Beyond the Basics¶
Iterating over elements in the array¶
Basic Iteration¶
一个常见的算法要求是能够遍历多维数组中的所有元素。数组迭代器对象使得这很容易以通用的方式,适用于任何维度的数组。当然,如果你知道你将使用的维数,那么你总是可以编写嵌套的for循环来完成迭代。然而,如果你想编写与任何维数一起工作的代码,那么你可以使用数组迭代器。访问数组的.flat属性时返回数组迭代器对象。
基本用法是调用PyArray_IterNew(array),其中数组是一个ndarray对象(或其子类之一)。返回的对象是一个数组迭代器对象(由ndarray的.flat属性返回的相同对象)。此对象通常转换为PyArrayIterObject *,以便可以访问其成员。唯一需要的成员是iter->size,其中包含数组的总大小,iter->index,其中包含当前的1-d索引数组和iter->dataptr,它是指向数组的当前元素的数据的指针。有时,访问iter->ao也是有用的,它是一个指向底层ndarray对象的指针。
在数组的当前元素处理数据之后,可以使用宏PyArray_ITER_NEXT(iter)获得数组的下一个元素。迭代总是以C型连续方式进行(最后索引变化最快)。PyArray_ITER_GOTO(iter,destination)可用于跳转到数组中的特定点,其中destination是npy_intp数据类型的数组,具有至少处理基础数组中的维数的空间。有时,使用PyArray_ITER_GOTO1D(iter,index)将有助于跳转到由index。然而,最常见的用法在以下示例中给出。
PyObject *obj; /* assumed to be some ndarray object */
PyArrayIterObject *iter;
...
iter = (PyArrayIterObject *)PyArray_IterNew(obj);
if (iter == NULL) goto fail; /* Assume fail has clean-up code */
while (iter->index < iter->size) {
/* do something with the data at it->dataptr */
PyArray_ITER_NEXT(it);
}
...
你也可以使用PyArrayIter_Check(obj)来确保你有一个迭代器对象和PyArray_ITER_RESET(iter)重置一个迭代器对象返回到数组的开头。
在这一点上应该强调的是,如果你的数组已经是连续的(使用数组迭代器会工作,但会慢于你能写的最快的代码),你可能不需要数组迭代器。数组迭代器的主要目的是将迭代封装在具有任意步幅的N维数组上。它们在NumPy源代码本身的许多地方使用。如果你已经知道你的数组是连续的(Fortran或C),那么只需将元素大小添加到正在运行的指针变量就可以非常有效地引导你完成数组。换句话说,像这样的代码在连续情况下(假设双精度)可能会更快。
npy_intp size;
double *dptr; /* could make this any variable type */
size = PyArray_SIZE(obj);
dptr = PyArray_DATA(obj);
while(size--) {
/* do something with the data at dptr */
dptr++;
}
Iterating over all but one axis¶
一个常见的算法是循环数组的所有元素,并通过发出函数调用对每个元素执行一些函数。由于函数调用可能是耗时的,所以加速这种算法的一种方法是写入函数,使得它采用数据的向量,然后写入迭代,使得对于数据的整个维度一次执行函数调用。这增加了每个函数调用所完成的工作量,从而将函数调用过头减少到总时间的一小部分。即使在没有函数调用的情况下执行循环的内部,可以有利地在具有最大数量的元素的维度上执行内循环,以利用在使用流水线以增强基础操作的微处理器上可用的速度增强。
PyArray_IterAllButAxis(array,&dim)构造了一个迭代器对象,该对象被修改以使其不会遍历dim指示的维度。对这个迭代器对象的唯一限制是,不能使用PyArray_Iter_GOTO1D(it,ind)宏如果你把这个对象传回给Python - 所以你不应该这样做)。注意,从这个例程返回的对象仍然通常转换为PyArrayIterObject *。所有已经做的是修改返回的迭代器的步长和尺寸,以模拟对组合[...,0,...]的迭代,其中0放置在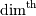 维。如果dim为负,则找到并使用具有最大轴的维度。
维。如果dim为负,则找到并使用具有最大轴的维度。
Iterating over multiple arrays¶
通常,希望在同一时间迭代多个阵列。通用函数是这种行为的一个例子。如果所有你想做的是迭代具有相同形状的数组,那么简单地创建几个迭代器对象是标准的过程。例如,下面的代码迭代两个数组,假定它们是相同的形状和大小(实际上obj1只需要有至少和obj2一样多的元素):
/* It is already assumed that obj1 and obj2
are ndarrays of the same shape and size.
