NumPy C Code Explanations¶
狂热包括当你忘记你的目标时加倍努力。 - George Santayana
一个权威是一个人,可以告诉你更多的东西比你真正想知道的。 - 未知
本章试图解释一些新代码的逻辑。这些解释背后的目的是使某人能够更容易地理解实现背后的想法比只是盯着代码更容易。也许以这种方式,可以改进,借用和/或优化算法。
Memory model¶
ndarray的一个基本方面是数组被视为从某个位置开始的内存的“块”。该存储器的解释取决于步幅信息。对于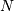 -dimensional数组中的每个维,整数(stride)指示必须跳过多少字节才能到达该维中的下一个元素。除非有单段数组,否则在遍历数组时必须查阅此步幅信息。编写接受strides的代码并不困难,你只需要使用(char *)指针,因为strides是以字节为单位的。还要记住,步幅不必是元素大小的单位倍数。此外,请记住,如果数组的维数为0(有时称为rank-0数组),则步幅和维度变量为NULL。
-dimensional数组中的每个维,整数(stride)指示必须跳过多少字节才能到达该维中的下一个元素。除非有单段数组,否则在遍历数组时必须查阅此步幅信息。编写接受strides的代码并不困难,你只需要使用(char *)指针,因为strides是以字节为单位的。还要记住,步幅不必是元素大小的单位倍数。此外,请记住,如果数组的维数为0(有时称为rank-0数组),则步幅和维度变量为NULL。
除了包含在PyArrayObject的strides和dimension成员中的结构信息,标志包含关于如何访问数据的重要信息。特别地,当存储器在根据数据类型数组的合适边界上时,设置NPY_ARRAY_ALIGNED标志。即使你有一个连续的内存块,你不能只是假定可以安全地引用一个数据类型特定的指针指向一个元素。只有当设置了NPY_ARRAY_ALIGNED标志时,这是一个安全的操作(在某些平台上它会工作,但是在其他平台上,例如Solaris,它会导致总线错误)。如果您计划写入数组的内存区域,还应确保NPY_ARRAY_WRITEABLE。还可以获得指向不可写存储器区域的指针。有时,当未设置NPY_ARRAY_WRITEABLE标志时,写入存储区将是粗鲁的。其他时候,它可能导致程序崩溃(例如一个只读存储器映射文件的数据区)。
Data-type encapsulation¶
数据类型是ndarray的一个重要抽象。操作将寻找数据类型,以提供在数组上操作所需的关键功能。此功能在PyArray_Descr结构的'f'成员指向的函数指针列表中提供。以这种方式,通过在'f'成员中提供具有适当函数指针的PyArray_Descr结构,可以简单地扩展数据类型的数量。对于内置类型,有一些优化绕过此机制,但数据类型抽象的要点是允许添加新的数据类型。
其中一个内置数据类型,void数据类型允许任意结构化类型包含1个或多个字段作为数组的元素。字段只是另一个数据类型对象以及当前结构化类型的偏移量。为了支持任意嵌套的字段,为void类型实现了数据类型访问的几个递归实现。一个常见的习惯是循环遍历字典的元素,并根据存储在给定偏移量的数据类型对象执行特定的操作。这些偏移可以是任意数。因此,必要时必须识别并考虑遇到未对齐数据的可能性。
N-D Iterators¶
NumPy代码中的一个非常常见的操作是需要遍历一个通用的,跨距的N维数组的所有元素。通用N维循环的这种操作在迭代器对象的概念中被抽象化。要编写一个N维循环,你只需要从一个ndarray创建一个迭代器对象,使用迭代器对象结构的dataptr成员,并在迭代器对象上调用宏PyArray_ITER_NEXT(it)移动到下一个元素。“next”元素始终以C连续顺序。宏工作由第一特殊外壳C连续,1-D和2-D情况下工作非常简单。
对于一般情况,迭代通过跟踪迭代器对象中的坐标计数器列表来工作。在每次迭代时,最后一个坐标计数器增加(从0开始)。如果该计数器小于比该维中数组的大小(预计算和存储的值)小一的计数器,则计数器增加,并且dataptr成员增加该维度中的步长,并且宏结束。如果到达一个维度的结束,则最后一个维度的计数器被重置为零,并且通过将步幅值减去比该维度中的元素数量小一个的值,dataptr被移回该维度的开始(这是也预先计算并存储在迭代器对象的后置成员中)。在这种情况下,宏不会结束,但是局部维度计数器递减,使得倒数第二维度替换了最后一个维度所起的作用,并且再次对倒数第二个维度执行先前描述的测试尺寸。以这种方式,对于任意步幅适当地调整dataptr。
