Array API¶
Array structure and data access¶
这些宏都可以访问PyArrayObject结构成员。The input argument, arr, can be any PyObject * that is directly interpretable as a PyArrayObject * (any instance of the PyArray_Type and its sub-types).
- int
PyArray_NDIM(PyArrayObject *arr)¶ 数组中的维数。
- npy_intp *
PyArray_DIMS(PyArrayObject *arr)¶ 返回指向数组的尺寸/形状的指针。元素的数量与数组的维数相匹配。
- npy_intp *
PyArray_SHAPE(PyArrayObject *arr)¶ 版本1.7中的新功能。
PyArray_DIMS的同义词,命名为与Python中的'shape'用法一致。
- void *
PyArray_DATA(PyArrayObject *arr)¶
- char *
PyArray_BYTES(PyArrayObject *arr)¶ 这两个宏是相似的,并获得指向数组的数据缓冲区的指针。第一个宏可以(并且应该)被分配给特定指针,其中第二个宏用于通用处理。如果你不能保证一个连续和/或对齐的数组,那么请确保你理解如何访问数组中的数据,以避免内存和/或对齐问题。
- npy_intp *
PyArray_STRIDES(PyArrayObject* arr)¶ 返回指向数组的步长的指针。元素的数量与数组的维数相匹配。
- npy_intp
PyArray_DIM(PyArrayObject* arr, int n)¶ 返回n
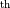 维中的形状。
维中的形状。
- npy_intp
PyArray_STRIDE(PyArrayObject* arr, int n)¶ 返回n
维度中的步幅。
- PyObject *
PyArray_BASE(PyArrayObject* arr)¶ 这将返回数组的基础对象。在大多数情况下,这意味着拥有数组正在指向的内存的对象。
如果你正在使用C API构造一个数组,并指定你自己的内存,你应该使用函数
PyArray_SetBaseObject将基址设置为拥有内存的对象。如果设置了
NPY_ARRAY_UPDATEIFCOPY标志,则它具有不同的含义,即base是在销毁时将当前数组复制到其中的数组。这两个函数的基本属性的重载可能在未来版本的NumPy中改变。
- PyArray_Descr *
PyArray_DESCR(PyArrayObject* arr)¶ 返回对数组的dtype属性的借用引用。
- PyArray_Descr *
PyArray_DTYPE(PyArrayObject* arr)¶ 版本1.7中的新功能。
PyArray_DESCR的同义词,命名为与Python中的'dtype'用法一致。
- void
PyArray_ENABLEFLAGS(PyArrayObject* arr, int flags)¶ 版本1.7中的新功能。
启用指定的数组标志。这个函数没有验证,并假设你知道你在做什么。
- void
PyArray_CLEARFLAGS(PyArrayObject* arr, int flags)¶ 版本1.7中的新功能。
清除指定的数组标志。这个函数没有验证,并假设你知道你在做什么。
- int
PyArray_FLAGS(PyArrayObject* arr)¶
- npy_intp
PyArray_ITEMSIZE(PyArrayObject* arr)¶ 返回此数组元素的itemsize。
请注意,在旧版本1.7中已弃用的API中,此函数的返回类型为
int。
- int
PyArray_TYPE(PyArrayObject* arr)¶ 返回此数组元素的(builtin)类型号。
- PyObject *
PyArray_GETITEM(PyArrayObject* arr, void* itemptr)¶ 从ndarray中获取一个Python对象,arr,在itemptr指向的位置。失败时返回
NULL。
- int
PyArray_SETITEM(PyArrayObject* arr, void* itemptr, PyObject* obj)¶ 转换obj并将其放在ndarray中,arr,在itemptr指向的地方。如果发生错误,返回-1,否则返回0。
- npy_intp
PyArray_SIZE(PyArrayObject* arr)¶ 返回数组的总大小(以元素数表示)。
- npy_intp
PyArray_Size(PyArrayObject* obj)¶ 如果obj不是bigndarray的子类,则返回0。否则,返回数组中元素的总数。
PyArray_SIZE(obj)的安全版本。
- npy_intp
PyArray_NBYTES(PyArrayObject* arr)¶ 返回数组使用的总字节数。
Data access¶
这些函数和宏提供容易访问ndarray的元素从C。这些工作对所有数组。你可能需要在访问数组中的数据时注意,但是,如果它不是机器字节顺序,未对齐或不可写。换句话说,一定要尊重标志的状态,除非你知道你在做什么,或者以前保证一个数组是可写,对齐的,并且使用PyArray_FromAny以机器字节顺序。如果你希望处理所有类型的数组,每种类型的copyswap函数对于处理不当数组是有用的。一些平台(例如Solaris)不喜欢错位的数据,如果你解引用一个未对齐的指针,会崩溃。其他平台(例如x86 Linux)只会在未对齐数据时工作速度较慢。
- void*
PyArray_GetPtr(PyArrayObject* aobj, npy_intp* ind)¶ 在由c阵列ind给出的N维索引处返回指向ndarray的数据的指针aobj(其必须至少aobj-nd大小)。你可能希望将返回的指针类型转换为ndarray的数据类型。
- void*
PyArray_GETPTR1(PyArrayObject* obj, npy_intp i)¶
- void*
PyArray_GETPTR2(PyArrayObject* obj, npy_intp i, npy_intp j)¶
- void*
PyArray_GETPTR3(PyArrayObject* obj, npy_intp i, npy_intp j, npy_intp k)¶
- void*
PyArray_GETPTR4(PyArrayObject* obj, npy_intp i, npy_intp j, npy_intp k, npy_intp l)¶ 快速,内联访问在ndarray中给定坐标(obj)的元素,它必须分别具有1,2,3或4维(这不被选中)。对应的i,j,k和l可以是任何整数,但将被解释为
npy_intp。你可能希望将返回的指针类型转换为ndarray的数据类型。
Creating arrays¶
From scratch¶
- PyObject*
PyArray_NewFromDescr(PyTypeObject* subtype, PyArray_Descr* descr, int nd, npy_intp* dims, npy_intp* strides, void* data, int flags, PyObject* obj)¶ 此函数窃取对descr的引用。
这是主要的数组创建功能。最新的数组是用这个灵活的函数创建的。
返回的对象是Python类型子类型的对象,它必须是
PyArray_Type的子类型。数组具有nd维度,由dims描述。新数组的数据类型描述符为descr。如果子类型是数组子类而不是基本
&PyArray_Type,则obj是要传递到__array_finalize__如果data为
NULL,则将分配新的内存,并且标志可以为非零,以指示Fortran风格的连续数组。如果数据不是NULL,则假定指向要用于数组的存储器,并且使用标志参数作为数组的新标志(除了新数组的NPY_OWNDATA和NPY_ARRAY_UPDATEIFCOPY标志的状态将被复位)。另外,如果数据是非NULL,则也可以提供步幅。If strides is
NULL, then the array strides are computed as C-style contiguous (default) or Fortran-style contiguous (flags is nonzero for data =NULLor flags &NPY_ARRAY_F_CONTIGUOUSis nonzero non-NULL data). 任何提供的dims和strides都会复制到新分配的维度中,并且新建数组的数组。
- PyObject*
PyArray_NewLikeArray(PyArrayObject* prototype, NPY_ORDER order, PyArray_Descr* descr, int subok)¶ 版本1.6中的新功能。
如果它不为NULL,此函数将窃取对descr的引用。
此数组创建例程允许方便地创建与现有数组的形状和存储器布局匹配的新数组,可能改变布局和/或数据类型。
当订单是
NPY_ANYORDER时,结果顺序为NPY_FORTRANORDERif if prototype is fortran数组,NPY_CORDER当命令为NPY_KEEPORDER时,结果顺序与原型匹配,即使原型在C或Fortran顺序。如果descr为NULL,则使用原型的数据类型。
如果subok为1,则新创建的数组将使用原型的子类型创建新数组,否则将创建基类数组。
- PyObject*
PyArray_New(PyTypeObject* subtype, int nd, npy_intp* dims, int type_num, npy_intp* strides, void* data, int itemsize, int flags, PyObject* obj)¶ 这类似于
PyArray_DescrNew(...),除非你用type_num和itemsize指定数据类型描述符,其中type_num 对应于内置(或用户定义)类型。如果类型总是具有相同的字节数,则忽略itemsize。否则,itemsize指定此数组的特定大小。
警告
如果数据传递到PyArray_NewFromDescr或PyArray_New,则在删除新数组之前,不得重新分配此内存。如果此数据来自另一个Python对象,则可以使用该对象上的Py_INCREF来完成此操作,并将新数组的基本成员设置为指向该对象。如果传递步幅,它们必须与尺寸,项目大小和数组的数据一致。
- PyObject*
PyArray_SimpleNew(int nd, npy_intp* dims, int typenum)¶ 创建类型为typenum的新未初始化数组,其每个和维中的大小由整数数组dims给出。此函数不能用于创建一个灵活类型的数组(没有给定itemize)。
- PyObject*
PyArray_SimpleNewFromData(int nd, npy_intp* dims, int typenum, void* data)¶ 在给定指针指向的数据周围创建一个数组包装。数组标志将具有默认值,即数据区域运行良好并且C型连续。数组的形状由长度nd的dims c-数组给出。数组的数据类型由typenum指示。
