Variables
Note: Functions taking Tensor arguments can also take anything accepted by
tf.convert_to_tensor.
Contents
Variables
- Variables
- Variable helper functions
- Saving and Restoring Variables
- Sharing Variables
tf.get_variable(name, shape=None, dtype=tf.float32, initializer=None, trainable=True, collections=None)tf.get_variable_scope()tf.variable_scope(name_or_scope, reuse=None, initializer=None)tf.constant_initializer(value=0.0)tf.random_normal_initializer(mean=0.0, stddev=1.0, seed=None)tf.truncated_normal_initializer(mean=0.0, stddev=1.0, seed=None)tf.random_uniform_initializer(minval=0.0, maxval=1.0, seed=None)tf.uniform_unit_scaling_initializer(factor=1.0, seed=None)tf.zeros_initializer(shape, dtype=tf.float32)
- Sparse Variable Updates
Variables
class tf.Variable
See the Variables How To for a high level overview.
A variable maintains state in the graph across calls to run(). You add a
variable to the graph by constructing an instance of the class Variable.
The Variable() constructor requires an initial value for the variable,
which can be a Tensor of any type and shape. The initial value defines the
type and shape of the variable. After construction, the type and shape of
the variable are fixed. The value can be changed using one of the assign
methods.
If you want to change the shape of a variable later you have to use an
assign Op with validate_shape=False.
Just like any Tensor, variables created with Variable() can be used as
inputs for other Ops in the graph. Additionally, all the operators
overloaded for the Tensor class are carried over to variables, so you can
also add nodes to the graph by just doing arithmetic on variables.
import tensorflow as tf
# Create a variable.
w = tf.Variable(<initial-value>, name=<optional-name>)
# Use the variable in the graph like any Tensor.
y = tf.matmul(w, ...another variable or tensor...)
# The overloaded operators are available too.
z = tf.sigmoid(w + b)
# Assign a new value to the variable with `assign()` or a related method.
w.assign(w + 1.0)
w.assign_add(1.0)
When you launch the graph, variables have to be explicitly initialized before
you can run Ops that use their value. You can initialize a variable by
running its initializer op, restoring the variable from a save file, or
simply running an assign Op that assigns a value to the variable. In fact,
the variable initializer op is just an assign Op that assigns the
variable's initial value to the variable itself.
# Launch the graph in a session.
with tf.Session() as sess:
# Run the variable initializer.
sess.run(w.initializer)
# ...you now can run ops that use the value of 'w'...
The most common initialization pattern is to use the convenience function
initialize_all_variables() to add an Op to the graph that initializes
all the variables. You then run that Op after launching the graph.
# Add an Op to initialize all variables.
init_op = tf.initialize_all_variables()
# Launch the graph in a session.
with tf.Session() as sess:
# Run the Op that initializes all variables.
sess.run(init_op)
# ...you can now run any Op that uses variable values...
If you need to create a variable with an initial value dependent on another
variable, use the other variable's initialized_value(). This ensures that
variables are initialized in the right order.
All variables are automatically collected in the graph where they are
created. By default, the constructor adds the new variable to the graph
collection GraphKeys.VARIABLES. The convenience function
all_variables() returns the contents of that collection.
When building a machine learning model it is often convenient to distinguish
betwen variables holding the trainable model parameters and other variables
such as a global step variable used to count training steps. To make this
easier, the variable constructor supports a trainable=<bool> parameter. If
True, the new variable is also added to the graph collection
GraphKeys.TRAINABLE_VARIABLES. The convenience function
trainable_variables() returns the contents of this collection. The
various Optimizer classes use this collection as the default list of
variables to optimize.
Creating a variable.
tf.Variable.__init__(initial_value, trainable=True, collections=None, validate_shape=True, name=None)
Creates a new variable with value initial_value.
The new variable is added to the graph collections listed in collections,
which defaults to [GraphKeys.VARIABLES].
If trainable is True the variable is also added to the graph collection
GraphKeys.TRAINABLE_VARIABLES.
This constructor creates both a variable Op and an assign Op to set the
variable to its initial value.
Args:
initial_value: ATensor, or Python object convertible to aTensor. The initial value for the Variable. Must have a shape specified unlessvalidate_shapeis set to False.trainable: IfTrue, the default, also adds the variable to the graph collectionGraphKeys.TRAINABLE_VARIABLES. This collection is used as the default list of variables to use by theOptimizerclasses.collections: List of graph collections keys. The new variable is added to these collections. Defaults to[GraphKeys.VARIABLES].validate_shape: IfFalse, allows the variable to be initialized with a value of unknown shape. IfTrue, the default, the shape ofinitial_valuemust be known.name: Optional name for the variable. Defaults to'Variable'and gets uniquified automatically.
Returns:
A Variable.