*/
iter1 = (PyArrayIterObject *)PyArray_IterNew(obj1);
if (iter1 == NULL) goto fail;
iter2 = (PyArrayIterObject *)PyArray_IterNew(obj2);
if (iter2 == NULL) goto fail; /* assume iter1 is DECREF'd at fail */
while (iter2->index < iter2->size) {
/* process with iter1->dataptr and iter2->dataptr */
PyArray_ITER_NEXT(iter1);
PyArray_ITER_NEXT(iter2);
}
Broadcasting over multiple arrays¶
当操作中涉及多个数组时,您可能想要使用与数学运算(,即 ufuncs)相同的广播规则。这可以很容易地使用PyArrayMultiIterObjectThis is the object returned from the Python command numpy.broadcast and it is almost as easy to use from C. The function PyArray_MultiIterNew ( n, ... ) is used (with n input objects in place of ... ). 输入对象可以是数组或可以转换为数组的任何内容。返回一个指向PyArrayMultiIterObject的指针。已经完成了广播,其调整迭代器,使得需要完成以前进到每个数组中的下一个元素的是为每个输入调用PyArray_ITER_NEXT。这个递增由PyArray_MultiIter_NEXT(obj)宏(其可以将多元化obj作为PyArrayMultiObject *或PyObject *)。来自输入号i的数据可以使用PyArray_MultiIter_DATA(obj,i)和总作为PyArray_MultiIter_SIZE(obj)。使用此功能的示例如下。
mobj = PyArray_MultiIterNew(2, obj1, obj2);
size = PyArray_MultiIter_SIZE(obj);
while(size--) {
ptr1 = PyArray_MultiIter_DATA(mobj, 0);
ptr2 = PyArray_MultiIter_DATA(mobj, 1);
/* code using contents of ptr1 and ptr2 */
PyArray_MultiIter_NEXT(mobj);
}
函数PyArray_RemoveSmallest(multi)可用于获取多重迭代器对象并调整所有迭代器,以便迭代不会在最大维度上发生(它使得尺寸1)。循环使用指针的代码很可能也需要每个迭代器的步幅数据。此信息存储在multi> iters [i] - > strides中。
在NumPy源代码中使用多重迭代器有几个例子,因为它使得N维广播代码写起来很简单。浏览源代码以获取更多示例。
User-defined data-types¶
NumPy有24个内置数据类型。虽然这覆盖了大多数可能的使用情况,但是可以想到用户可能需要附加的数据类型。有一些支持添加一个额外的数据类型到NumPy系统。这个额外的数据类型将像一个普通的数据类型,除非ufuncs必须有1-d循环注册来单独处理它。另外检查其他数据类型是否可以“安全”铸造和从这个新类型将总是返回“可以转换”除非你还注册哪些类型您的新数据类型可以投入和从。添加数据类型是NumPy 1.0测试不太好的区域之一,因此在该方法中可能存在错误。只有添加一个新的数据类型,如果你不能做你想做的使用已经可用的OBJECT或VOID数据类型。作为我认为添加数据类型的能力的有用应用的示例是向NumPy添加数据类型的任意精度浮点的可能性。
Adding the new data-type¶
要开始使用新的数据类型,您需要首先定义一个新的Python类型来保存新数据类型的标量。如果您的新类型具有二进制兼容布局,则继承其中一个数组标量应该是可以接受的。这将允许您的新数据类型具有数组标量的方法和属性。新的数据类型必须有固定的内存大小(如果你想定义一个需要灵活表示的数据类型,比如一个可变精度的数字,然后使用一个指向对象的指针作为数据类型)。新的Python类型的对象结构的内存布局必须是PyObject_HEAD,后面是数据类型所需的固定大小的内存。例如,新的Python类型的一个合适的结构是:
typedef struct {
PyObject_HEAD;
some_data_type obval;
/* the name can be whatever you want */
} PySomeDataTypeObject;
在你定义了一个新的Python类型对象后,你必须定义一个新的PyArray_Descr结构,其类型成员将包含一个指向你刚定义的数据类型的指针。此外,必须定义“.f”成员中必需的函数:非零,copyswap,copyswapn,setitem,getitem和cast。然而,在“.f”成员中定义的函数越多,新数据类型就越有用。将未使用的函数初始化为NULL非常重要。这可以使用PyArray_InitArrFuncs(f)来实现。