- PyObject*
PyArray_SimpleNewFromDescr(int nd, npy_intp* dims, PyArray_Descr* descr)¶ 如果它不为NULL,此函数将窃取对descr的引用。
使用提供的数据类型描述符descr创建由nd和dims确定的形状的新数组。
-
PyArray_FILLWBYTE(PyObject* obj, int val)¶ 填充由obj指向的数组 - 它必须是bigndarray的子类,其中val(作为字节计算)。这个宏调用memset,所以obj必须是连续的。
- PyObject*
PyArray_Zeros(int nd, npy_intp* dims, PyArray_Descr* dtype, int fortran)¶ 使用由dims给出的形状和由dtype给出的数据类型构造新的nd -dimensional数组。如果fortran不为零,则创建Fortran顺序数组,否则创建C顺序数组。用零填充存储器(如果dtype对应于
NPY_OBJECT,则为0对象)。
- PyObject*
PyArray_ZEROS(int nd, npy_intp* dims, int type_num, int fortran)¶ PyArray_Zeros的宏形式,它采用类型号而不是数据类型对象。
- PyObject*
PyArray_Empty(int nd, npy_intp* dims, PyArray_Descr* dtype, int fortran)¶ 使用由dims给出的形状和由dtype给出的数据类型构造新的nd -dimensional数组。如果fortran不为零,则创建Fortran顺序数组,否则创建C顺序数组。数组未初始化,除非数据类型对应于
NPY_OBJECT,在这种情况下数组用Py_None填充。
- PyObject*
PyArray_EMPTY(int nd, npy_intp* dims, int typenum, int fortran)¶ PyArray_Empty的宏形式,它采用类型号,typenum而不是数据类型对象。
- PyObject*
PyArray_Arange(double start, double stop, double step, int typenum)¶ Construct a new 1-dimensional array of data-type, typenum, that ranges from start to stop (exclusive) in increments of step . 等同于arange(开始,停止,步骤,dtype)。
- PyObject*
PyArray_ArangeObj(PyObject* start, PyObject* stop, PyObject* step, PyArray_Descr* descr)¶ 构建由
descr确定的数据类型的新的1维数组,范围从start到stop(排除),增量为step。等于arange(start,stop,step,typenum)。
- int
PyArray_SetBaseObject(PyArrayObject* arr, PyObject* obj)¶ 版本1.7中的新功能。
此函数将引用挪到
obj,并将其设置为arr的基本属性。如果你通过传入你自己的内存缓冲区作为参数来构造一个数组,你需要设置数组的base属性,以确保内存缓冲区的生命周期是合适的。
成功返回值为0,失败时返回-1。
如果提供的对象是数组,则此函数遍历base指针链,以使每个数组直接指向内存所有者。一旦基本设置,它可能不会更改为另一个值。
From other objects¶
- PyObject*
PyArray_FromAny(PyObject* op, PyArray_Descr* dtype, int min_depth, int max_depth, int requirements, PyObject* context)¶ 这是用于从任何嵌套序列或暴露数组接口op的对象获取数组的主函数。The parameters allow specification of the required dtype, the minimum (min_depth) and maximum (max_depth) number of dimensions acceptable, and other requirements for the array. dtype参数需要是指示所需数据类型(包括所需的字节序)的
PyArray_Descr结构。dtype参数可以为NULL,表示任何数据类型(和字节序)都是可以接受的。除非flags中存在FORCECAST,如果无法从对象安全获取数据类型,则此调用将生成错误。如果你想对dtype使用NULL,并确保数组没有被切换,请使用PyArray_CheckFromAny。任何深度参数的值为0将导致该参数被忽略。可以添加以下任何数组标志(例如使用|)以获取需求参数。如果您的代码可以处理一般(例如 stride,字节交换或未对齐的数组),则要求可能为0。此外,如果op不是数组(或不公开数组接口),则将创建一个新数组(并使用序列协议从op填充) 。新数组将具有NPY_DEFAULT作为其标志成员。上下文参数被传递给op的__array__方法,并且仅当数组以这种方式构造时才使用。几乎总是此参数为NULL。在NumPy的1.6版本和更早版本中,以下标志中没有_ARRAY_宏命名空间。这种形式的常量名在1.7中已被弃用。
-
NPY_ARRAY_C_CONTIGUOUS¶ 确保返回的数组是C样式连续的
-
NPY_ARRAY_F_CONTIGUOUS¶
-
NPY_ARRAY_ALIGNED¶ 确保返回的数组在其数据类型的正确边界上对齐。对齐数组具有数据指针和每个步幅因子作为数据类型描述符的对准因子的倍数。
-
NPY_ARRAY_WRITEABLE¶ 确保返回的数组可以写入。
-
NPY_ARRAY_ENSURECOPY¶ 确保副本由op组成。如果此标志不存在,则如果可以避免,则不复制数据。
-
NPY_ARRAY_ENSUREARRAY¶ 确保结果是基类ndarray或bigndarray。默认情况下,如果op是bigndarray的子类的实例,则返回相同子类的实例。如果设置了此标志,将返回一个ndarray对象。
-
NPY_ARRAY_FORCECAST¶ 强制转换为输出类型,即使它不能安全地完成。没有这个标志,只有当它可以安全地进行时,才会发生数据转换,否则会引发错误。
-
NPY_ARRAY_UPDATEIFCOPY¶ 如果op已经是一个数组,但不满足要求,那么将进行一个副本(这将满足要求)。如果此标志存在并且必须创建一个(已经是数组的对象的)副本,则在返回的副本中设置相应的
NPY_ARRAY_UPDATEIFCOPY标志,并且op为设为只读。当返回的副本被删除时(可能是在计算完成后),其内容将被复制回op,并且op数组将再次可写。如果op无法写入,则会引发错误。如果op不是数组,则此标志无效。
-
NPY_ARRAY_BEHAVED¶
-
NPY_ARRAY_CARRAY¶
-
NPY_ARRAY_CARRAY_RO¶
-
NPY_ARRAY_FARRAY¶
-
NPY_ARRAY_FARRAY_RO¶
-
NPY_ARRAY_DEFAULT¶
-
NPY_ARRAY_IN_ARRAY¶
-
NPY_ARRAY_IN_FARRAY¶
-
NPY_OUT_ARRAY¶ NPY_ARRAY_C_CONTIGUOUS|NPY_ARRAY_WRITEABLE|NPY_ARRAY_ALIGNED
-
NPY_ARRAY_OUT_FARRAY¶ NPY_ARRAY_F_CONTIGUOUS|NPY_ARRAY_WRITEABLE|NPY_ARRAY_ALIGNED
-
NPY_ARRAY_INOUT_ARRAY¶ NPY_ARRAY_C_CONTIGUOUS|NPY_ARRAY_WRITEABLE|NPY_ARRAY_ALIGNED|NPY_ARRAY_UPDATEIFCOPY
-
NPY_ARRAY_INOUT_FARRAY¶ NPY_ARRAY_F_CONTIGUOUS|NPY_ARRAY_WRITEABLE|NPY_ARRAY_ALIGNED|NPY_ARRAY_UPDATEIFCOPY
-
- int
PyArray_GetArrayParamsFromObject(PyObject* op, PyArray_Descr* requested_dtype, npy_bool writeable, PyArray_Descr** out_dtype, int* out_ndim, npy_intp* out_dims, PyArrayObject** out_arr, PyObject* context)¶ 版本1.6中的新功能。
检索用于查看/将任意PyObject *转换为NumPy数组的数组参数。这允许发现Python列表列表的“先天类型和形状”,而无需实际转换为数组。PyArray_FromAny调用此函数来分析其输入。
在某些情况下,例如结构化数组和__array__接口,需要使用数据类型来理解对象。当需要时,为'requested_dtype'提供一个Descr,否则提供NULL。此引用不会被窃取。此外,如果请求的dtype不修改输入的解释,out_dtype仍将获得对象的“先天”dtype,而不是在'requested_dtype'中传递的dtype。
如果需要写入“op”中的值,请将布尔值“writeable”设置为1。当'op'是标量,列表列表或其他不可写入的'op'时,会出现错误。这不同于将NPY_ARRAY_WRITEABLE传递到PyArray_FromAny,其中可写数组可以是输入的副本。
当返回成功(返回值为0)时,out_arr将填充一个非空的PyArrayObject,其余的参数保持不变,或out_arr填充为NULL,其余的参数将被填充。
典型用途:
PyArrayObject *arr = NULL; PyArray_Descr *dtype = NULL; int ndim = 0; npy_intp dims[NPY_MAXDIMS]; if (PyArray_GetArrayParamsFromObject(op, NULL, 1, &dtype, &ndim, &dims, &arr, NULL) < 0) { return NULL; } if (arr == NULL) { ... validate/change dtype, validate flags, ndim, etc ... // Could make custom strides here too arr = PyArray_NewFromDescr(&PyArray_Type, dtype, ndim, dims, NULL, fortran ? NPY_ARRAY_F_CONTIGUOUS : 0, NULL); if (arr == NULL) { return NULL; } if (PyArray_CopyObject(arr, op) < 0) { Py_DECREF(arr); return NULL; } } else { ... in this case the other parameters weren't filled, just validate and possibly copy arr itself ... } ... use arr ...
