记为<UNK>,然后用这个符号表示测试集中的未见过的词。作为Ronan Collobert及其同事,我们用字符串DIGIT转换数字序列,即1984转换为DIGITDIGITDIGITDIGIT。
我们将官方训练集分成训练和验证集,分别包含80%和20%的官方训练语句。由于数据集的数据较少,在95%水平的F1测量中,显著的性能改进差异必须大于0.6%。为了评估目的,实验必须报告以下指标:
我们将使用conlleval PERL脚本来测量模型的性能。
循环神经网络模型¶
原始输入编码¶
一个词符对应于一个单词。ATIS词汇表中的每个词符都关联一个索引。每个句子是一个索引数组(int32)。(train, valid, test)中的每个数据集是一个索引数组组成的列表。定义一个python字典用于将索引空间映射到单词空间。
>>> sentence
array([383, 189, 13, 193, 208, 307, 195, 502, 260, 539,
7, 60, 72, 8, 350, 384], dtype=int32)
>>> map(lambda x: index2word[x], sentence)
['please', 'find', 'a', 'flight', 'from', 'miami', 'florida',
'to', 'las', 'vegas', '<UNK>', 'arriving', 'before', 'DIGIT', "o'clock", 'pm']
与此特定句子相对应的标签也是如此。
>>> labels
array([126, 126, 126, 126, 126, 48, 50, 126, 78, 123, 81, 126, 15,
14, 89, 89], dtype=int32)
>>> map(lambda x: index2label[x], labels)
['O', 'O', 'O', 'O', 'O', 'B-fromloc.city_name', 'B-fromloc.state_name',
'O', 'B-toloc.city_name', 'I-toloc.city_name', 'B-toloc.state_name',
'O', 'B-arrive_time.time_relative', 'B-arrive_time.time',
'I-arrive_time.time', 'I-arrive_time.time']
上下文窗口¶
给定一个句子(索引数组)和窗口大小(1,3,5,...),我们需要将句子中的每个单词转换为围绕该特定单词的上下文窗口。详细来说,我们有:
def contextwin(l, win):
'''
win :: int corresponding to the size of the window
given a list of indexes composing a sentence
l :: array containing the word indexes
it will return a list of list of indexes corresponding
to context windows surrounding each word in the sentence
'''
assert (win % 2) == 1
assert win >= 1
l = list(l)
lpadded = win // 2 * [-1] + l + win // 2 * [-1]
out = [lpadded[i:(i + win)] for i in range(len(l))]
assert len(out) == len(l)
return out
索引-1对应于我们在句子的开头/结尾处插入的PADDING索引。
这里是一个示例:
>>> x
array([0, 1, 2, 3, 4], dtype=int32)
>>> contextwin(x, 3)
[[-1, 0, 1],
[ 0, 1, 2],
[ 1, 2, 3],
[ 2, 3, 4],
[ 3, 4,-1]]
>>> contextwin(x, 7)
[[-1, -1, -1, 0, 1, 2, 3],
[-1, -1, 0, 1, 2, 3, 4],
[-1, 0, 1, 2, 3, 4,-1],
[ 0, 1, 2, 3, 4,-1,-1],
[ 1, 2, 3, 4,-1,-1,-1]]
总而言之,我们从索引数组开始,并以索引矩阵结束。每行对应于围绕此单词的上下文窗口。
词嵌入¶
一旦我们将句子转换为上下文窗口,即索引矩阵,我们必须将这些索引与嵌入(与每个单词相关联的实值向量)相关联。使用Theano,它给出:
import theano, numpy
from theano import tensor as T
# nv :: size of our vocabulary
# de :: dimension of the embedding space
# cs :: context window size
nv, de, cs = 1000, 50, 5
embeddings = theano.shared(0.2 * numpy.random.uniform(-1.0, 1.0, \
(nv+1, de)).astype(theano.config.floatX)) # add one for PADDING at the end
idxs = T.imatrix() # as many columns as words in the context window and as many lines as words in the sentence
x = self.emb[idxs].reshape((idxs.shape[0], de*cs))
x符号变量对应于形状矩阵(句子中的词数,嵌入空间的维度 X 上下文窗口大小)。
让我们编译一个aano函数来这样做
>>> sample
array([0, 1, 2, 3, 4], dtype=int32)
>>> csample = contextwin(sample, 7)
[[-1, -1, -1, 0, 1, 2, 3],
[-1, -1, 0, 1, 2, 3, 4],
[-1, 0, 1, 2, 3, 4,-1],
[ 0, 1, 2, 3, 4,-1,-1],
[ 1, 2, 3, 4,-1,-1,-1]]
>>> f = theano.function(inputs=[idxs], outputs=x)
>>> f(csample)
array([[-0.08088442, 0.08458307, 0.05064092, ..., 0.06876887,
-0.06648078, -0.15192257],
[-0.08088442, 0.08458307, 0.05064092, ..., 0.11192625,
0.08745284, 0.04381778],