一旦新的PyArray_Descr结构被创建并填充了所需的信息和有用的函数,你调用PyArray_RegisterDataType(new_descr)。此调用的返回值是一个整数,为您提供指定数据类型的唯一type_number。该类型号应该存储并由模块提供,以便其他模块可以使用它来识别您的数据类型(查找用户定义的数据类型号的另一种机制是基于类型的名称进行搜索,使用PyArray_TypeNumFromName)与数据类型相关联的对象。
Registering a casting function¶
您可能希望允许内置(以及其他用户定义的)数据类型自动转换为您的数据类型。为了使这成为可能,你必须注册一个具有你想要能够转换的数据类型的转换函数。这需要为您想要支持的每个转换编写低级别转换函数,然后将这些函数注册到数据类型描述符。低级别的投射功能具有签名。
void castfunc(void * from,void * to,npy_intp n,void * fromarr,void * toarr)将
n元素from投射到to另一种类型。要转换的数据是由连续的,正确交换和对齐的内存块指向的。要转换的缓冲区也是连续的,正确交换和对齐。fromarr和toarr参数只应该用于弹性元素大小的数组(string,unicode,void)。
castfunc的一个示例是:
static void
double_to_float(double *from, float* to, npy_intp n,
void* ig1, void* ig2);
while (n--) {
(*to++) = (double) *(from++);
}
然后可以注册使用代码将双精度转换为浮点数:
doub = PyArray_DescrFromType(NPY_DOUBLE);
PyArray_RegisterCastFunc(doub, NPY_FLOAT,
(PyArray_VectorUnaryFunc *)double_to_float);
Py_DECREF(doub);
Registering coercion rules¶
默认情况下,不假定所有用户定义的数据类型都可安全地转换为任何内置数据类型。此外,内置数据类型不能假定为可安全地转换为用户定义的数据类型。这种情况限制了用户定义的数据类型参与ufuncs使用的强制系统的能力以及在NumPy中发生自动强制时的其他时间。这可以通过将数据类型注册为从特定数据类型对象安全地转换而改变。应该使用函数PyArray_RegisterCanCast(from_descr,totype_number,scalarkind)来指定数据类型对象from_descr可以转换为类型数字为totype_number的数据类型。如果你不试图改变标量强制规则,那么使用NPY_NOSCALAR作为scalarkind参数。
如果你想允许你的新数据类型也能够在标量强制规则中共享,那么你需要在数据类型对象的“.f”成员中指定scalarkind函数,返回新数据类型的标量-type应该被视为(标量的值可用于该函数)。然后,您可以注册可以针对可以从用户定义的数据类型返回的每个标量类型单独转换的数据类型。如果您不注册标量强制处理,则所有用户定义的数据类型将被视为NPY_NOSCALAR。
Registering a ufunc loop¶
你可能还想为数据类型注册低级ufunc循环,以便数据类型的ndarray可以无缝应用数学。注册具有完全相同的arg_types签名的新循环,以静默方式替换该数据类型的任何先前注册的循环。
在您可以为ufunc注册1-d循环之前,必须先创建ufunc。然后你调用PyUFunc_RegisterLoopForType(...)与循环所需的信息。如果进程成功,则此函数的返回值为0,如果未成功,则设置-1的错误条件。
int PyUFunc_RegisterLoopForType(PyUFuncObject * ufunc,int usertype,PyUFuncGenericFunction function,int * arg_types,void * data)ufunc
ufunc要附加此循环。usertype
这个循环的用户定义类型应该在下面索引。此数字必须是用户定义的类型或发生错误。函数
ufunc内1-d循环。此函数必须具有如3节中所述的签名。arg_types
(可选)如果给定,则应包含至少为size ufunc.nargs的整数数组,其中包含循环函数期望的数据类型。数据将被复制到NumPy管理的结构中,因此在调用此函数后应删除此参数的内存。如果这是NULL,那么将假定所有数据类型都是usertype类型。data
(可选)指定调用函数时将传递的函数所需的任何可选数据。
Subtyping the ndarray in C¶
从2.2开始,在Python中潜伏的一个较少使用的功能是C中的子类类型的能力。这个功能是使NumPy基于已经在C中的数字代码库的重要原因之一。 C中的子类型在内存管理方面允许更多的灵活性。C中的子类型并不困难,即使你只有一个初步的了解如何为Python创建新的类型。尽管从单个父类型进行子类型化最容易,但也可以从多个父类型进行子类型化。C中的多重继承通常比Python中的有用,因为对Python子类型的限制是它们具有二进制兼容的内存布局。也许因为这个原因,从单个父类型子类型更容易一些。