- PyObject*
PyArray_CheckFromAny(PyObject* op, PyArray_Descr* dtype, int min_depth, int max_depth, int requirements, PyObject* context)¶ 几乎与
PyArray_FromAny(...)除了要求可以包含NPY_ARRAY_NOTSWAPPED(覆盖dtype )和NPY_ARRAY_ELEMENTSTRIDES,表示数组应该对齐,因为步长是元素大小的倍数。在NumPy的1.6版本和更早版本中,以下标志中没有_ARRAY_宏命名空间。这种形式的常量名在1.7中已被弃用。
-
NPY_ARRAY_NOTSWAPPED¶ 确保返回的数组具有按机器字节顺序的数据类型描述符,超越了dtype参数中的任何规范。通常,字节顺序要求由dtype参数决定。如果这个标志被设置,并且dtype参数不指示机器字节顺序描述符(或者是NULL,并且该对象已经是具有不是机器字节顺序的数据类型描述符的数组),则新的数据 - 类型描述符被创建并使用,其字节顺序字段设置为native。
-
NPY_ARRAY_BEHAVED_NS¶ NPY_ARRAY_ALIGNED|NPY_ARRAY_WRITEABLE|NPY_ARRAY_NOTSWAPPED
-
NPY_ARRAY_ELEMENTSTRIDES¶ 确保返回的数组具有元素大小的倍数的步长。
- PyObject*
PyArray_FromArray(PyArrayObject* op, PyArray_Descr* newtype, int requirements)¶ Special case of
PyArray_FromAnyfor when op is already an array but it needs to be of a specific newtype (including byte-order) or has certain requirements.
- PyObject*
PyArray_FromStructInterface(PyObject* op)¶ 从公开了
__array_struct__属性并遵循数组接口协议的Python对象返回一个ndarray对象。如果对象不包含此属性,则返回对Py_NotImplemented的借用引用。
- PyObject*
PyArray_FromInterface(PyObject* op)¶ 从暴露数组接口协议后的
__array_interface__属性的Python对象返回一个ndarray对象。如果对象不包含此属性,则返回对Py_NotImplemented的借用引用。
- PyObject*
PyArray_FromArrayAttr(PyObject* op, PyArray_Descr* dtype, PyObject* context)¶ 从暴露了
__array__方法的Python对象返回一个ndarray对象。__array__方法可以取0,1或2个参数([dtype,context]),其中上下文用于传递有关__array__
- PyObject*
PyArray_ContiguousFromAny(PyObject* op, int typenum, int min_depth, int max_depth)¶ 此函数从枚举的typenum指定的(非灵活)类型的任何嵌套序列或数组接口导出对象op返回(C样式) t1>,最小深度min_depth和最大深度max_depth。等效于对
PyArray_FromAny的调用,其要求设置为NPY_DEFAULT,类型参数的type_num成员设置为typenum。
- PyObject *
PyArray_FromObject(PyObject *op, int typenum, int min_depth, int max_depth)¶ 从枚举类型给定的类型的任何嵌套序列或数组接口导出对象op返回对齐的和本地字节序数组。数组可以具有的最小维数由min_depth给出,而最大值为max_depth。这等同于对需求设置为BEHAVED的
PyArray_FromAny的调用。
- PyObject*
PyArray_EnsureArray(PyObject* op)¶ 此函数将引用挪到
op,并确保op是基类的ndarray。它是特殊情况的数组标量,但是否则调用PyArray_FromAny(op,NULL,0,0,NPY_ARRAY_ENSUREARRAY)。
- PyObject*
PyArray_FromString(char* string, npy_intp slen, PyArray_Descr* dtype, npy_intp num, char* sep)¶ 从长度为
slen的二进制或(ASCII)文本string构造单一类型的一维数组。要创建的数组的数据类型由dtype给出。如果num是-1,则复制整个字符串并返回一个适当大小的数组,否则num是要复制字符串。Ifsepis NULL (or “”), then interpret the string as bytes of binary data, otherwise convert the sub-strings separated bysepto items of data-typedtype. 某些数据类型在文本模式下可能无法读取,如果发生错误,则会出现错误。所有错误返回NULL。
- PyObject*
PyArray_FromFile(FILE* fp, PyArray_Descr* dtype, npy_intp num, char* sep)¶ 从二进制或文本文件构造单个类型的一维数组。打开的文件指针为
fp,要创建的数组的数据类型由dtype给出。这必须与文件中的数据匹配。如果num为-1,则读取直到文件结束并返回适当大小的数组,否则num是要读取的项目数。如果sep为NULL(或“”),则以二进制模式从文件读取,否则从文本模式中使用sep提供项目分隔符。某些数组类型无法在文本模式下读取,在这种情况下会出现错误。
- PyObject*
PyArray_FromBuffer(PyObject* buf, PyArray_Descr* dtype, npy_intp count, npy_intp offset)¶ 从导出(单段)缓冲区协议(或具有返回导出缓冲区协议的对象的__buffer__属性)的对象
buf构造单个类型的一维数组。首先尝试可写缓冲区,然后尝试只读缓冲区。返回的数组的NPY_ARRAY_WRITEABLE标志将反映哪个成功。The data is assumed to start atoffsetbytes from the start of the memory location for the object. 缓冲区中的数据类型将根据数据类型描述符dtype.如果count为负,那么将根据缓冲区的大小和所请求的itemsize来确定,否则count表示应该从缓冲区转换多少个元素。
- int
PyArray_CopyInto(PyArrayObject* dest, PyArrayObject* src)¶ 从源数组
src复制到目标数组dest,如有必要,执行数据类型转换。如果发生错误返回-1(否则为0)。src的形状必须可以广播到dest的形状。dest和src的数据区不能重叠。
- int
PyArray_MoveInto(PyArrayObject* dest, PyArrayObject* src)¶ 将数据从源数组
src移入目标数组dest,如有必要,执行数据类型转换。如果发生错误返回-1(否则为0)。src的形状必须可以广播到dest的形状。dest和src的数据区可能重叠。
- PyArrayObject*
PyArray_GETCONTIGUOUS(PyObject* op)¶ 如果
op已经是(C风格)连续和良好行为,那么只是返回一个引用,否则返回一个(连续和良好行为)的数组副本。参数op必须是(ndarray的子类),并且不进行检查。
- PyObject*
PyArray_FROM_O(PyObject* obj)¶ 将
obj转换为ndarray。参数可以是导出数组接口的任何嵌套序列或对象。这是PyArray_FromAny的宏形式,使用NULL,0,0,0作为其他参数。您的代码必须能够处理任何数据类型描述符和任何data-flags的组合,以使用此宏。
- PyObject*
PyArray_FROM_OF(PyObject* obj, int requirements)¶ 类似于
PyArray_FROM_O,但它可以接受要求的参数,指示生成的数组必须具有的属性。Available requirements that can be enforced areNPY_ARRAY_C_CONTIGUOUS,NPY_ARRAY_F_CONTIGUOUS,NPY_ARRAY_ALIGNED,NPY_ARRAY_WRITEABLE,NPY_ARRAY_NOTSWAPPED,NPY_ARRAY_ENSURECOPY,NPY_ARRAY_UPDATEIFCOPY,NPY_ARRAY_FORCECAST, andNPY_ARRAY_ENSUREARRAY. 还可以使用标志的标准组合:
- PyObject*
PyArray_FROM_OT(PyObject* obj, int typenum)¶ 类似于
PyArray_FROM_O,除了它可以接受typenum的参数,指定返回的数组的类型号。
- PyObject*
PyArray_FROM_OTF(PyObject* obj, int typenum, int requirements)¶ 组合
PyArray_FROM_OF和PyArray_FROM_OT,允许提供typenum和标志参数。
- PyObject*
PyArray_FROMANY(PyObject* obj, int typenum, int min, int max, int requirements)¶ 类似于
PyArray_FromAny,除了使用类型号指定数据类型。PyArray_DescrFromType(typenum)直接传递到PyArray_FromAny。如果NPY_ARRAY_ENSURECOPY作为需求传递,此宏还将NPY_DEFAULT添加到要求中。
Dealing with types¶
General check of Python Type¶
-
PyArray_Check(op)¶ 如果op是类型为
PyArray_Type的子类型的Python对象,则计算true。
-
PyArray_CheckExact(op)¶ 如果op是类型为
PyArray_Type的Python对象,则计算true。
-
PyArray_HasArrayInterface(op, out)¶ 如果
op实现数组接口的任何部分,则out将包含对使用接口或outNULL如果在转换期间发生错误。否则,out将包含对Py_NotImplemented的借用引用,并且未设置错误条件。
-
PyArray_HasArrayInterfaceType(op, type, context, out)¶ 如果
op实现数组接口的任何部分,则out将包含对使用接口或outNULL如果在转换期间发生错误。否则,out将包含对Py_NotImplemented的借用引用,并且不设置错误条件。此版本允许在查找__array__属性的数组接口部分中设置类型和上下文。