Raises:
ValueError: If the initial value does not have a shape andvalidate_shapeisTrue.
tf.Variable.initialized_value()
Returns the value of the initialized variable.
You should use this instead of the variable itself to initialize another variable with a value that depends on the value of this variable.
# Initialize 'v' with a random tensor.
v = tf.Variable(tf.truncated_normal([10, 40]))
# Use `initialized_value` to guarantee that `v` has been
# initialized before its value is used to initialize `w`.
# The random values are picked only once.
w = tf.Variable(v.initialized_value() * 2.0)
Returns:
A Tensor holding the value of this variable after its initializer
has run.
Changing a variable value.
tf.Variable.assign(value, use_locking=False)
Assigns a new value to the variable.
This is essentially a shortcut for assign(self, value).
Args:
value: ATensor. The new value for this variable.use_locking: IfTrue, use locking during the assignment.
Returns:
A Tensor that will hold the new value of this variable after
the assignment has completed.
tf.Variable.assign_add(delta, use_locking=False)
Adds a value to this variable.
This is essentially a shortcut for assign_add(self, delta).
Args:
delta: ATensor. The value to add to this variable.use_locking: IfTrue, use locking during the operation.
Returns:
A Tensor that will hold the new value of this variable after
the addition has completed.
tf.Variable.assign_sub(delta, use_locking=False)
Subtracts a value from this variable.
This is essentially a shortcut for assign_sub(self, delta).
Args:
delta: ATensor. The value to subtract from this variable.use_locking: IfTrue, use locking during the operation.
Returns:
A Tensor that will hold the new value of this variable after
the subtraction has completed.
tf.Variable.scatter_sub(sparse_delta, use_locking=False)
Subtracts IndexedSlices from this variable.
This is essentially a shortcut for scatter_sub(self, sparse_delta.indices,
sparse_delta.values).
Args:
sparse_delta:IndexedSlicesto be subtracted from this variable.use_locking: IfTrue, use locking during the operation.
Returns:
A Tensor that will hold the new value of this variable after
the scattered subtraction has completed.
Raises:
ValueError: ifsparse_deltais not anIndexedSlices.
tf.Variable.count_up_to(limit)
Increments this variable until it reaches limit.
When that Op is run it tries to increment the variable by 1. If
incrementing the variable would bring it above limit then the Op raises
the exception OutOfRangeError.
If no error is raised, the Op outputs the value of the variable before the increment.
This is essentially a shortcut for count_up_to(self, limit).
Args:
limit: value at which incrementing the variable raises an error.
Returns:
A Tensor that will hold the variable value before the increment. If no
other Op modifies this variable, the values produced will all be
distinct.
tf.Variable.eval(session=None)
In a session, computes and returns the value of this variable.
This is not a graph construction method, it does not add ops to the graph.
This convenience method requires a session where the graph containing this variable has been launched. If no session is passed, the default session is used. See the Session class for more information on launching a graph and on sessions.
v = tf.Variable([1, 2])
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
# Usage passing the session explicitly.
print v.eval(sess)
# Usage with the default session. The 'with' block
# above makes 'sess' the default session.
print v.eval()
Args:
session: The session to use to evaluate this variable. If none, the default session is used.
Returns:
A numpy ndarray with a copy of the value of this variable.
Properties.
tf.Variable.name
The name of this variable.
tf.Variable.dtype
The DType of this variable.
tf.Variable.get_shape()
The TensorShape of this variable.
Returns:
A TensorShape.
tf.Variable.device
The device of this variable.
tf.Variable.initializer
The initializer operation for this variable.
tf.Variable.graph
The Graph of this variable.
tf.Variable.op
The Operation of this variable.
Variable helper functions
TensorFlow provides a set of functions to help manage the set of variables collected in the graph.
tf.all_variables()
Returns all variables collected in the graph.
The Variable() constructor automatically adds new variables to the graph
collection GraphKeys.VARIABLES. This convenience function returns the
contents of that collection.
Returns:
A list of Variable objects.
tf.trainable_variables()
Returns all variables created with trainable=True.
When passed trainable=True, the Variable() constructor automatically
adds new variables to the graph collection
GraphKeys.TRAINABLE_VARIABLES. This convenience function returns the
contents of that collection.
Returns:
A list of Variable objects.
tf.initialize_all_variables()
Returns an Op that initializes all variables.
This is just a shortcut for initialize_variables(all_variables())
Returns:
An Op that initializes all variables in the graph.
tf.initialize_variables(var_list, name='init')
Returns an Op that initializes a list of variables.
After you launch the graph in a session, you can run the returned Op to
initialize all the variables in var_list. This Op runs all the
initializers of the variables in var_list in parallel.
Calling initialize_variables() is equivalent to passing the list of
initializers to Group().