PyArrayIterObject结构的坐标成员维护当前N-d计数器,除非基础数组是C连续的,在这种情况下,坐标计数被旁路。PyArrayIterObject的索引成员跟踪迭代器的当前平面索引。它由PyArray_ITER_NEXT宏更新。
Broadcasting¶
在Numeric中,广播被实现在几行代码深埋在ufuncobject.c。在NumPy中,广播的概念已经被抽象化,使得它可以在多个地方执行。广播由函数PyArray_Broadcast处理。这个函数需要传递一个PyArrayMultiIterObject(或者一个二进制等价的东西)。PyArrayMultiIterObject跟踪每个维度中的维度和大小的广播数量以及广播结果的总大小。它还跟踪正在广播的数组的数目和指向正广播的每个数组的迭代器的指针。
PyArray_Broadcast函数接受已定义的迭代器,并使用它们确定每个维度中的广播形状(在广播发生的同时创建迭代器,然后使用PyMultiIter_New然后,调整迭代器,以便每个迭代器认为它是在具有广播大小的数组上进行迭代。这通过调整迭代器的维数和每个维中的形状来完成。这是因为迭代器步幅也被调整。广播仅调整(或添加)长度1维度。对于这些维度,strides变量简单地设置为0,使得该数组上的迭代器的数据指针不会随着广播操作在扩展维度上操作而移动。
广播始终在数字中使用0值的步幅用于扩展维度。它在NumPy中以完全相同的方式完成。The big difference is that now the array of strides is kept track of in a PyArrayIterObject, the iterators involved in a broadcast result are kept track of in a PyArrayMultiIterObject, and the PyArray_BroadCast call implements the broad-casting rules.
Array Scalars¶
数组标量提供了Python类型的层次结构,允许存储在数组中的数据类型与从数组中提取元素时返回的Python类型之间的一一对应。此规则的一个例外是使用对象数组。对象数组是任意Python对象的异构集合。当你从对象数组中选择一个项目时,你会得到原来的Python对象(而不是一个对象数组标量,它确实存在,但很少用于实际目的)。
数组标量也提供与数组相同的方法和属性,目的是相同的代码可以用于支持任意维度(包括0维度)。数组标量是只读的(不可变的),除了void标量,它也可以写入,以便结构化数组字段设置更自然地工作(a [0] ['f1'] = value
Indexing¶
通过首先准备索引并找到索引类型来组织所有python索引操作arr[index]。支持的索引类型有:
- 整数
- 新轴
- 片
- 省略
- integer数组/ array-likes(花式)
- boolean(single boolean数组);如果有多个布尔数组作为索引或形状不完全匹配,则布尔数组将转换为整数数组。
- 0-d boolean(and also integer); 0-d boolean数组是一种特殊情况,必须在高级索引代码中处理。他们表示0-d布尔数组必须解释为整数数组。
以及标量数组特殊情况,表示整数数组被解释为整数索引,这是重要的,因为整数数组索引强制复制,但如果返回标量(完整整数索引),则被忽略。准备的索引保证有效,除了超出的值和广播错误的高级索引。这包括为不完整的索引添加省略号,例如当二维数组用单个整数索引时。
下一步取决于找到的索引类型。如果所有维度都用整数索引,则返回或设置标量。单个布尔索引数组将调用专门的布尔函数。包含省略号或切片但没有高级索引的索引将始终通过计算新的步长和内存偏移量来创建旧数组的视图。然后可以返回此视图,或者使用PyArray_CopyObject填充分配。注意,当数组是对象类型时,还可以在其他分支中的临时数组上调用PyArray_CopyObject以支持复杂赋值。
Advanced indexing¶