-
PyArray_IsZeroDim(op)¶ 如果op是
PyArray_Type(的子类)的实例并且具有0个维度,则计算true。
-
PyArray_IsScalar(op, cls)¶ 如果op是
Py{cls}ArrType_Type的实例,则计算true。
-
PyArray_CheckScalar(op)¶ 如果op是数组标量(
PyGenericArr_Type的子类型的实例)或PyArray_Type
-
PyArray_IsPythonNumber(op)¶ 如果op是内置数值类型的实例(int,float,complex,long,bool)
-
PyArray_IsPythonScalar(op)¶ 如果op是内置的Python标量对象(int,float,complex,str,unicode,long,bool),则计算true。
-
PyArray_IsAnyScalar(op)¶ 如果op是Python标量对象(请参阅
PyArray_IsPythonScalar)或数组标量(PyGenericArr_Type的子类型的实例) 。
-
PyArray_CheckAnyScalar(op)¶ 如果op是Python标量对象(参见
PyArray_IsPythonScalar),即数组标量(PyGenericArr_Type的子类型的实例),其维度为0的PyArray_Type的子类型的实例。
Data-type checking¶
对于typenum宏,参数是表示枚举的数组数据类型的整数。对于数组类型检查宏,参数必须是PyObject *,可以直接解释为PyArrayObject *。
-
PyTypeNum_ISUNSIGNED(num)¶
-
PyDataType_ISUNSIGNED(descr)¶
-
PyArray_ISUNSIGNED(obj)¶ 类型表示无符号整数。
-
PyTypeNum_ISSIGNED(num)¶
-
PyDataType_ISSIGNED(descr)¶
-
PyArray_ISSIGNED(obj)¶ 类型表示有符号整数。
-
PyTypeNum_ISINTEGER(num)¶
-
PyDataType_ISINTEGER(descr)¶
-
PyArray_ISINTEGER(obj)¶ 类型表示任何整数。
-
PyTypeNum_ISFLOAT(num)¶
-
PyDataType_ISFLOAT(descr)¶
-
PyArray_ISFLOAT(obj)¶ 类型表示任何浮点数。
-
PyTypeNum_ISCOMPLEX(num)¶
-
PyDataType_ISCOMPLEX(descr)¶
-
PyArray_ISCOMPLEX(obj)¶ 类型表示任何复杂浮点数。
-
PyTypeNum_ISNUMBER(num)¶
-
PyDataType_ISNUMBER(descr)¶
-
PyArray_ISNUMBER(obj)¶ 类型表示任何整数,浮点数或复数浮点数。
-
PyTypeNum_ISSTRING(num)¶
-
PyDataType_ISSTRING(descr)¶
-
PyArray_ISSTRING(obj)¶ Type表示字符串数据类型。
-
PyTypeNum_ISPYTHON(num)¶
-
PyDataType_ISPYTHON(descr)¶
-
PyArray_ISPYTHON(obj)¶ 类型表示对应于标准Python标量(bool,int,float或complex)之一的枚举类型。
-
PyTypeNum_ISFLEXIBLE(num)¶
-
PyDataType_ISFLEXIBLE(descr)¶
-
PyArray_ISFLEXIBLE(obj)¶ 类型表示灵活数组类型之一(
NPY_STRING,NPY_UNICODE或NPY_VOID)。
-
PyTypeNum_ISUSERDEF(num)¶
-
PyDataType_ISUSERDEF(descr)¶
-
PyArray_ISUSERDEF(obj)¶ 类型表示用户定义的类型。
-
PyTypeNum_ISEXTENDED(num)¶
-
PyDataType_ISEXTENDED(descr)¶
-
PyArray_ISEXTENDED(obj)¶ 类型是灵活的或用户定义的。
-
PyTypeNum_ISOBJECT(num)¶
-
PyDataType_ISOBJECT(descr)¶
-
PyArray_ISOBJECT(obj)¶ 类型表示对象数据类型。
-
PyTypeNum_ISBOOL(num)¶
-
PyDataType_ISBOOL(descr)¶
-
PyArray_ISBOOL(obj)¶ 类型表示布尔数据类型。
-
PyDataType_HASFIELDS(descr)¶
-
PyArray_HASFIELDS(obj)¶ 类型具有与其相关联的字段。
-
PyArray_ISNOTSWAPPED(m)¶ 根据数组的数据类型描述符,如果ndarray m的数据区域是机器字节顺序,则评估为真。
-
PyArray_ISBYTESWAPPED(m)¶ 根据数组的数据类型描述符,如果机器字节顺序中ndarray m的数据区不是,则判断为真。
- Bool
PyArray_EquivTypes(PyArray_Descr* type1, PyArray_Descr* type2)¶ 返回
NPY_TRUE如果type1和type2实际上代表此平台的等效类型(每个类型的fortran成员被忽略)。例如,在32位平台上,NPY_LONG和NPY_INT是等效的。否则返回NPY_FALSE。
- Bool
PyArray_EquivArrTypes(PyArrayObject* a1, PyArrayObject * a2)¶ 如果a1和a2是具有此平台的等效类型的数组,则返回
NPY_TRUE。
- Bool
PyArray_EquivTypenums(int typenum1, int typenum2)¶ PyArray_EquivTypes(...)的特殊情况,它不接受灵活的数据类型,但可能更容易调用。
- int
PyArray_EquivByteorders({byteorder} b1, {byteorder} b2)¶ 如果字节顺序字符(
NPY_LITTLE,NPY_BIG,NPY_NATIVE,NPY_IGNORE)等于或等于其规格的本地字节顺序。因此,对于小端机器,NPY_LITTLE和NPY_NATIVE是等效的,它们在大端机器上不等效。
Converting data types¶
- PyObject*
PyArray_Cast(PyArrayObject* arr, int typenum)¶ 主要用于向后兼容数字C-API,以及用于简单转换为非灵活类型。返回一个具有arr元素的新数组对象转换为数据类型typenum,它必须是枚举类型之一,而不是灵活类型。
- PyObject*
PyArray_CastToType(PyArrayObject* arr, PyArray_Descr* type, int fortran)¶ 返回指定的类型的新数组,适当地投射arr的元素。fortran参数指定输出数组的顺序。
- int
PyArray_CastTo(PyArrayObject* out, PyArrayObject* in)¶ 从1.6开始,该函数只调用
PyArray_CopyInto,它处理转换。将中数组的元素转换为数组out。输出数组应该是可写的,具有输入数组中的元素数目的整数倍(多个副本可以放入输出),并且具有作为内置类型之一的数据类型。成功返回0,如果发生错误则返回-1。
- PyArray_VectorUnaryFunc*
PyArray_GetCastFunc(PyArray_Descr* from, int totype)¶ 返回低级别转换函数,从给定描述符转换为内置类型数。如果没有转换函数存在,返回
NULL并设置错误。使用此函数而不是直接访问从 - > f-> cast将允许支持添加到描述符转换字典中的任何用户定义的浇筑函数。
- int
PyArray_CanCastSafely(int fromtype, int totype)¶ 如果数据类型fromtype的数组可以转换为数据类型totype的数组,而不会丢失信息,则返回非零。一个例外是64位整数允许转换为64位浮点值,即使这样可能会丢失大整数的精度,以便在没有展开请求的情况下不增加使用长双精度。使用此功能,不会根据其长度检查灵活的数组类型。
- int
PyArray_CanCastTo(PyArray_Descr* fromtype, PyArray_Descr* totype)¶ PyArray_CanCastTypeTo在NumPy 1.6及更高版本中取代此函数。相当于PyArray_CanCastTypeTo(fromtype,totype,NPY_SAFE_CASTING)。
- int
PyArray_CanCastTypeTo(PyArray_Descr* fromtype, PyArray_Descr* totype, NPY_CASTING casting)¶ 版本1.6中的新功能。
如果数据类型fromtype(可以包括灵活类型)的数组可以安全地转换到数据类型totype(可以包括灵活类型)的数组,则返回非零,根据铸造规则铸造。对于
NPY_SAFE_CASTING的简单类型,这基本上是PyArray_CanCastSafely的包装,但对于诸如字符串或unicode的灵活类型,它会根据其大小生成结果。如果字符串或unicode类型大到足以容纳从中转换的整数/浮点类型的最大值,那么整数和浮点类型只能使用NPY_SAFE_CASTING转换为字符串或unicode类型。
- int
PyArray_CanCastArrayTo(PyArrayObject* arr, PyArray_Descr* totype, NPY_CASTING casting)¶ 版本1.6中的新功能。
如果arr可以根据投射中给出的投射规则投射到totype,则返回非零值。如果arr是数组标量,则会考虑其值,并且当值不会溢出或在转换为较小类型时被截断为整数时,也会返回非零。
这几乎与PyArray_CanCastTypeTo(PyArray_MinScalarType(arr),totype,casting)的结果相同,但它也处理一个特殊情况,因为对于具有相同数量的类型,uint值的集合不是int值的子集位。
- PyArray_Descr*
PyArray_MinScalarType(PyArrayObject* arr)¶ 版本1.6中的新功能。
如果arr是数组,则返回其数据类型描述符,但如果arr是数组标量(具有0个维度),则它会找到最小大小的数据类型值可以转换为不溢出或截断为整数。
此函数不会将复数浮点型或任何布尔型降级为布尔型,但当标量值为正时将将有符号整数降级为无符号整数。
- PyArray_Descr*
PyArray_PromoteTypes(PyArray_Descr* type1, PyArray_Descr* type2)¶ 版本1.6中的新功能。
查找type1和type2可以安全转换的最小尺寸和种类的数据类型。此函数是对称和关联的。字符串或unicode结果将是存储转换为字符串或unicode的输入类型的最大值的正确大小。
- PyArray_Descr*
