用于情绪分析的LSTM网络¶
摘要¶
本教程旨在提供使用长期短期存储器(LSTM)架构的循环神经网络(RNN)如何使用Theano实现的示例。在本教程中,此模型用于对来自大型电影评论数据集(有时称为IMDB数据集)的电影评论执行情绪分析。
在这个任务中,给定电影评论,模型尝试预测它是正面还是负面。这是一个二进制分类任务。
数据¶
如前所述,所提供的脚本用于在大电影评论数据集数据集上训练LSTM循环神经网络。
虽然数据集是公开的,但在本教程中,我们提供了之前根据此LSTM实现的需要进行预处理的数据集的副本。运行本教程中提供的代码将自动将数据下载到本地目录。要使用您自己的数据,请使用作为本教程一部分提供的(预处理脚本)。
一旦模型被训练,你可以使用作为本教程一部分提供的词索引词典(imdb.dict.pkl.gz)用自己的语料库测试它。
模型¶
LSTM¶
In a traditional recurrent neural network, during the gradient back-propagation phase, the gradient signal can end up being multiplied a large number of times (as many as the number of timesteps) by the weight matrix associated with the connections between the neurons of the recurrent hidden layer. 这意味着,过渡矩阵中的权重的大小可以对学习过程具有强烈的影响。
如果该矩阵中的权重小(或者,更正式地,如果权重矩阵的前导特征值小于1.0),则可以导致称为消失梯度的情形,其中梯度信号变得如此小的学习或者变得非常缓慢或者完全停止工作。它也可以使学习数据中的长期依赖性的任务变得更加困难。相反,如果该矩阵中的权重大(或者,更正式地,如果权重矩阵的前导特征值大于1.0),则可能导致梯度信号如此大以至于可能导致学习的情况分歧。这通常被称为爆炸梯度。
这些问题是LSTM模型背后的主要动机,其引入称为存储器单元的新结构(参见下面的图1)。存储器单元由四个主要元件组成:输入门,具有自循环连接(与自身的连接)的神经元,忘记门和输出门。自循环连接具有1.0的权重并且确保除了任何外部干扰之外,存储器单元的状态可以从一个时间步长保持恒定。门用于调节存储器单元本身与其环境之间的相互作用。输入门可以允许输入信号改变存储器单元的状态或阻止它。另一方面,输出门可以允许存储器单元的状态对其他神经元具有影响或防止它。最后,忘记门可以调制存储器单元的自循环连接,允许单元根据需要记住或忘记其之前的状态。
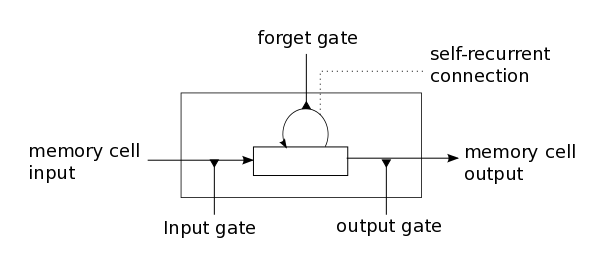
图1:LSTM存储单元的示意图。
下面的等式描述了如何在每个时间步长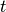 时更新存储器单元层。在这些方程中:
时更新存储器单元层。在这些方程中:
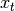 是在时间到存储器单元层的输入
是在时间到存储器单元层的输入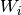 ,
,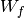 ,
,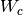 ,
,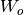 ,
,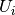 ,
,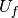 ,
,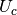 ,
,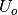 和
和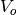
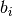 ,
,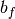 ,
,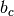 和
和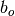 是偏置向量
是偏置向量
首先,我们计算在时间时存储器单元的状态的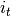 ,输入门和
,输入门和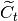 的候选值:
的候选值:
(1)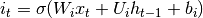
(2)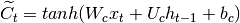
其次,我们计算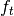 的值,在时间激活存储器单元的忘记门:
的值,在时间激活存储器单元的忘记门:
(3)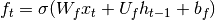
Given the value of the input gate activation , the forget gate activation and the candidate state value , we can compute 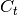 the memory cells’ new state at time :
the memory cells’ new state at time :
(4)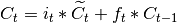
利用存储器单元的新状态,我们可以计算它们的输出门的值,并且随后计算它们的输出: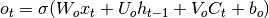
(5)
(6)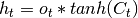
我们的模型¶