If var_list is empty, however, the function still returns an Op that can
be run. That Op just has no effect.
Args:
var_list: List ofVariableobjects to initialize.name: Optional name for the returned operation.
Returns:
An Op that run the initializers of all the specified variables.
tf.assert_variables_initialized(var_list=None)
Returns an Op to check if variables are initialized.
When run, the returned Op will raise the exception FailedPreconditionError
if any of the variables has not yet been initialized.
Note: This function is implemented by trying to fetch the values of the variables. If one of the variables is not initialized a message may be logged by the C++ runtime. This is expected.
Args:
var_list: List ofVariableobjects to check. Defaults to the value ofall_variables().
Returns:
An Op, or None if there are no variables.
Saving and Restoring Variables
class tf.train.Saver
Saves and restores variables.
See Variables for an overview of variables, saving and restoring.
The Saver class adds ops to save and restore variables to and from
checkpoints. It also provides convenience methods to run these ops.
Checkpoints are binary files in a proprietary format which map variable names
to tensor values. The best way to examine the contents of a checkpoint is to
load it using a Saver.
Savers can automatically number checkpoint filenames with a provided counter. This lets you keep multiple checkpoints at different steps while training a model. For example you can number the checkpoint filenames with the training step number. To avoid filling up disks, savers manage checkpoint files automatically. For example, they can keep only the N most recent files, or one checkpoint for every N hours of training.
You number checkpoint filenames by passing a value to the optional
global_step argument to save():
saver.save(sess, 'my-model', global_step=0) ==> filename: 'my-model-0'
...
saver.save(sess, 'my-model', global_step=1000) ==> filename: 'my-model-1000'
Additionally, optional arguments to the Saver() constructor let you control
the proliferation of checkpoint files on disk:
max_to_keepindicates the maximum number of recent checkpoint files to keep. As new files are created, older files are deleted. If None or 0, all checkpoint files are kept. Defaults to 5 (that is, the 5 most recent checkpoint files are kept.)keep_checkpoint_every_n_hours: In addition to keeping the most recentmax_to_keepcheckpoint files, you might want to keep one checkpoint file for every N hours of training. This can be useful if you want to later analyze how a model progressed during a long training session. For example, passingkeep_checkpoint_every_n_hours=2ensures that you keep one checkpoint file for every 2 hours of training. The default value of 10,000 hours effectively disables the feature.
Note that you still have to call the save() method to save the model.
Passing these arguments to the constructor will not save variables
automatically for you.
A training program that saves regularly looks like:
...
# Create a saver.
saver = tf.train.Saver(...variables...)
# Launch the graph and train, saving the model every 1,000 steps.
sess = tf.Session()
for step in xrange(1000000):
sess.run(..training_op..)
if step % 1000 == 0:
# Append the step number to the checkpoint name:
saver.save(sess, 'my-model', global_step=step)
In addition to checkpoint files, savers keep a protocol buffer on disk with
the list of recent checkpoints. This is used to manage numbered checkpoint
files and by latest_checkpoint(), which makes it easy to discover the path
to the most recent checkpoint. That protocol buffer is stored in a file named
'checkpoint' next to the checkpoint files.
If you create several savers, you can specify a different filename for the
protocol buffer file in the call to save().
tf.train.Saver.__init__(var_list=None, reshape=False, sharded=False, max_to_keep=5, keep_checkpoint_every_n_hours=10000.0, name=None, restore_sequentially=False, saver_def=None, builder=None)
Creates a Saver.
The constructor adds ops to save and restore variables.
var_list specifies the variables that will be saved and restored. It can
be passed as a dict or a list:
- A
dictof names to variables: The keys are the names that will be used to save or restore the variables in the checkpoint files. - A list of variables: The variables will be keyed with their op name in the checkpoint files.
For example:
v1 = tf.Variable(..., name='v1')
v2 = tf.Variable(..., name='v2')
# Pass the variables as a dict:
saver = tf.train.Saver({'v1': v1, 'v2': v2})
# Or pass them as a list.
saver = tf.train.Saver([v1, v2])
# Passing a list is equivalent to passing a dict with the variable op names
# as keys:
saver = tf.train.Saver({v.op.name: v for v in [v1, v2]})
The optional reshape argument, if True, allows restoring a variable from
a save file where the variable had a different shape, but the same number
of elements and type. This is useful if you have reshaped a variable and
want to reload it from an older checkpoint.
The optional sharded argument, if True, instructs the saver to shard
checkpoints per device.