[-0.08088442, 0.08458307, 0.05064092, ..., -0.00937143,
0.10804889, 0.1247109 ],
[ 0.11038255, -0.10563177, -0.18760249, ..., -0.00937143,
0.10804889, 0.1247109 ],
[ 0.18738101, 0.14727569, -0.069544 , ..., -0.00937143,
0.10804889, 0.1247109 ]], dtype=float32)
>>> f(csample).shape
(5, 350)
我们现在具有上下文窗口词嵌入的序列(长度为5,对应于句子的长度),其易于馈送到简单的循环神经网络进行迭代。
Elman循环神经网络¶
下面的(Elman)循环神经网络(E-RNN)将当前输入(时间t)和先前的隐藏状态(时间t-1)作为输入。然后它进行迭代。
在上一节中,我们处理过输入以适应这种顺序/时间结构。它包括其中行0对应于时间步长t=0,行1对应于时间步长t=1等
要学习的E-RNN的参数是:
- 嵌入字(实值矩阵)
- 初始隐藏状态(实值向量)
- 用于输入
t和先前隐藏层状态t-1的线性投影的两个矩阵, - (可选)偏差。建议:不要使用它。
- softmax分层
超参数定义整个架构:
- 维度的词嵌入
- 词汇大小
- 隐藏单位数
- 类数
- 随机种子+方式初始化模型
它给出以下代码:
class RNNSLU(object):
''' elman neural net model '''
def __init__(self, nh, nc, ne, de, cs):
'''
nh :: dimension of the hidden layer
nc :: number of classes
ne :: number of word embeddings in the vocabulary
de :: dimension of the word embeddings
cs :: word window context size
'''
# parameters of the model
self.emb = theano.shared(name='embeddings',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(ne+1, de))
# add one for padding at the end
.astype(theano.config.floatX))
self.wx = theano.shared(name='wx',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(de * cs, nh))
.astype(theano.config.floatX))
self.wh = theano.shared(name='wh',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(nh, nh))
.astype(theano.config.floatX))
self.w = theano.shared(name='w',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(nh, nc))
.astype(theano.config.floatX))
self.bh = theano.shared(name='bh',
value=numpy.zeros(nh,
dtype=theano.config.floatX))
self.b = theano.shared(name='b',
value=numpy.zeros(nc,
dtype=theano.config.floatX))
self.h0 = theano.shared(name='h0',
value=numpy.zeros(nh,
dtype=theano.config.floatX))
# bundle
self.params = [self.emb, self.wx, self.wh, self.w,
self.bh, self.b, self.h0]
然后我们整合了从嵌入矩阵构建输入的方式:
idxs = T.imatrix()
x = self.emb[idxs].reshape((idxs.shape[0], de*cs))
y_sentence = T.ivector('y_sentence') # labels
我们使用scan操作符来构造递归,工作方式类似于charm:
def recurrence(x_t, h_tm1):
h_t = T.nnet.sigmoid(T.dot(x_t, self.wx)
+ T.dot(h_tm1, self.wh) + self.bh)
s_t = T.nnet.softmax(T.dot(h_t, self.w) + self.b)
return [h_t, s_t]
[h, s], _ = theano.scan(fn=recurrence,
sequences=x,
outputs_info=[self.h0, None],
n_steps=x.shape[0])
p_y_given_x_sentence = s[:, 0, :]
y_pred = T.argmax(p_y_given_x_sentence, axis=1)
然后Theano将自动计算所有梯度以最大化对数似然性:
lr = T.scalar('lr')
sentence_nll = -T.mean(T.log(p_y_given_x_sentence)
[T.arange(x.shape[0]), y_sentence])
sentence_gradients = T.grad(sentence_nll, self.params)
sentence_updates = OrderedDict((p, p - lr*g)
for p, g in
zip(self.params, sentence_gradients))
下一步编译这些函数:
self.classify = theano.function(inputs=[idxs], outputs=y_pred)
self.sentence_train = theano.function(inputs=[idxs, y_sentence, lr],
outputs=sentence_nll,
updates=sentence_updates)
我们通过在每次更新之后将单词球体上的单词嵌入标准化来保持单词:
self.normalize = theano.function(inputs=[],
updates={self.emb:
self.emb /
T.sqrt((self.emb**2)
.sum(axis=1))
.dimshuffle(0, 'x')})
就是这样!