到目前为止,最复杂的情况是高级索引,其可以或可以不与典型的基于视图的索引组合。这里整数索引被解释为基于视图。在试图理解这一点之前,你可能想让自己熟悉它的微妙。高级索引代码有三种不同的分支和一种特殊情况:
- 有一个索引数组,它,以及分配数组,可以平凡地迭代。例如,它们可以是连续的。另外,索引数组必须是
intp类型,赋值中的数组值应该是正确的类型。这纯粹是一条快速的道路。 - 只有整数数组索引,因此不存在子数组。
- 基于视图和高级索引混合。在这种情况下,基于视图的索引定义了由高级索引组合的子数组的集合。例如,
arr [[1, 2, 3], :]是通过垂直堆叠子阵列arr [1, :],arr[2,:]arr [3, :]。 - 有一个子阵列,但它只有一个元素。这种情况可以处理,就像没有子阵列,但在设置过程中需要小心。
决定什么情况适用,检查广播,并确定所需的转置类型都在PyArray_MapIterNew中完成。设置完成后,有两种情况。如果没有子阵列或者它只有一个元素,则不需要子阵列迭代,并且准备迭代所有索引数组以及结果或值数组的迭代器。如果有一个子数组,有三个迭代器准备。一个用于索引数组,一个用于结果或值数组(减去其子阵列),一个用于原始数据和结果/分配数组的子数组。前两个迭代器给出(或允许计算)指向子阵列开始的指针,然后允许重新启动子阵列迭代。
当高级指数彼此相邻时,转置可能是必要的。所有必要的转置由PyArray_MapIterSwapAxes处理,必须由调用者处理,除非PyArray_MapIterNew被要求分配结果。
准备后,获取和设置是相对简单的,虽然不同的迭代模式需要考虑。除非在项目获取期间只有单个索引数组,否则预先检查索引的有效性。否则,它在内循环本身中处理以进行优化。
Universal Functions¶
通用函数是可调用的对象,它通过将基本的1-D循环包装成完整的易于使用的函数来实现广播,类型检查和缓冲,从而获得输入和产生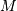 输出强制和输出参数处理。新的通用函数通常在C中创建,虽然有一个机制从Python函数(
输出强制和输出参数处理。新的通用函数通常在C中创建,虽然有一个机制从Python函数(frompyfunc)创建ufuncs。用户必须提供实现基本功能的1-D环路,其采用输入标量值并将所得的标量放置在适当的输出槽中,如实现中所解释的。
Setup¶
每个ufunc计算涉及与设置计算有关的一些开销。这种开销的实际意义是,即使ufunc的实际计算非常快,你将能够编写数组和类型特定的代码,它将对小数组比ufunc更快地工作。特别地,使用ufuncs对0-D数组执行许多计算将比其他基于Python的解决方案慢(静默导入的scalarmath模块存在,准确地给数组标量基于ufunc的计算的外观和显着减少的开销)。
当调用ufunc时,必须做许多事情。从这些设置操作收集的信息存储在循环对象中。这个循环对象是一个C结构(它可以成为一个Python对象,但不是这样初始化,因为它只在内部使用)。这个循环对象具有需要与PyArray_Broadcast一起使用的布局,以便可以以与在其他代码段中处理相同的方式处理广播。
第一件事是在线程特定的全局字典中查找缓冲区大小,错误掩码和关联的错误对象的当前值。错误掩码的状态控制在找到错误条件时会发生什么。应当注意,仅在执行每个1-D循环之后才执行对硬件错误标志的检查。这意味着如果输入和输出数组是连续的并且是正确的类型,使得执行单个1-D循环,则可以不检查标志,直到已经计算了数组的所有元素。在线程特定的字典中查找这些值需要时间,对于除非常小的数组之外的所有字典都容易忽略。
在检查之后,线程特定的全局变量,输入被评估以确定如何ufunc应该继续,并且输入和输出数组被构造如果必要。任何不是数组的输入都将转换为数组(如果需要,使用上下文)。注意哪些输入是标量(并因此转换为0-D数组)。
接下来,基于输入数组类型,从可用于ufunc的1-D环中选择适当的1-D环。通过尝试使输入的数据类型的签名与可用签名匹配来选择该1-D环路。与内置类型对应的签名存储在ufunc结构的types成员中。对应于用户定义类型的签名被存储在函数信息的链接表中,其中头元素作为CObject存储在由数据类型号键入的用户循环字典中(第一用户定义类型)定义类型在参数列表中用作键)。签名被搜索,直到找到输入数组可以安全地被丢弃的签名(忽略不允许确定结果类型的任何标量参数)。该搜索过程的含义是,当存储签名时,“较小类型”应该放置在“较大类型”下面。如果没有找到1-D环路,则报告错误。否则,将使用存储的签名更新argument_list - 如果需要转换并修复1-D环路假设的输出类型。