Args:
var_list: A list of Variables or a dictionary mapping names to Variables. If None, defaults to the list of all variables.reshape: If True, allows restoring parameters from a checkpoint where the variables have a different shape.sharded: If True, shard the checkpoints, one per device.max_to_keep: maximum number of recent checkpoints to keep. Defaults to 10,000 hours.keep_checkpoint_every_n_hours: How often to keep checkpoints. Defaults to 10,000 hours.name: string. Optional name to use as a prefix when adding operations.restore_sequentially: A Bool, which if true, causes restore of different variables to happen sequentially within each device. This can lower memory usage when restoring very large models.saver_def: Optional SaverDef proto to use instead of running the builder. This is only useful for specialty code that wants to recreate a Saver object for a previously built Graph that had a Saver. The saver_def proto should be the one returned by the as_saver_def() call of the Saver that was created for that Graph.builder: Optional SaverBuilder to use if a saver_def was not provided. Defaults to BaseSaverBuilder().
Raises:
TypeError: Ifvar_listis invalid.ValueError: If any of the keys or values invar_listis not unique.
tf.train.Saver.save(sess, save_path, global_step=None, latest_filename=None)
Saves variables.
This method runs the ops added by the constructor for saving variables. It requires a session in which the graph was launched. The variables to save must also have been initialized.
The method returns the path of the newly created checkpoint file. This
path can be passed directly to a call to restore().
Args:
sess: A Session to use to save the variables.save_path: string. Path to the checkpoint filename. If the saver issharded, this is the prefix of the sharded checkpoint filename.global_step: If provided the global step number is appended tosave_pathto create the checkpoint filename. The optional argument can be a Tensor, a Tensor name or an integer.latest_filename: Optional name for the protocol buffer file that will contains the list of most recent checkpoint filenames. That file, kept in the same directory as the checkpoint files, is automatically managed by the saver to keep track of recent checkpoints. Defaults to 'checkpoint'.
Returns:
A string: path at which the variables were saved. If the saver is sharded, this string ends with: '-?????-of-nnnnn' where 'nnnnn' is the number of shards created.
Raises:
TypeError: Ifsessis not a Session.
tf.train.Saver.restore(sess, save_path)
Restores previously saved variables.
This method runs the ops added by the constructor for restoring variables. It requires a session in which the graph was launched. The variables to restore do not have to have been initialized, as restoring is itself a way to initialize variables.
The save_path argument is typically a value previously returned from a
save() call, or a call to latest_checkpoint().
Args:
sess: A Session to use to restore the parameters.save_path: Path where parameters were previously saved.
Other utility methods.
tf.train.Saver.last_checkpoints
List of not-yet-deleted checkpoint filenames.
You can pass any of the returned values to restore().
Returns:
A list of checkpoint filenames, sorted from oldest to newest.
tf.train.Saver.set_last_checkpoints(last_checkpoints)
Sets the list of not-yet-deleted checkpoint filenames.
Args:
last_checkpoints: a list of checkpoint filenames.
Raises:
AssertionError: if the list of checkpoint filenames has already been set.
tf.train.Saver.as_saver_def()
Generates a SaverDef representation of this saver.
Returns:
A SaverDef proto.
tf.train.latest_checkpoint(checkpoint_dir, latest_filename=None)
Finds the filename of latest saved checkpoint file.
Args:
checkpoint_dir: Directory where the variables were saved.latest_filename: Optional name for the protocol buffer file that contains the list of most recent checkpoint filenames. See the corresponding argument toSaver.save().
Returns:
The full path to the latest checkpoint or None if no checkpoint was found.
tf.train.get_checkpoint_state(checkpoint_dir, latest_filename=None)
Returns CheckpointState proto from the "checkpoint" file.
If the "checkpoint" file contains a valid CheckpointState proto, returns it.
Args:
checkpoint_dir: The directory of checkpoints.latest_filename: Optional name of the checkpoint file. Default to 'checkpoint'.
Returns:
A CheckpointState if the state was available, None otherwise.
tf.train.update_checkpoint_state(save_dir, model_checkpoint_path, all_model_checkpoint_paths=None, latest_filename=None)
Updates the content of the 'checkpoint' file.
This updates the checkpoint file containing a CheckpointState proto.
Args:
save_dir: Directory where the model was saved.model_checkpoint_path: The checkpoint file.all_model_checkpoint_paths: list of strings. Paths to all not-yet-deleted checkpoints, sorted from oldest to newest. If this is a non-empty list, the last element must be equal to model_checkpoint_path. These paths are also saved in the CheckpointState proto.latest_filename: Optional name of the checkpoint file. Default to 'checkpoint'.
Raises:
RuntimeError: If the save paths conflict.
Sharing Variables
TensorFlow provides several classes and operations that you can use to create variables contingent on certain conditions.
tf.get_variable(name, shape=None, dtype=tf.float32, initializer=None, trainable=True, collections=None)
Gets an existing variable with these parameters or create a new one.