Evaluation¶
使用先前定义的函数,您可以将预测的标签与真实标签进行比较,并计算一些指标。在此repo中,我们将围绕conlleval PERL脚本创建一个包装器。由于内部外部开始(IOB)表示,计算这些度量是不平凡的,即如果词 - 开始和内部和字词外部预测是所有正确。请注意,扩展名为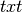 ,您必须将其更改为
,您必须将其更改为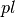 。
。
训练¶
Updates¶
对于随机梯度下降(SGD)更新,我们将整个句子视为一个迷你批处理,并对每个句子执行一次更新。可以执行纯SGD(与迷你批处理相反),其中一次只对一个字进行更新。
在每次迭代/更新之后,我们规范化单词embeddings以将它们保持在单位球面上。
停止条件¶
在验证集上的早停是我们的正则化技术:训练针对给定数目的历元(单次遍历整个数据集)运行,并且保持最佳模型与每个计算的验证集上计算的F1得分时代。
运行代码¶
使用 下载数据后,用户可以通过调用以下代码来运行代码:
下载数据后,用户可以通过调用以下代码来运行代码:
python code/rnnslu.py
('NEW BEST: epoch', 25, 'valid F1', 96.84, 'best test F1', 93.79)
[learning] epoch 26 >> 100.00% completed in 28.76 (sec) <<
[learning] epoch 27 >> 100.00% completed in 28.76 (sec) <<
...
('BEST RESULT: epoch', 57, 'valid F1', 97.23, 'best test F1', 94.2, 'with the model', 'rnnslu')
计时¶
使用存储库在ATIS上运行实验将在少于40秒内在i7 CPU 950 @ 3.07GHz上使用少于200Mo的RAM运行一个时期:
[learning] epoch 0 >> 100.00% completed in 34.48 (sec) <<
经过几个时期,你获得了不错的表现F1分数的94.48%。:
NEW BEST: epoch 28 valid F1 96.61 best test F1 94.19
NEW BEST: epoch 29 valid F1 96.63 best test F1 94.42
[learning] epoch 30 >> 100.00% completed in 35.04 (sec) <<
[learning] epoch 31 >> 100.00% completed in 34.80 (sec) <<
[...]
NEW BEST: epoch 40 valid F1 97.25 best test F1 94.34
[learning] epoch 41 >> 100.00% completed in 35.18 (sec) <<
NEW BEST: epoch 42 valid F1 97.33 best test F1 94.48
[learning] epoch 43 >> 100.00% completed in 35.39 (sec) <<
[learning] epoch 44 >> 100.00% completed in 35.31 (sec) <<
[...]
Word Embedding Nearest Neighbors¶
我们可以检查学习的嵌入的k-最近邻。L2和余弦距离给出相同的结果,所以我们绘制他们的余弦距离。
| atlanta | back | ap80 | but | 飞机 | 商家 | a | 八月 | 实际 | cheap |
|---|---|---|---|---|---|---|---|---|---|
| phoenix | 生活 | ap57 | 如果 | 平面 | 教练 | 人 | 九月 | 提供 | 工作日 |
| 丹佛 | 生活 | ap | 向上 | 服务 | 第一 | 做 | 一月 | 价格 | 平日 |
| 塔科马 | 都 | 连接 | 一个 | 飞机 | 第四 | 但 | 六月 | 停止 | 上午 |
| 哥伦布 | 怎么样 | 明天 | 现在 | 座位 | 节约 | 数字 | 十二月 | 数 | 早 |
| 西雅图 | 我 | 之前 | 量 | 站 | 第十 | 缩写 | 十一月 | 飞行 | sfo |
| 明尼阿波利斯 | 出来 | 最早 | 更多 | 那 | 第二 | 如果 | 四月 | 那里 | 密尔沃基 |
| 匹兹堡 | 其他 | 连接 | 缩写 | 上 | 第五 | 向上 | 七月 | 服务 | jfk |
| 安大略 | 平面 | 节约 | 限制 | 涡轮螺旋桨 | 第三 | 服务 | jfk | 谢谢 | 最短 |
| 蒙特利尔 | 服务 | 教练 | 意思 | 意思 | 第十二 | 数据库 | 十月 | 票 | bwi |
| 费城 | 票价 | 今天 | 感兴趣 | 量 | 第六 | 乘客 | 可能 | 是 | 最后 |
正如你可以判断,有限的词汇量(大约500字)给我们减轻的性能。根据人的判断:有些是好的,有些是坏的。