PyArray_ResultType(npy_intp narrs, PyArrayObject**arrs, npy_intp ndtypes, PyArray_Descr**dtypes)¶ 版本1.6中的新功能。
这将类型提升应用于所有输入,使用用于组合标量和数组的NumPy规则来确定一组操作数的输出类型。这与ufuncs产生的结果类型相同。使用的具体算法如下。
通过首先检查布尔值,整数(int / uint)或浮点(float / complex)中所有数组和标量的最大种类来确定类别。
如果只有标量或标量的最大类别高于数组的最大类别,则数据类型与
PyArray_PromoteTypes组合以生成返回值。否则,对每个数组调用PyArray_MinScalarType,并将生成的数据类型与
PyArray_PromoteTypes组合以生成返回值。对于具有相同位数的类型,int值集合不是uint值的子集,而是在
PyArray_MinScalarType中没有反映出来,但在PyArray_ResultType中作为特殊情况处理。
- int
PyArray_ObjectType(PyObject* op, int mintype)¶ 此函数由
PyArray_MinScalarType和/或PyArray_ResultType替代。此函数用于确定两个或多个数组可以转换为的公共类型。它只适用于非灵活数组类型,因为没有传递项目信息。mintype参数表示可接受的最小类型,op表示将转换为数组的对象。返回值是表示op应该具有的数据类型的枚举类型号。
- void
PyArray_ArrayType(PyObject* op, PyArray_Descr* mintype, PyArray_Descr* outtype)¶ 此函数由
PyArray_ResultType替代。此函数与
PyArray_ObjectType(...)类似,除了它处理灵活数组。mintype参数可以有一个itemize成员,并且outtype参数将有一个itemsize成员至少与对象op 。
- PyArrayObject**
PyArray_ConvertToCommonType(PyObject* op, int* n)¶ 它提供的功能在很大程度上被1.6中引入的迭代器
NpyIter所替代,标记为NPY_ITER_COMMON_DTYPE,或者对所有操作数使用相同的dtype参数。将op中包含的Python对象序列转换为每个都具有相同数据类型的ndarrays的数组。基于类型号(在较小的类型号上选择较大的类型号)选择类型,忽略只是标量的对象。序列的长度在n中返回,
PyArrayObject指针的n长度数组是返回值(或NULL如果发生错误)。返回的数组必须由此例程的调用者(使用PyDataMem_FREE)和其中的所有数组对象(DECREF'd)释放,否则将发生内存泄漏。下面的示例模板代码显示了一个典型的用法:mps = PyArray_ConvertToCommonType(obj, &n); if (mps==NULL) return NULL; {code} <before return> for (i=0; i<n; i++) Py_DECREF(mps[i]); PyDataMem_FREE(mps); {return}
- char*
PyArray_Zero(PyArrayObject* arr)¶ 指向大小为arr - > itemsize的新创建的内存的指针,它保存该类型的表示形式。当不再需要时,使用
PyDataMem_FREE(ret)必须释放返回的指针ret,
- char*
PyArray_One(PyArrayObject* arr)¶ 指向大小为arr - > itemsize的新创建的内存的指针,它保存该类型的表示形式。当不再需要时,使用
PyDataMem_FREE(ret)必须释放返回的指针ret,
New data types¶
- void
PyArray_InitArrFuncs(PyArray_ArrFuncs* f)¶ 将所有函数指针和成员初始化为
NULL。
- int
PyArray_RegisterDataType(PyArray_Descr* dtype)¶ 将数据类型注册为数组的新用户定义数据类型。类型必须填充大多数条目。这不总是被检查,错误可以产生segfaults。特别地,
dtype结构的typeobj成员必须用具有对应于dtype的elsize成员的固定大小的元素大小的Python类型填充。此外,f成员必须具有必需的函数:非零,copyswap,copyswapn,getitem,setitem和cast(如果不需要支持,某些转换函数可以是NULL)。为了避免混淆,你应该选择一个唯一的字符类型,但这不是强制的,不是内部依赖。返回唯一标识类型的用户定义类型编号。然后可以使用返回的类型号从
PyArray_DescrFromType获取指向新结构的指针。如果发生错误,则返回-1。如果此dtype已经注册(仅由指针的地址检查),则返回先前分配的类型号。
- int
PyArray_RegisterCastFunc(PyArray_Descr* descr, int totype, PyArray_VectorUnaryFunc* castfunc)¶ 注册低级别转换函数castfunc,将数据类型descr转换为给定的数据类型编号totype 。任何旧的铸造功能都被覆盖。成功时返回
0或失败时返回-1。
- int
PyArray_RegisterCanCast(PyArray_Descr* descr, int totype, NPY_SCALARKIND scalar)¶ 从给定的标量类型的数据类型对象descr注册数据类型号totype使用标量 =
NPY_NOSCALAR注册数据类型descr的数组可以安全地转换为type_number为totype。
Special functions for NPY_OBJECT¶
- int
PyArray_INCREF(PyArrayObject* op)¶ 用于包含任何Python对象的数组op。它根据op的数据类型增加数组中每个对象的引用计数。如果发生错误,则返回-1,否则返回0。
- void
PyArray_Item_INCREF(char* ptr, PyArray_Descr* dtype)¶ 根据数据类型dtype,在位置ptr处对所有对象进行INCREF的函数。如果ptr是具有任何偏移量的对象的结构化类型的开始,则这将(递归地)增加结构化类型中所有类似对象的项的引用计数。
- int
PyArray_XDECREF(PyArrayObject* op)¶ 用于包含任何Python对象的数组op。它根据op的数据类型减少数组中每个对象的引用计数。正常返回值为0。如果发生错误,则返回-1。
- void
PyArray_Item_XDECREF(char* ptr, PyArray_Descr* dtype)¶ XDECREF函数用于记录数据类型dtype中位置ptr的所有类似对象的项目。这样递归地工作,以便如果
dtype本身具有包含类似对象的项的数据类型的字段,则所有类似于对象的字段将是XDECREF'd。
- void
PyArray_FillObjectArray(PyArrayObject* arr, PyObject* obj)¶ 使用对象数据类型在结构中的所有位置使用单个值obj填充新创建的数组。不执行检查,但arr必须是数据类型
NPY_OBJECT,并且是单段和未初始化的(位置中没有上一个对象)。如果您需要在调用此函数之前减少对象数组中的所有项目,请使用PyArray_DECREF(arr)。
Array flags¶
PyArrayObject结构的flags属性包含数组(由数据成员指向)使用的内存的重要信息。此标志信息必须保持准确或奇怪的结果,甚至可能导致硒缺陷。
有6个(二进制)标志,描述数据缓冲区使用的存储区。这些常数在arrayobject.h中定义,并确定标志的位位置。Python公开了一个很好的基于属性的接口以及一个类似字典的接口,用于获取(和,如果适当的话)这些标志。
所有种类的存储器区域可以由ndarray指向,需要这些标志。如果你在C代码中得到一个任意的PyArrayObject,你需要知道设置的标志。如果你需要保证某种数组(如NPY_ARRAY_C_CONTIGUOUS和NPY_ARRAY_BEHAVED),那么将这些需求传递到PyArray_FromAny函数中。
Basic Array Flags¶
一个ndarray可以有一个数据段,不是一个简单的连续块的良好的记忆你可以操纵。它可能不与字边界对齐(在某些平台上非常重要)。它可能具有不同于机器识别的字节顺序的数据。它可能不可写。它可能是Fortan连续的顺序。数组标志用于指示关于与数组相关联的数据的内容。
在NumPy的1.6版本和更早版本中,以下标志中没有_ARRAY_宏命名空间。这种形式的常量名在1.7中已被弃用。
NPY_ARRAY_C_CONTIGUOUS数据区以C样式连续顺序(最后索引变化最快)。
NPY_ARRAY_F_CONTIGUOUS数据区域是Fortran风格的连续顺序(第一个索引变化最快)。
注意
数组可以同时是C风格和Fortran风格的。这对于1维数组是清楚的,但对于更高维数组也是如此。
Even for contiguous arrays a stride for a given dimension arr.strides[dim] may be arbitrary if arr.shape[dim] == 1 or the array has no elements. 不一般认为self.strides [-1] == self.itemsize / t1>用于C型连续数组或从C API访问数组的self.strides [0] == self.itemsize Fortran风格的连续数组是真的。itemsize的正确方法是PyArray_ITEMSIZE(arr)。
-
NPY_ARRAY_OWNDATA¶ 数据区由此数组所有。
NPY_ARRAY_ALIGNED数据区和所有数组元素都对齐。
NPY_ARRAY_WRITEABLE数据区可以写入。
注意,上面的3个标志是定义的,所以一个新的,行为良好的数组有这些标志被定义为真。
NPY_ARRAY_UPDATEIFCOPY数据区表示一个(行为良好的)副本,当删除此数组时,该副本的信息应该被传回原始。
这是一个特殊的标志,如果这个数组代表一个拷贝,因为用户需要在
PyArray_FromAny中的某些标志,并且一个副本必须由其他数组组成(并且用户要求这个标志在这种情况下设置)。base属性然后指向“misbehaved”数组(设置为read_only)。当具有此标志集的数组被解除分配时,它将其内容复制回“错误的”数组(如果必要的话),并将“错误的”数组重置为NPY_ARRAY_WRITEABLE。如果“misbehaved”数组不是NPY_ARRAY_WRITEABLE开始,则PyArray_FromAny将返回错误,因为不能使用NPY_ARRAY_UPDATEIFCOPY。
PyArray_UpdateFlags (obj, flags) will update the obj->flags for flags which can be any of NPY_ARRAY_C_CONTIGUOUS, NPY_ARRAY_F_CONTIGUOUS, NPY_ARRAY_ALIGNED, or NPY_ARRAY_WRITEABLE.