This function prefixes the name with the current variable scope and performs reuse checks. See the Variable Scope How To for an extensive description of how reusing works. Here is a basic example:
with tf.variable_scope("foo"):
v = get_variable("v", [1]) # v.name == "foo/v:0"
w = get_variable("w", [1]) # w.name == "foo/w:0"
with tf.variable_scope("foo", reuse=True)
v1 = get_variable("v") # The same as v above.
If initializer is None (the default), the default initializer passed in
the constructor is used. If that one is None too, a
UniformUnitScalingInitializer will be used.
Args:
name: the name of the new or existing variable.shape: shape of the new or existing variable.dtype: type of the new or existing variable (defaults toDT_FLOAT).initializer: initializer for the variable if one is created.trainable: IfTruealso add the variable to the graph collectionGraphKeys.TRAINABLE_VARIABLES(see variables.Variable).collections: List of graph collections keys to add the Variable to. Defaults to[GraphKeys.VARIABLES](see variables.Variable).
Returns:
The created or existing variable.
Raises:
ValueError: when creating a new variable and shape is not declared, or when violating reuse during variable creation. Reuse is set insidevariable_scope.
tf.get_variable_scope()
Returns the current variable scope.
tf.variable_scope(name_or_scope, reuse=None, initializer=None)
Returns a context for variable scope.
Variable scope allows to create new variables and to share already created ones while providing checks to not create or share by accident. For details, see the Variable Scope How To, here we present only a few basic examples.
Simple example of how to create a new variable:
with tf.variable_scope("foo"):
with tf.variable_scope("bar"):
v = tf.get_variable("v", [1])
assert v.name == "foo/bar/v:0"
Basic example of sharing a variable:
with tf.variable_scope("foo"):
v = get_variable("v", [1])
with tf.variable_scope("foo", reuse=True):
v1 = tf.get_variable("v", [1])
assert v1 == v
Sharing a variable by capturing a scope and setting reuse:
with tf.variable_scope("foo") as scope.
v = get_variable("v", [1])
scope.reuse_variables()
v1 = tf.get_variable("v", [1])
assert v1 == v
To prevent accidental sharing of variables, we raise an exception when getting an existing variable in a non-reusing scope.
with tf.variable_scope("foo") as scope.
v = get_variable("v", [1])
v1 = tf.get_variable("v", [1])
# Raises ValueError("... v already exists ...").
Similarly, we raise an exception when trying to get a variable that does not exist in reuse mode.
with tf.variable_scope("foo", reuse=True):
v = get_variable("v", [1])
# Raises ValueError("... v does not exists ...").
Note that the reuse flag is inherited: if we open a reusing scope,
then all its sub-scopes become reusing as well.
Args:
name_or_scope:stringorVariableScope: the scope to open.reuse:TrueorNone; ifTrue, we go into reuse mode for this scope as well as all sub-scopes; ifNone, we just inherit the parent scope reuse.initializer: default initializer for variables within this scope.
Yields:
A scope that can be to captured and reused.
Raises:
ValueError: when trying to reuse within a create scope, or create within a reuse scope, or if reuse is notNoneorTrue.TypeError: when the types of some arguments are not appropriate.
tf.constant_initializer(value=0.0)
Returns an initializer that generates Tensors with a single value.
Args:
value: A Python scalar. All elements of the initialized variable will be set to this value.
Returns:
An initializer that generates Tensors with a single value.
tf.random_normal_initializer(mean=0.0, stddev=1.0, seed=None)
Returns an initializer that generates Tensors with a normal distribution.
Args:
mean: a python scalar or a scalar tensor. Mean of the random values to generate.stddev: a python scalar or a scalar tensor. Standard deviation of the random values to generate.seed: A Python integer. Used to create random seeds. Seeset_random_seedfor behavior.
Returns:
An initializer that generates Tensors with a normal distribution.
tf.truncated_normal_initializer(mean=0.0, stddev=1.0, seed=None)
Returns an initializer that generates a truncated normal distribution.
These values are similar to values from a random_normal_initializer except that values more than two standard deviations from the mean are discarded and re-drawn. This is the recommended initializer for neural network weights and filters.
Args:
mean: a python scalar or a scalar tensor. Mean of the random values to generate.stddev: a python scalar or a scalar tensor. Standard deviation of the random values to generate.seed: A Python integer. Used to create random seeds. Seeset_random_seedfor behavior.
Returns:
An initializer that generates Tensors with a truncated normal distribution.
tf.random_uniform_initializer(minval=0.0, maxval=1.0, seed=None)
Returns an initializer that generates Tensors with a uniform distribution.
Args:
minval: a python scalar or a scalar tensor. lower bound of the range of random values to generate.maxval: a python scalar or a scalar tensor. upper bound of the range of random values to generate.seed: A Python integer. Used to create random seeds. Seeset_random_seedfor behavior.