对应于Python对象的所有C结构必须以PyObject_HEAD(或PyObject_VAR_HEAD)开头。以相同的方式,任何子类型必须具有以与父类型(或在多重继承的情况下的所有父类型)完全相同的存储器布局开始的C结构。这样做的原因是Python可能试图访问子类型结构的成员,如同它具有父结构(ie),它会将一个指针转换为指向父结构的指针,然后取消引用其成员之一)。如果内存布局不兼容,则此尝试将导致不可预测的行为(最终导致内存违规和程序崩溃)。
PyObject_HEAD中的一个元素是指向类型对象结构的指针。一个新的Python类型是通过创建一个新的类型对象结构并用函数和指针来描述类型的期望行为来创建的。通常,还创建新的C结构以包含该类型的每个对象所需的实例特定信息。例如,&PyArray_Type是指向ndarray的类型对象表的指针,而PyArrayObject *变量是指向ndarray的特定实例的指针(ndarray结构的成员之一是指向类型 - 对象表&PyArray_Type的指针)。最后,对于每个新的Python类型,必须调用PyType_Ready(
Creating sub-types¶
要创建子类型,必须遵循类似的过程,只有不同的行为需要在类型 - 对象结构中有新的条目。所有其他entires可以为NULL,并且将由父类型的适当函数填充PyType_Ready。特别地,要在C中创建子类型,请按照下列步骤操作:
如果需要创建一个新的C结构来处理你的类型的每个实例。典型的C结构是:
typedef _new_struct { PyArrayObject base; /* new things here */ } NewArrayObject;
请注意,完整的PyArrayObject用作第一个条目,以确保新类型的实例的二进制布局与PyArrayObject相同。
填写一个新的Python类型对象结构,指向新函数的指针将覆盖默认行为,同时保留任何应该保持相同的未填充(或NULL)的函数。tp_name元素应该不同。
使用指向(主)父类型对象的指针填充新类型对象结构的tp_base成员。对于多重继承,还要用包含所有父对象的元组填充tp_bases成员,它们应该用于定义继承。记住,所有父类型必须具有相同的C结构,以便多重继承正常工作。
调用
PyType_Ready()。 如果此函数返回负数,则发生故障,并且类型未初始化。否则,类型可以使用。通常重要的是将新类型的引用放入模块字典中,以便可以从Python访问它。
有关在C中创建子类型的更多信息,可以通过阅读PEP 253(可在http://www.python.org/dev/peps/pep-0253)获取。
Specific features of ndarray sub-typing¶
一些特殊的方法和属性由数组使用,以便于子类型与基本ndarray类型的互操作。
The __array_finalize__ method¶
-
ndarray.__array_finalize__¶ ndarray的几个数组创建函数允许指定要创建的特定子类型。这允许子类型在许多例程中无缝地处理。然而,当以这种方式创建子类型时,不会调用__new__方法和__init__方法。相反,分配子类型并填充适当的实例结构成员。最后,在对象字典中查找
__array_finalize__属性。如果它存在而不是None,那么它可以是包含指向PyArray_FinalizeFunc的指针的CObject,或者它可以是一个接受单个参数(可以是None)的方法。如果
__array_finalize__属性是CObject,则指针必须是具有签名的函数的指针:(int) (PyArrayObject *, PyObject *)
第一个参数是新建的子类型。第二个参数(如果不是NULL)是“父”数组(如果数组是使用切片或一些其他操作创建的,其中存在明显可区分的父)。这个例程可以做任何它想要的。它应该返回-1的错误,否则返回0。
如果
__array_finalize__属性不是None,也不是CObject,那么它必须是一个以父数组作为参数的Python方法(如果没有父对象,可以为None),并且不返回任何内容。此方法中的错误将被捕获和处理。
The __array_priority__ attribute¶
-
ndarray.__array_priority__¶ 当涉及两个或更多个子类型的操作出现时,该属性允许简单但灵活地确定哪个子类型应当被认为是“主要”。在使用不同子类型的操作中,具有最大
__array_priority__属性的子类型将确定输出的子类型。如果两个子类型具有相同的__array_priority__,则第一个参数的子类型确定输出。默认的__array_priority__属性返回值为基准ndarray类型的值0.0和子类型的值1.0。此属性还可以由不是ndarray的子类型的对象定义,并且可以用于确定应该为返回输出调用__array_wrap__方法。
The __array_wrap__ method¶
-
ndarray.__array_wrap__¶ 任何类或类型都可以定义此方法,该方法应该使用ndarray参数并返回类型的实例。它可以看作与
__array__方法相反。这个方法由ufuncs(和其他NumPy函数)使用,允许其他对象通过。对于Python> 2.4,它也可以用于编写一个装饰器,它将只能使用ndarrays的函数转换为使用__array__和__array_wrap__方法的任何类型的函数。