Combinations of array flags¶
NPY_ARRAY_BEHAVED
NPY_ARRAY_CARRAY
NPY_ARRAY_CARRAY_RO
NPY_ARRAY_FARRAY
NPY_ARRAY_FARRAY_RO
NPY_ARRAY_DEFAULT
-
NPY_ARRAY_UPDATE_ALL¶ NPY_ARRAY_C_CONTIGUOUS|NPY_ARRAY_F_CONTIGUOUS|NPY_ARRAY_ALIGNED
Flag-like constants¶
这些常量在PyArray_FromAny(及其宏形式)中用于指定新数组的所需属性。
NPY_ARRAY_FORCECAST投射到所需类型,即使它不能在不丢失信息的情况下完成。
NPY_ARRAY_ENSURECOPY确保生成的数组是原始数据的副本。
NPY_ARRAY_ENSUREARRAY确保生成的对象是实际的ndarray(或bigndarray),而不是子类。
NPY_ARRAY_NOTSWAPPED仅在
PyArray_CheckFromAny中用于覆盖传入的数据类型对象的字节顺序。
NPY_ARRAY_BEHAVED_NSNPY_ARRAY_ALIGNED|NPY_ARRAY_WRITEABLE|NPY_ARRAY_NOTSWAPPED
Flag checking¶
对于所有这些宏arr必须是PyArray_Type(的子类)的实例,但不进行检查。
-
PyArray_CHKFLAGS(arr, flags)¶ 第一个参数arr必须是一个ndarray或子类。参数flags应为包含数组可能具有的标志的按位组合的整数:
NPY_ARRAY_C_CONTIGUOUS,NPY_ARRAY_F_CONTIGUOUS,NPY_ARRAY_OWNDATA,NPY_ARRAY_ALIGNED,NPY_ARRAY_WRITEABLE,NPY_ARRAY_UPDATEIFCOPY。
-
PyArray_IS_C_CONTIGUOUS(arr)¶ 如果arr是C样式连续,则计算true。
-
PyArray_IS_F_CONTIGUOUS(arr)¶ 如果arr是Fortran风格连续,则计算true。
-
PyArray_ISFORTRAN(arr)¶ 如果arr是Fortran风格连续且不是 C风格连续,则评估为true。
PyArray_IS_F_CONTIGUOUS是测试Fortran风格邻接的正确方法。
-
PyArray_ISWRITEABLE(arr)¶ 如果arr的数据区可以写入,则评估为true
-
PyArray_ISALIGNED(arr)¶ 如果arr的数据区在机器上正确对齐,则评估为true。
-
PyArray_ISBEHAVED(arr)¶ 如果arr的数据区域根据其描述符对齐和可写,并按机器字节顺序,则计算true。
-
PyArray_ISBEHAVED_RO(arr)¶ 如果arr的数据区域以机器字节顺序对齐,则评估为true。
-
PyArray_ISCARRAY(arr)¶ 如果arr的数据区域是C样式连续的,并且
PyArray_ISBEHAVED(arr)为真,则评估为true。
-
PyArray_ISFARRAY(arr)¶ 如果arr的数据区域是Fortran式连续且
PyArray_ISBEHAVED(arr)为真,则评估为true。
-
PyArray_ISCARRAY_RO(arr)¶ 如果arr的数据区是C样式连续,对齐和以机器字节顺序,则评估为true。
-
PyArray_ISFARRAY_RO(arr)¶ 如果arr的数据区域是Fortran风格的连续,对齐,并且在机器字节顺序中,则评估为真。
-
PyArray_ISONESEGMENT(arr)¶ 如果arr的数据区域由单个(C风格或Fortran风格)连续段组成,则评估为true。
- void
PyArray_UpdateFlags(PyArrayObject* arr, int flagmask)¶ 可以从数组对象本身“计算”
NPY_ARRAY_C_CONTIGUOUS,NPY_ARRAY_ALIGNED和NPY_ARRAY_F_CONTIGUOUS数组标志。此例程通过执行所需的计算,更新flagmask中指定的arr的一个或多个标志。
警告
每当使用数组进行可能导致它们更改的操作时,保持标记更新(使用PyArray_UpdateFlags可以帮助)是非常重要的。后来在NumPy中依赖这些标志的状态的计算不重复计算来更新它们。
Array method alternative API¶
Conversion¶
- PyObject*
PyArray_GetField(PyArrayObject* self, PyArray_Descr* dtype, int offset)¶ 等同于
ndarray.getfield(self,dtype,offset)。使用当前数组中指定的偏移量中的数据(以字节为单位)返回给定dtype的新数组。偏移加上新数组类型的itemsize必须小于self - > descr-> elsize或出现错误。使用与原数组相同的形状和步幅。因此,此函数具有从结构化数组返回字段的效果。但是,它也可以用于从任何数组类型中选择特定字节或字节组。
- int
PyArray_SetField(PyArrayObject* self, PyArray_Descr* dtype, int offset, PyObject* val)¶ 等效于
ndarray.setfield(self,val,dtype,offset)。Set the field starting at offset in bytes and of the given dtype to val. 偏移加上dtype - > elsize必须小于self - > descr-> elsize或出现错误。否则,val参数将转换为数组并复制到指向的字段中。如果需要,重复val的元素以填充目标数组。但是,目标中的元素数必须是val中元素数的整数倍数。 。
- PyObject*
PyArray_Byteswap(PyArrayObject* self, Bool inplace)¶ 等效于
ndarray.byteswap(self,inplace)。返回其数据区域已进行字节交换的数组。如果inplace为非零,则执行byteswap inplace并返回对self的引用。否则,创建字节交换副本并保持不变。
- PyObject*
PyArray_NewCopy(PyArrayObject* old, NPY_ORDER order)¶ 等同于
ndarray.copy(self,fortran)。制作旧数组的副本。返回的数组总是对齐和可写的,数据解释与旧数组相同。如果order是NPY_CORDER,则返回C风格的连续数组。如果order是NPY_FORTRANORDER,则返回Fortran风格的连续数组。如果顺序是NPY_ANYORDER,则返回的数组是Fortran风格的连续的,如果旧的;否则,它是C型连续的。
- PyObject*
PyArray_ToList(PyArrayObject* self)¶ 等效于
ndarray.tolist(self)。从self返回嵌套的Python列表。
- PyObject*
PyArray_ToString(PyArrayObject* self, NPY_ORDER order)¶ 等效于
ndarray.tobytes(self,order)。在Python字符串中返回此数组的字节。
- PyObject*
PyArray_ToFile(PyArrayObject* self, FILE* fp, char* sep, char* format)¶ 以C样式连续方式将self的内容写入文件指针fp。如果sep是字符串“”或
NULL,则将数据写为二进制字节。否则,使用sep字符串作为项目分隔符,将self的内容作为文本写入。每个项目将打印到文件。如果格式字符串不是NULL或“”,那么它是一个Python打印语句格式字符串,显示如何写入项目。
- int
PyArray_Dump(PyObject* self, PyObject* file, int protocol)¶ 将self中的对象拣到给定的文件(字符串或Python文件对象)。如果文件是Python字符串,它被认为是一个文件的名称,然后以二进制模式打开。使用给定的协议(如果协议为负值,或使用最高可用值)。这是cPickle.dump(self,文件,协议)的简单包装器。
- PyObject*
PyArray_Dumps(PyObject* self, int protocol)¶ 将self中的对象转换为Python字符串并返回。使用提供的Pickle 协议(如果协议为负值,则为最高可用)。
- int
PyArray_FillWithScalar(PyArrayObject* arr, PyObject* obj)¶ 使用给定的标量对象obj填充数组arr。首先将对象转换为arr的数据类型,然后复制到每个位置。如果发生错误,则返回-1,否则返回0。
- PyObject*
PyArray_View(PyArrayObject* self, PyArray_Descr* dtype, PyTypeObject *ptype)¶ 等效于
ndarray.view(self,dtype)。返回数组self的新视图可能是不同的数据类型,dtype和不同的数组子类ptype。如果dtype是
NULL,则返回的数组将具有与self相同的数据类型。新数据类型必须与self的大小一致。要么项目必须相同,要么self必须是单段,并且字节总数必须相同。在后一种情况下,返回的数组的维度将在最后一个(或第一个为Fortran风格的连续数组)维度中更改。返回的数组和self的数据区完全相同。
Shape Manipulation¶
- PyObject*
PyArray_Newshape(PyArrayObject* self, PyArray_Dims* newshape, NPY_ORDER order)¶ 结果将是一个新的数组(如果可能,指向与self相同的内存位置),但具有由newshape给出的形状。如果新形状与self的步幅不兼容,则将返回具有新指定形状的数组的副本。
- PyObject*
PyArray_Reshape(PyArrayObject* self, PyObject* shape)¶ 等同于
ndarray.reshape(self,shape)其中shape是一个序列。将形状转换为PyArray_Dims结构,并在内部调用PyArray_Newshape。对于向后兼容性 - 不推荐
- PyObject*
PyArray_Squeeze(PyArrayObject* self)¶ 等同于
ndarray.squeeze(self)。返回self的新视图,其中从形状中删除所有长度为1的维度。
警告
矩阵对象总是2维的。因此,PyArray_Squeeze对矩阵子类的数组没有影响。
- PyObject*
PyArray_SwapAxes(PyArrayObject* self, int a1, int a2)¶ 等效于
ndarray.swapaxes(self,a1,a2)。返回的数组是self中的数据的新视图,其中给定轴,a1和a2,已交换。
- PyObject*
PyArray_Resize(PyArrayObject* self, PyArray_Dims* newshape, int refcheck, NPY_ORDER fortran)¶ 等于
ndarray.resize(self,newshape,refcheck=refcheck = fortran)。此功能仅适用于单段数组。它会改变self的形状,并且如果newshape具有与旧形状不同的元素总数,则会重新分配self的内存。If reallocation is necessary, then self must own its data, have self ->base==NULL, have self ->weakrefs==NULL, and (unless refcheck is 0) not be referenced by any other array. fortran参数可以是NPY_ANYORDER,NPY_CORDER或NPY_FORTRANORDER。它目前没有效果。最终,它可以用于确定在构造不同维度的数组时,调整大小操作应如何查看数据。成功时返回None,出错时返回NULL。
- PyObject*