Returns:
An initializer that generates Tensors with a uniform distribution.
tf.uniform_unit_scaling_initializer(factor=1.0, seed=None)
Returns an initializer that generates tensors without scaling variance.
When initializing a deep network, it is in principle advantageous to keep
the scale of the input variance constant, so it does not explode or diminish
by reaching the final layer. If the input is x and the operation x * W,
and we want to initialize W uniformly at random, we need to pick W from
[-sqrt(3) / sqrt(dim), sqrt(3) / sqrt(dim)]
to keep the scale intact, where dim = W.shape[0] (the size of the input).
A similar calculation for convolutional networks gives an analogous result
with dim equal to the product of the first 3 dimensions. When
nonlinearities are present, we need to multiply this by a constant factor.
See https://arxiv.org/pdf/1412.6558v3.pdf for deeper motivation, experiments
and the calculation of constants. In section 2.3 there, the constants were
numerically computed: for a linear layer it's 1.0, relu: ~1.43, tanh: ~1.15.
Args:
factor: Float. A multiplicative factor by which the values will be scaled.seed: A Python integer. Used to create random seeds. Seeset_random_seedfor behavior.
Returns:
An initializer that generates tensors with unit variance.
tf.zeros_initializer(shape, dtype=tf.float32)
An adaptor for zeros() to match the Initializer spec.
Sparse Variable Updates
The sparse update ops modify a subset of the entries in a dense Variable,
either overwriting the entries or adding / subtracting a delta. These are
useful for training embedding models and similar lookup-based networks, since
only a small subset of embedding vectors change in any given step.
Since a sparse update of a large tensor may be generated automatically during
gradient computation (as in the gradient of
tf.gather),
an IndexedSlices class is provided that encapsulates a set
of sparse indices and values. IndexedSlices objects are detected and handled
automatically by the optimizers in most cases.
tf.scatter_update(ref, indices, updates, use_locking=None, name=None)
Applies sparse updates to a variable reference.
This operation computes
# Scalar indices
ref[indices, ...] = updates[...]
# Vector indices (for each i)
ref[indices[i], ...] = updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] = updates[i, ..., j, ...]
This operation outputs ref after the update is done.
This makes it easier to chain operations that need to use the reset value.
If indices contains duplicate entries, lexicographically later entries
override earlier entries.
Requires updates.shape = indices.shape + ref.shape[1:].
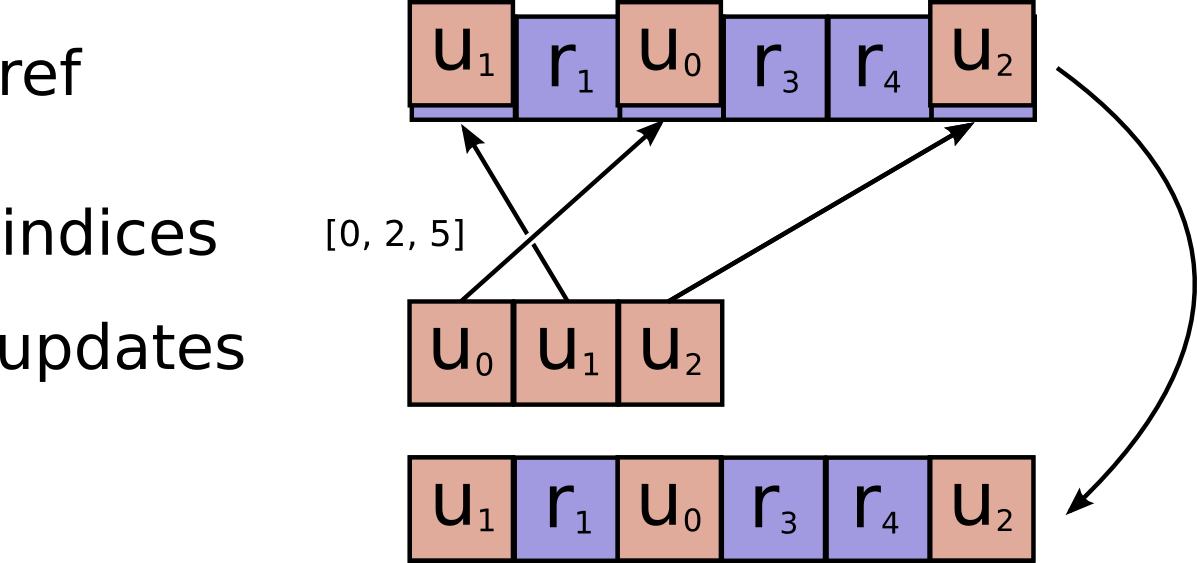
Args:
ref: A mutableTensor. Should be from aVariablenode.indices: ATensor. Must be one of the following types:int32,int64. A tensor of indices into the first dimension ofref.updates: ATensor. Must have the same type asref. A tensor of updated values to store inref.use_locking: An optionalbool. Defaults toTrue. If True, the assignment will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.name: A name for the operation (optional).