如果ufunc有2个输入和1个输出,而第二个输入是一个对象数组,那么执行一个特殊情况检查,如果第二个输入不是一个ndarray,返回NotImplemented,具有__array_priority__属性,并且有一个__r {op } __特殊方法。以这种方式,Python被通知给另一个对象一个机会来完成操作,而不是使用通用的对象数组计算。这允许(例如)稀疏矩阵覆盖乘法运算符1-D回路。
对于小于指定缓冲区大小的输入数组,副本由所有非连续,不对齐或乱序字节数组组成,以确保对于小数组,使用单个循环。然后,为所有输入数组创建数组迭代器,并将所得的迭代器集合广播到单个形状。
然后处理输出参数(如果有的话),并构造任何缺少的返回数组。如果任何提供的输出数组不具有正确的类型(或未对齐),并且小于缓冲区大小,则构造具有设置的特殊UPDATEIFCOPY标志的新输出数组,使得当完成时DECREF'的函数,它的内容将被复制回输出数组。然后处理输出参数的迭代器。
最后,做出关于如何执行循环机制以确保输入数组的所有元素被组合以产生正确类型的输出数组的决定。循环执行的选项是单循环(用于连续,对齐和正确的数据类型),stride-loop(用于非连续但仍然对齐和正确的数据类型)和缓冲循环(用于未对齐或不正确的数据类型情况)。根据所需的执行方法,然后建立和计算循环。
Function call¶
本节介绍如何为三种不同类型的执行中的每一种执行设置和执行基本通用函数计算循环。如果在编译期间定义NPY_ALLOW_THREADS,则只要没有涉及对象数组,则在调用循环之前释放Python全局解释器锁(GIL)。如果需要处理错误条件,则重新获取。仅在1-D回路完成后才检查硬件错误标志。
One Loop¶
这是所有的最简单的情况。通过调用底层的1-D循环一次来执行ufunc。这是可能的,只有当我们对于输入和输出两者具有正确类型(包括字节顺序)的对齐数据,并且所有数组具有均匀的步长(连续的,0-D或1-D)。在这种情况下,1-D计算循环被调用一次以计算整个数组的计算。注意,只有在整个计算完成后才检查硬件错误标志。
Strided Loop¶
当输入和输出数组对齐并且具有正确类型,但是步幅不均匀(非连续和2-D或更大)时,则采用第二循环结构进行计算。此方法将输入和输出参数的所有迭代器转换为除最大维度之外的所有迭代器。然后内部循环由底层的1-D计算循环处理。外部循环是转换的迭代器上的标准迭代器循环。在每个1-D回路完成后检查硬件错误标志。
Buffered Loop¶
这是当输入和/或输出数组从底层的1-D回路期望的位置错位或错误的数据类型(包括字节交换)时处理该情况的代码。数组也被假定为不连续的。代码的工作非常类似于有限循环,除了内部1-D循环被修改,使得对输入执行预处理,并对bufsize块中的输出执行后处理(其中bufsize是用户可设置的参数)。底层的1-D计算循环在被复制(如果需要的话)的数据上被调用。在这种情况下,设置代码和循环代码要复杂得多,因为它必须处理:
- 临时缓冲区的存储器分配
- 决定是否对输入和输出数据使用缓冲器(未对齐和/或错误的数据类型)
- 复制并且可能为需要缓冲器的任何输入或输出投射数据。
- 特殊外壳对象数组,以便在需要复制和/或转换时正确处理引用计数。
- 将内部1-D循环分解成bufsize块(具有可能的余数)。
同样,在每个1-D循环结束时检查硬件错误标志。
Final output manipulation¶
Ufuncs允许其他类似数组的类通过接口无缝地传递,因为特定类的输入将导致输出是同一类。这个工作机制如下。如果任何输入不是ndarrays并定义__array_wrap__方法,则具有最大__array_priority__属性的类确定所有输出的类型数组传入)。输入数组的__array_wrap__方法将在从输入ufunc返回的ndarray时调用。有两种支持__array_wrap__函数的调用样式。第一个将ndarray作为第一个参数,使用“context”的元组作为第二个参数。上下文是(ufunc,arguments,output argument number)。这是第一次尝试。如果发生TypeError,那么仅使用ndarray作为第一个参数来调用函数。
Methods¶