PyArray_Transpose(PyArrayObject* self, PyArray_Dims* permute)¶ 等同于
ndarray.transpose(self,permute)。根据数据结构permute,允许ndarray对象的轴self并返回结果。如果permute是NULL,则结果数组的轴反转。例如,如果self具有形状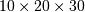 ,并且permute
,并且permute .ptr为(0,2,1),则结果的形状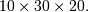 如果permute为
如果permute为NULL,则结果的形状为
- PyObject*
PyArray_Flatten(PyArrayObject* self, NPY_ORDER order)¶ 等同于
ndarray.flatten(self,order)。返回数组的1-d副本。如果order是NPY_FORTRANORDER,则以Fortran顺序扫描元素(第一维度的变化最快)。如果order是NPY_CORDER,则以C顺序扫描self的元素(最后一个维度变化最快)。如果orderNPY_ANYORDER,则PyArray_ISFORTRAN(self)的结果用于确定要展平的顺序。
- PyObject*
PyArray_Ravel(PyArrayObject* self, NPY_ORDER order)¶ 等同于self .ravel(order)。除了order为0和self之外,与
PyArray_Flatten(self,order t6>是C型连续,形状改变,但不执行复制。
Item selection and manipulation¶
- PyObject*
PyArray_TakeFrom(PyArrayObject* self, PyObject* indices, int axis, PyArrayObject* ret, NPY_CLIPMODE clipmode)¶ 等于
ndarray.take(self,索引,轴,ret通过在C中设置axis =NPY_MAXDIMS可以获得axis = None中的沿着给定的轴的整数值索引表示。clipmode参数可以是NPY_RAISE,NPY_WRAP或NPY_CLIP以指示如何处理超出索引。ret参数可以指定输出数组,而不是在内部创建。
- PyObject*
PyArray_PutTo(PyArrayObject* self, PyObject* values, PyObject* indices, NPY_CLIPMODE clipmode)¶ 等效于self .put(值,索引,clipmode)。将值置入self中相应的(扁平)索引。如果值太小,则会根据需要重复。
- PyObject*
PyArray_PutMask(PyArrayObject* self, PyObject* values, PyObject* mask)¶ 在掩码中的对应位置(使用展平的上下文)为真时,将值置于自中。掩码和自身数组必须具有相同的元素总数。如果值太小,则将根据需要重复。
- PyObject*
PyArray_Repeat(PyArrayObject* self, PyObject* op, int axis)¶ 等同于
ndarray.repeat(self,op,axis)。沿给定的轴复制self,op的元素。op是标量整数或长度self - > dimension [axis]的序列,表示沿轴重复每个项目的次数。
- PyObject*
PyArray_Choose(PyArrayObject* self, PyObject* op, PyArrayObject* ret, NPY_CLIPMODE clipmode)¶ 等效于
ndarray.choose(self,op,ret,clipmode)。基于self中的整数值,从op中的数组序列中选择元素,创建一个新的数组。数组必须都可以广播到相同的形状,self中的条目应该在0和len之间(op)。输出位于ret中,除非NULL,在这种情况下会创建新的输出。clipmode参数确定self中的条目不在0和len(op)之间的行为。-
NPY_RAISE¶ 提高ValueError;
-
NPY_WRAP¶ wrap values < 0 by adding len(op) and values >=len(op) by subtracting len(op) until they are in range;
-
NPY_CLIP¶ 所有值都剪裁到区域[0,len(op))。
-
- PyObject*
PyArray_Sort(PyArrayObject* self, int axis)¶ 等效于
ndarray.sort(self,轴)。返回具有沿轴排序的self项目的数组。
- PyObject*
PyArray_ArgSort(PyArrayObject* self, int axis)¶ 等效于
ndarray.argsort(自身,轴)。返回一个索引数组,沿着给定的axis选择这些索引将返回self的排序版本。如果self - > descr是定义了字段的数据类型,则使用自 - > descr->名称来确定排序顺序。第一个字段相等的比较将使用第二个字段,以此类推。要更改结构化数组的排序顺序,请创建具有不同名称顺序的新数据类型,并使用该新数据类型构建数组的视图。
- PyObject*
PyArray_LexSort(PyObject* sort_keys, int axis)¶ 给定一个相同形状的数组(sort_keys)序列,返回一个数组的索引(类似于
PyArray_ArgSort(...)),它将按数组排序数组。词典式排序指定当发现两个键相等时,顺序基于随后的键的比较。需要为类型定义合并排序(保留相等的条目未移动)。通过使用第一个sort_key首先对索引排序,然后使用第二个sort_key等来完成排序。这相当于lexsort(sort_keys,axis)Python命令。由于合并排序的工作方式,请务必理解sort_keys必须在的顺序(与比较两个元素时使用的顺序相反)。如果这些数组都在结构化数组中收集,则
PyArray_Sort(...)也可以用于直接对数组进行排序。
- PyObject*
PyArray_SearchSorted(PyArrayObject* self, PyObject* values, NPY_SEARCHSIDE side, PyObject* perm)¶ 等同于
ndarray.searchsorted(self,值,侧,perm)。假设self是以升序排列的1-d数组,则输出是与值相同形状的索引的数组,使得如果值插入索引之前,将保留self的顺序。没有检查自我是否是升序。侧参数指示返回的索引是否应为第一个合适位置(如果
NPY_SEARCHLEFT)或最后一个(ifNPY_SEARCHRIGHT)的索引。分类器参数,如果不是
NULL,必须是与self长度相同的整数索引的1D数组,将其按升序排序。这通常是调用PyArray_ArgSort(...)的结果。二进制搜索用于查找所需的插入点。
- int
PyArray_Partition(PyArrayObject *self, PyArrayObject * ktharray, int axis, NPY_SELECTKIND which)¶ 等效于
ndarray.partition(self,ktharray,axis,kind)。对数组进行分区,使得ktharray索引的元素的值位于数组完全排序的位置,并且所有元素小于第k个之前,所有元素等于或大于第k个元素。分区内所有元素的排序未定义。如果self - > descr是定义了字段的数据类型,则使用自 - > descr->名称来确定排序顺序。第一个字段相等的比较将使用第二个字段,以此类推。要更改结构化数组的排序顺序,请创建具有不同名称顺序的新数据类型,并使用该新数据类型构建数组的视图。成功时返回零,失败时返回-1。
- PyObject*
PyArray_ArgPartition(PyArrayObject *op, PyArrayObject * ktharray, int axis, NPY_SELECTKIND which)¶ 等同于
ndarray.argpartition(self,ktharray,axis,kind)。返回一个索引数组,沿着给定的axis选择这些索引将返回self的分区版本。
- PyObject*
PyArray_Diagonal(PyArrayObject* self, int offset, int axis1, int axis2)¶ 等效于
ndarray.diagonal(self,offset,axis1,axis2)。返回由axis1和axis2定义的2-d数组的偏移对角线。
- npy_intp
PyArray_CountNonzero(PyArrayObject* self)¶ 版本1.6中的新功能。
计数数组对象self中非零元素的数量。
- PyObject*
PyArray_Nonzero(PyArrayObject* self)¶ 等效于
ndarray.nonzero(self)。返回索引数组的元组,该元组选择非零的self元素。如果(nd =PyArray_NDIM(self))== 1,则返回单个索引数组。索引数组具有数据类型NPY_INTP。如果返回一个元组(nd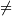 1),则其长度为nd。
1),则其长度为nd。
- PyObject*
PyArray_Compress(PyArrayObject* self, PyObject* condition, int axis, PyArrayObject* out)¶ 等同于
ndarray.compress(self,条件,轴)。返回轴中对应于条件的元素为真的元素。
Calculation¶
小费
在NPY_MAXDIMS中传递轴以获得通过在Python中传递轴 = None 1-d数组)。
- PyObject*
PyArray_ArgMax(PyArrayObject* self, int axis, PyArrayObject* out)¶ 等效于
ndarray.argmax(self,axis)。返回self沿轴的最大元素的索引。
- PyObject*
PyArray_ArgMin(PyArrayObject* self, int axis, PyArrayObject* out)¶ Equivalent to
ndarray.argmin(self, axis). 返回self沿轴的最小元素的索引。
注意
out参数指定在何处放置结果。如果out为NULL,则创建输出数组,否则输出放在输出中,其必须是正确的大小和类型。即使out不为NULL,也始终返回对输出数组的新引用。例程的调用者有责任DECREF,如果不为NULL或发生内存泄漏。
- PyObject*
PyArray_Max(PyArrayObject* self, int axis, PyArrayObject* out)¶ 等效于
ndarray.max(self,axis)。沿着给定的轴返回self的最大元素。当结果是单个元素时,返回numpy标量而不是ndarray。
- PyObject*
PyArray_Min(PyArrayObject* self, int axis, PyArrayObject* out)¶ 等效于
ndarray.min(self,axis)。沿给定的轴返回self的最小元素。当结果是单个元素时,返回numpy标量而不是ndarray。
- PyObject*
PyArray_Ptp(PyArrayObject* self, int axis, PyArrayObject* out)¶ 等同于
ndarray.ptp(self,轴)。返回沿轴的self的最大元素与沿轴的self的最小元素之间的差值。当结果是单个元素时,返回numpy标量而不是ndarray。
注意
rtype参数指定要进行减少的数据类型。如果数组的数据类型不足以处理输出,这是很重要的。默认情况下,对于“add”和“multiply”ufuncs(构成mean,sum,cumsum,prod和cumprod函数的基础),所有整数数据类型至少与NPY_LONG )。
- PyObject*
PyArray_Mean(PyArrayObject* self, int axis, int rtype, PyArrayObject* out)¶ 等效于