Returns:
Same as ref. Returned as a convenience for operations that want
to use the updated values after the update is done.
tf.scatter_add(ref, indices, updates, use_locking=None, name=None)
Adds sparse updates to a variable reference.
This operation computes
# Scalar indices
ref[indices, ...] += updates[...]
# Vector indices (for each i)
ref[indices[i], ...] += updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] += updates[i, ..., j, ...]
This operation outputs ref after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple indices reference
the same location, their contributions add.
Requires updates.shape = indices.shape + ref.shape[1:].
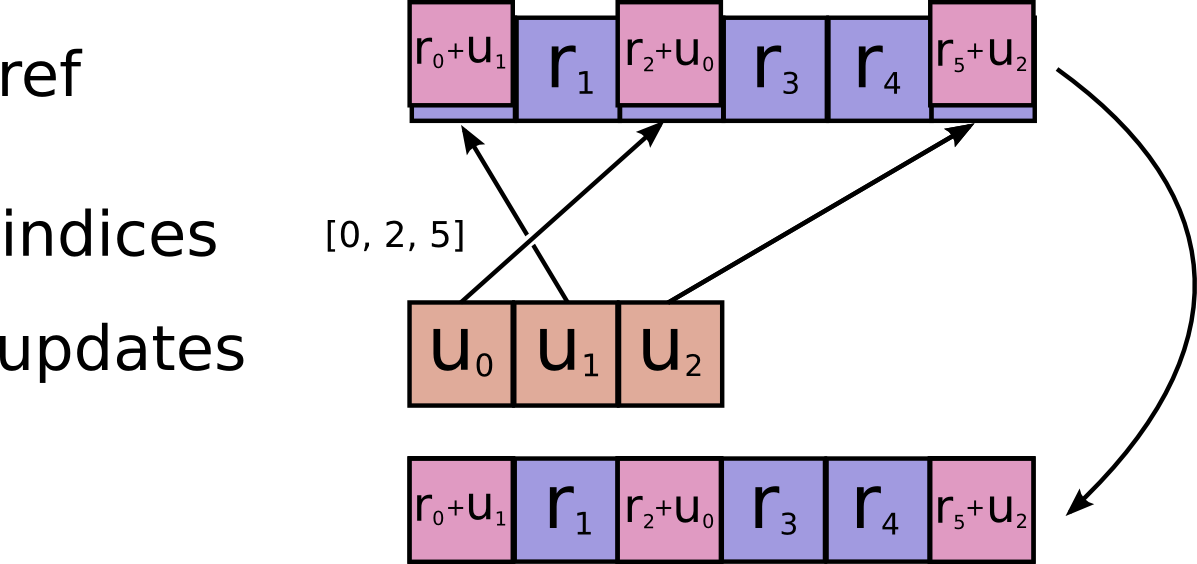
Args:
ref: A mutableTensor. Must be one of the following types:float32,float64,int64,int32,uint8,int16,int8,complex64,qint8,quint8,qint32. Should be from aVariablenode.indices: ATensor. Must be one of the following types:int32,int64. A tensor of indices into the first dimension ofref.updates: ATensor. Must have the same type asref. A tensor of updated values to add toref.use_locking: An optionalbool. Defaults toFalse. If True, the addition will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.name: A name for the operation (optional).
Returns:
Same as ref. Returned as a convenience for operations that want
to use the updated values after the update is done.
tf.scatter_sub(ref, indices, updates, use_locking=None, name=None)
Subtracts sparse updates to a variable reference.
# Scalar indices
ref[indices, ...] -= updates[...]
# Vector indices (for each i)
ref[indices[i], ...] -= updates[i, ...]
# High rank indices (for each i, ..., j)
ref[indices[i, ..., j], ...] -= updates[i, ..., j, ...]
This operation outputs ref after the update is done.
This makes it easier to chain operations that need to use the reset value.
Duplicate entries are handled correctly: if multiple indices reference
the same location, their (negated) contributions add.
Requires updates.shape = indices.shape + ref.shape[1:].