我们在本教程中使用的模型是标准LSTM模型的变体。在该变型中,单元的输出栅极的激活不依赖于存储器单元的状态。这使我们能够更有效地执行一部分计算(有关详细信息,请参见下面的实现说明)。这意味着在我们已经实现的变型中,没有矩阵并且等式(5)被等式(7)代替:
(7)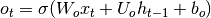
我们的模型由单个LSTM层组成,其后是平均池和逻辑回归层,如下面的图2所示。因此,从输入序列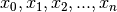 ,LSTM层中的存储器单元将产生表示序列
,LSTM层中的存储器单元将产生表示序列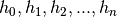 。然后对所有时间步长进行该表示序列的平均,得到表示h。最后,该表示被馈送到逻辑回归层,其目标是与输入序列相关联的类标签。
。然后对所有时间步长进行该表示序列的平均,得到表示h。最后,该表示被馈送到逻辑回归层,其目标是与输入序列相关联的类标签。
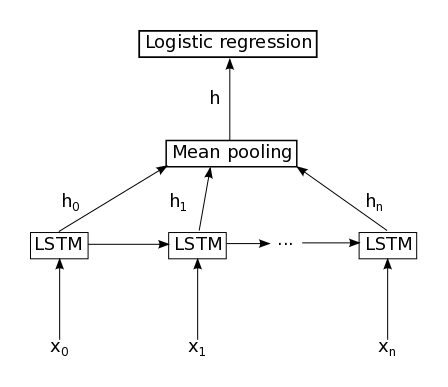
图2:本教程中使用的模型图示。它由单个LSTM层组成,随后是随时间的平均汇集和逻辑回归。
实现说明:在本教程中包含的代码中,等式(1),(2),>和(7),以使计算更有效。这是可能的,因为这些方程中没有一个依赖于由其它方程产生的结果。通过将四个矩阵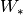 连接成单个权重矩阵
连接成单个权重矩阵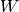 并对权重矩阵
并对权重矩阵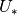 执行相同的级联以产生矩阵
执行相同的级联以产生矩阵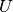 和偏置向量
和偏置向量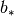 以产生向量
以产生向量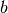 。然后,可以用下式计算非线性前激活:
。然后,可以用下式计算非线性前激活:
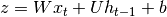
然后将结果切片以获得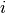 ,
,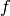 ,和
,和 的非非线性激活,然后对于每一个独立地应用非线性。
的非非线性激活,然后对于每一个独立地应用非线性。
代码 — 引文 — 联系方式¶
代码¶
LSTM实现可以在以下两个文件中找到:
在下载两个脚本并将两者放在同一文件夹中后,用户可以通过调用以下代码运行:
THEANO_FLAGS="floatX=float32" python lstm.py
脚本将自动下载数据并将其解压缩。
注意:提供的代码支持随机渐变下降(SGD),AdaDelta和RMSProp优化方法。你建议使用AdaDelta或RMSProp,因为SGD在这个特定的模型上表现不佳。
论文¶
如果你使用本教程,请引用以下文章。
LSTM模型的介绍:
- [pdf] Hochreiter, S., & Schmidhuber, J.(1997).Long short-term memory.Neural computation, 9(8), 1735-1780.
向LSTM模型添加忘记门:
- [pdf] Gers, F. A., Schmidhuber, J., & Cummins, F. (2000).学会忘记:用LSTM持续预测。神经计算,12(10),2451-2471。
最近的LSTM论文:
- [pdf] Graves,Alex。使用循环神经网络的监督序列标记。Vol。385. Springer,2012。
Theano相关文章:
- [pdf] Bastien,Frédéric,Lamblin,Pascal,Pascanu,Razvan,Bergstra,James,Goodfellow,Ian,Bergeron,Arnaud,Bouchard,Nicolas和Bengio,Yoshua。Theano:新功能和速度改进。NIPS深度学习和无监督特征学习研讨会,2012。
- [pdf] Bergstra,James,Breuleux,Olivier,Bastien,Frédéric,Lamblin,Pascal,Pascanu,Razvan,Desjardins,Guillaume,Turian,Joseph,Warde-Farley,David和Bengio,Yoshua。Theano:一个CPU和GPU数学表达式编译器。在Proceedings of the Python for Scientific Computing Conference(SciPy),2010年6月。
谢谢你!
联系方式¶
如果有任何问题报告或反馈,请发送电子邮件至Pierre Luc Carrier或Kyunghyun Cho。我们很高兴听到你的来信。
参考¶
- Hochreiter, S., & Schmidhuber, J.(1997).Long short-term memory.Neural computation, 9(8), 1735-1780.
- Gers,F.A.,Schmidhuber,J.,&Cummins,F。(2000)。Learning to forget: Continual prediction with LSTM.神经计算,12(10),2451-2471。
- Graves,A.(2012)。使用循环神经网络的监督序列标记(Vol。385)。Springer。
- Hochreiter,S.,Bengio,Y.,Frasconi,P.,&Schmidhuber,J.(2001)。循环网中的梯度流:学习长期依赖的困难。
- Bengio,Y.,Simard,P.,&Frasconi,P。(1994)。学习长期依赖与梯度下降是困难的。Neural Networks,IEEE Transactions on,5(2),157-166。
- Maas,A.L.,Daly,R.E.,Pham,P.T.,Huang,D.,Ng,A.Y。,&Potts,C.(2011,June)。情绪分析的学习单词向量。在计算语言学协会第49届年会论文集:人类语言技术第1卷(pp。142-150)。计算语言学协会。