它们是ufunc的三个方法,需要类似于通用目的ufunc的计算。这些是减少,积累和减少。这些方法中的每一个都需要一个设置命令,后面跟一个循环这些是与通用函数调用所实现的相同的基本循环样式,除了无元素和单元素情况(这是输入数组对象分别具有0和1个元素时出现的特殊情况)。
Setup¶
所有三种方法的设置功能是construct_reduce。此函数创建一个缩减循环对象,并用完成循环所需的参数填充它。所有的方法只适用于采用2输入和返回1输出的ufunc。因此,假设签名为[otype,otype,otype],选择基础的一维环,其中otype然后从(每个线程)全局存储检索缓冲区大小和错误处理。对于未对齐或具有不正确数据类型的小数组,进行复制,以便使用未缓冲的代码段。然后,选择循环策略。如果数组中有1个元素或0个元素,则选择一个简单的循环方法。如果数组未对齐并具有正确的数据类型,则选择跨距循环。否则,必须执行缓冲循环。然后建立循环参数,并构造返回数组。输出数组具有不同的形状,取决于方法是reduce,accumulate还是reduceat。如果已经提供了输出数组,则检查其形状。如果输出数组不是C连续,对齐和正确的数据类型,则使用UPDATEIFCOPY标志设置进行临时副本。这样,方法将能够使用良好的输出数组,但是当方法计算完成时,结果将被复制回真实输出数组。最后,迭代器被设置为循环正确的轴(取决于提供给该方法的轴的值),并且设置例程返回到实际的计算例程。
Reduce¶
所有的ufunc方法使用相同的底层1-D计算循环,输入和输出参数被调整,以便进行适当的减少。例如,reduce的功能的关键是,1-D环路用输出调用,第二个输入指向存储器中的相同位置,并且步长都为0。第一个输入指向具有由所选轴的适当步幅给定的步长的输入数组。这样,执行的操作是
其中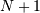 是输入中的元素的数量,
是输入中的元素的数量,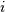 ,
, 是输出,并且
是输出,并且![i[k]](../_images/math/3df3720a46a79c496081a412443b924e4cf5b428.png) 是沿着所选择的轴的的
是沿着所选择的轴的的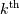 元素。对具有大于1维的数组重复该基本操作,使得沿着所选择的轴的每个1-D子阵列进行缩小。删除选定维度的迭代器处理此循环。
元素。对具有大于1维的数组重复该基本操作,使得沿着所选择的轴的每个1-D子阵列进行缩小。删除选定维度的迭代器处理此循环。
对于缓冲循环,必须注意在调用循环函数之前复制和转换数据,因为底层循环需要正确数据类型(包括字节顺序)的对齐数据。缓冲循环必须在不大于用户指定的bufsize的块上调用循环函数之前处理此复制和转换。
Accumulate¶
累加函数非常类似于减函数,因为输出和第二输入都指向输出。区别在于第二个输入指向当前输出指针后面的一个内存。因此,所执行的操作是
输出具有与输入相同的形状,当所选轴的形状为时,每个1-D回路在元素上运行。再次,缓冲循环在调用底层的1-D计算循环之前小心地复制和转换数据。
Reduceat¶
reduceat函数是reduce和accumulate函数的泛化。它实现了由索引指定的输入数组的缩减范围。检查extra索引参数以确保在循环计算发生之前,沿选定维度的输入数组的每个输入不会太大。循环实现使用与reduce代码非常相似的代码来处理,该代码的重复次数与索引输入中的元素的重复次数一样多。具体来说:传递到底层1-D计算环路的第一个输入指针指向由索引数组指示的正确位置处的输入数组。此外,输出指针和传递到底层1-D循环的第二个输入指针指向内存中的相同位置。1-D计算循环的大小固定为当前索引和下一个索引之间的差(当当前索引是最后一个索引时,则下一个索引被假定为沿着选定维度的数组的长度)。以这种方式,1-D环路将实现指定索引上的减少。
未匹配或与输入和/或输出数据类型不匹配的循环数据类型使用缓冲代码处理,其中,in-in数据被复制到临时缓冲区并在调用之前根据需要转换为正确的数据类型底层的1-D函数。临时缓冲区以(元素)大小创建,不大于用户可设置的缓冲区大小值。因此,循环必须足够灵活,足以调用底层的1-D计算循环足够的时间来完成不大于缓冲区大小的块中的总计算。