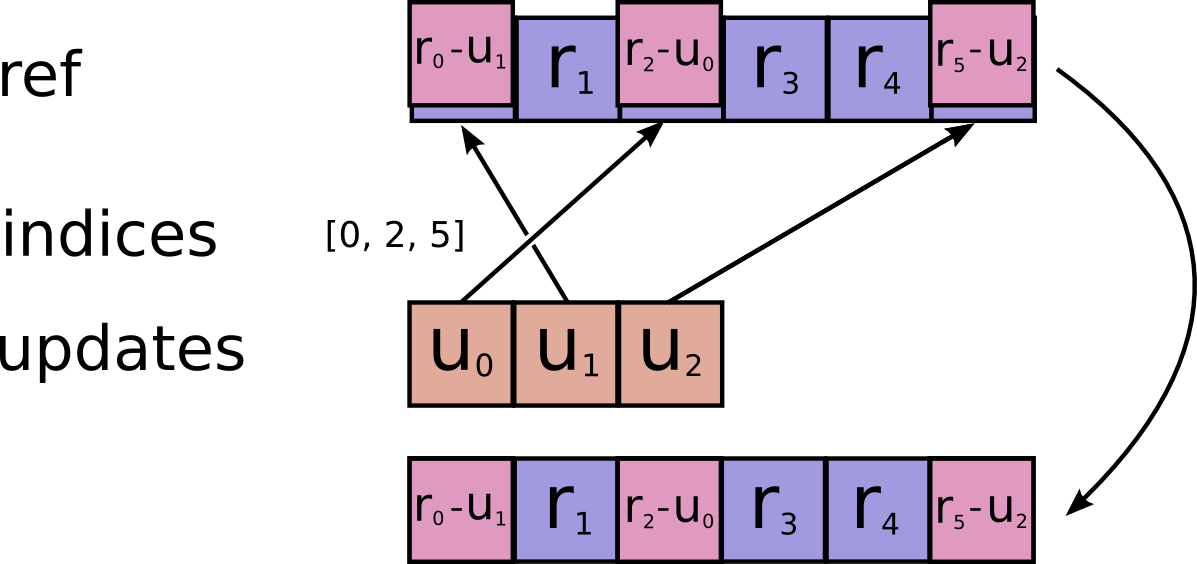
Args:
ref: A mutableTensor. Must be one of the following types:float32,float64,int64,int32,uint8,int16,int8,complex64,qint8,quint8,qint32. Should be from aVariablenode.indices: ATensor. Must be one of the following types:int32,int64. A tensor of indices into the first dimension ofref.updates: ATensor. Must have the same type asref. A tensor of updated values to subtract fromref.use_locking: An optionalbool. Defaults toFalse. If True, the subtraction will be protected by a lock; otherwise the behavior is undefined, but may exhibit less contention.name: A name for the operation (optional).
Returns:
Same as ref. Returned as a convenience for operations that want
to use the updated values after the update is done.
tf.sparse_mask(a, mask_indices, name=None)
Masks elements of IndexedSlices.
Given an IndexedSlices instance a, returns another IndexedSlices that
contains a subset of the slices of a. Only the slices at indices specified
in mask_indices are returned.
This is useful when you need to extract a subset of slices in an
IndexedSlices object.
For example:
# `a` contains slices at indices [12, 26, 37, 45] from a large tensor
# with shape [1000, 10]
a.indices => [12, 26, 37, 45]
tf.shape(a.values) => [4, 10]
# `b` will be the subset of `a` slices at its second and third indices, so
# we want to mask of its first and last indices (which are at absolute
# indices 12, 45)
b = tf.sparse_mask(a, [12, 45])
b.indices => [26, 37]
tf.shape(b.values) => [2, 10]
Args:
a: AnIndexedSlicesinstance.mask_indices: Indices of elements to mask.name: A name for the operation (optional).
Returns:
The masked IndexedSlices instance.
class tf.IndexedSlices
A sparse representation of a set of tensor slices at given indices.
This class is a simple wrapper for a pair of Tensor objects:
values: ATensorof any dtype with shape[D0, D1, ..., Dn].indices: A 1-D integerTensorwith shape[D0].
An IndexedSlices is typically used to represent a subset of a larger
tensor dense of shape [LARGE0, D1, .. , DN] where LARGE0 >> D0.
The values in indices are the indices in the first dimension of
the slices that have been extracted from the larger tensor.
The dense tensor dense represented by an IndexedSlices slices has
dense[slices.indices[i], :, :, :, ...] = slices.values[i, :, :, :, ...]
The IndexedSlices class is used principally in the definition of
gradients for operations that have sparse gradients
(e.g. tf.gather).
Contrast this representation with
SparseTensor,
which uses multi-dimensional indices and scalar values.
tf.IndexedSlices.__init__(values, indices, dense_shape=None)
Creates an IndexedSlices.
tf.IndexedSlices.values
A Tensor containing the values of the slices.
tf.IndexedSlices.indices
A 1-D Tensor containing the indices of the slices.
tf.IndexedSlices.dense_shape
A 1-D Tensor containing the shape of the corresponding dense tensor.
tf.IndexedSlices.name
The name of this IndexedSlices.
tf.IndexedSlices.dtype
The DType of elements in this tensor.
tf.IndexedSlices.device
The name of the device on which values will be produced, or None.
tf.IndexedSlices.op
The Operation that produces values as an output.