ndarray.mean(self,axis,rtype)。返回沿给定轴的元素的平均值,使用枚举类型rtype作为求和的数据类型。对于rtype,使用NPY_NOTYPE获取默认总和行为。
- PyObject*
PyArray_Trace(PyArrayObject* self, int offset, int axis1, int axis2, int rtype, PyArrayObject* out)¶ Equivalent to
ndarray.trace(self, offset, axis1, axis2, rtype). Return the sum (using rtype as the data type of summation) over the offset diagonal elements of the 2-d arrays defined by axis1 and axis2 variables. 正偏移选择主对角线上方的对角线。负偏移选择主对角线下方的对角线。
- PyObject*
PyArray_Clip(PyArrayObject* self, PyObject* min, PyObject* max)¶ 等效于
ndarray.clip(self,min,max)。剪辑数组self,以使大于max的值固定为max,小于min的值为固定为min。
- PyObject*
PyArray_Conjugate(PyArrayObject* self)¶ 等效于
ndarray.conjugate(self)。返回self的复共轭。如果self不是复杂数据类型,则返回self和引用。
- PyObject*
PyArray_Round(PyArrayObject* self, int decimals, PyArrayObject* out)¶ 等效于
ndarray.round(self,小数,out)。返回具有四舍五入到最接近的小数位的元素的数组。小数位被定义为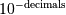 数字,使得负的小数导致四舍五入到最接近的10,100等。如果out是
数字,使得负的小数导致四舍五入到最接近的10,100等。如果out是NULL,则创建输出数组,否则输出放置在out中,它必须是正确的大小和类型。
- PyObject*
PyArray_Std(PyArrayObject* self, int axis, int rtype, PyArrayObject* out)¶ 等效于
ndarray.std(self,axis,rtype)。使用沿轴的数据返回标准偏差,转换为数据类型rtype。
- PyObject*
PyArray_Sum(PyArrayObject* self, int axis, int rtype, PyArrayObject* out)¶ 等效于
ndarray.sum(self,axis,rtype)。返回沿轴的self中的元素的1-d向量和。在将数据转换为数据类型rtype之后执行求和。
- PyObject*
PyArray_CumSum(PyArrayObject* self, int axis, int rtype, PyArrayObject* out)¶ 等效于
ndarray.cumsum(self,axis,rtype)。返回沿轴的self中的元素的累积1-d总和。在将数据转换为数据类型rtype之后执行求和。
- PyObject*
PyArray_Prod(PyArrayObject* self, int axis, int rtype, PyArrayObject* out)¶ 等同于
ndarray.prod(self,axis,rtype)。沿轴返回self中的元素的1-d乘积。将数据转换为数据类型rtype后执行产品。
- PyObject*
PyArray_CumProd(PyArrayObject* self, int axis, int rtype, PyArrayObject* out)¶ 等效于
ndarray.cumprod(self,axis,rtype)。沿axis返回self中元素的1-d累积积。将数据转换为数据类型rtype后执行产品。
- PyObject*
PyArray_All(PyArrayObject* self, int axis, PyArrayObject* out)¶ 等效于
ndarray.all(self,axis)。对于由axis定义的self的每个1-d子数组,返回一个具有True元素的数组,其中所有元素都为True。
- PyObject*
PyArray_Any(PyArrayObject* self, int axis, PyArrayObject* out)¶ 等效于
ndarray.any(self,axis)。对于由轴定义的self的每个1-d子数组,返回一个具有True元素的数组,其中任何元素都为True。
Functions¶
Array Functions¶
- int
PyArray_AsCArray(PyObject** op, void* ptr, npy_intp* dims, int nd, int typenum, int itemsize)¶ 有时,访问作为C风格多维数组的多维数组是有用的,使得可以使用C的a [i] [j] [k]语法来实现算法。这个例程返回一个指针,ptr,它模拟这种C风格的数组,用于1,2和3-d ndarrays。
参数: - op - 任何Python对象的地址。这个Python对象将被替换为由最后两个参数指定的给定数据类型的等效行为,C样式连续的ndarray。确保以这种方式将引用挪到输入对象是合理的。
- ptr - 指向(c-type *为1-d,ctype **为2-d或ctype ***为3-d)变量的地址,其中ctype是数据的等效C类型类型。返回时,ptr将可寻址为1-d,2-d或3-d数组。
- dims - 包含数组对象形状的输出数组。这个数组给出了将要发生的任何循环的边界。
- nd - 数组的维数(1,2或3)。
- typenum - 数组的预期数据类型。
- itemsize - 仅当typenum表示灵活数组时,才需要此参数。否则应为0。
注意
对于2-d和3-d数组,C风格数组的模拟是不完整的。例如,模拟的指针数组不能传递到期望特定的,静态定义的2-d和3-d数组的子程序。要传递到需要这些输入的函数,您必须静态定义所需的数组并复制数据。
- int
PyArray_Free(PyObject* op, void* ptr)¶ 必须使用从
PyArray_AsCArray(...)返回的相同对象和内存位置进行调用。这个函数清理内存,否则会泄露。
- PyObject*
PyArray_MatrixProduct(PyObject* obj1, PyObject* obj)¶ 计算obj1的最后一个维度和obj2的第二个到最后一个维度的乘积和。对于2-d数组,这是一个矩阵积。数组都未共轭。
- PyObject*
PyArray_MatrixProduct2(PyObject* obj1, PyObject* obj, PyArrayObject* out)¶ 版本1.6中的新功能。
与PyArray_MatrixProduct相同,但将结果存储在out中。
- PyObject*
PyArray_EinsteinSum(char* subscripts, npy_intp nop, PyArrayObject** op_in, PyArray_Descr* dtype, NPY_ORDER order, NPY_CASTING casting, PyArrayObject* out)¶ 版本1.6中的新功能。
将爱因斯坦求和约定应用于提供的数组操作数,返回一个新数组或将结果放在out中。下标中的字符串是以逗号分隔的索引字母列表。操作数的数目在nop中,而op_in是包含这些操作数的数组。The data type of the output can be forced with dtype, the output order can be forced with order (
NPY_KEEPORDERis recommended), and when dtype is specified, casting indicates how permissive the data conversion should be.有关详细信息,请参阅
einsum功能。
- PyObject*
PyArray_Correlate(PyObject* op1, PyObject* op2, int mode)¶ 计算1-d数组op1和op2的1-d相关性。通过将op1乘以op2的移位版本并对结果求和,在每个输出点计算相关性。作为移位的结果,在op1和op2的定义范围之外的所需值被解释为零。The mode determines how many shifts to return: 0 - return only shifts that did not need to assume zero- values; 1 - return an object that is the same size as op1, 2 - return all possible shifts (any overlap at all is accepted).
笔记
这不计算通常的相关性:如果op2大于op1,则参数被交换,并且从不采用复数数组的共轭。对于通常的信号处理相关性,参见PyArray_Correlate2。
- PyObject*
PyArray_Correlate2(PyObject* op1, PyObject* op2, int mode)¶ PyArray_Correlate的更新版本,它使用1d数组的相关性的通常定义。通过将op1乘以op2的移位版本并对结果求和,在每个输出点计算相关性。作为移位的结果,在op1和op2的定义范围之外的所需值被解释为零。模式决定了转移到返回:0 - 只返回并不需要承担零值的变化; 1 - 返回一个对象,它是大小 OP1 T0>,2个相同 - 返回所有可能发生的变化(在所有的任何重叠被接受)。
笔记
计算z如下:
z[k] = sum_n op1[n] * conj(op2[n+k])
Other functions¶
- Bool
PyArray_CheckStrides(int elsize, int nd, npy_intp numbytes, npy_intp* dims, npy_intp* newstrides)¶ Determine if newstrides is a strides array consistent with the memory of an nd -dimensional array with shape
dimsand element-size, elsize. 检查newstrides数组以查看在每个方向上跳过所提供的字节数是否意味着跳过多于numbytes,这是可用存储器段的假定大小。If numbytes is 0, then an equivalent numbytes is computed assuming nd, dims, and elsize refer to a single-segment array. 如果newstrides是可接受的,则返回NPY_TRUE,否则返回NPY_FALSE。
- npy_intp
PyArray_MultiplyList(npy_intp* seq, int n)¶
- int
PyArray_MultiplyIntList(int* seq, int n)¶ 这两个例程都乘以整数的n长度数组,seq,并返回结果。不执行溢出检查。
- int
PyArray_CompareLists(npy_intp* l1, npy_intp* l2, int n)¶ 给定两个n长度的整数数组,l1和l2,如果列表相同,则返回1;否则,返回0。
Auxiliary Data With Object Semantics¶
版本1.7.0中的新功能。
-
NpyAuxData¶
当使用由其他类型(例如struct dtype)组成的更复杂的dtypes时,创建操作dtypes的内循环需要继承附加数据。NumPy通过struct NpyAuxData支持这个想法,强制使用一些约定,以便可以这样做。
定义NpyAuxData类似于在C ++中定义类,但是对象语义必须手动跟踪,因为API在C中。这里是一个函数的示例,它使用元素复印机函数作为原语。:
typedef struct {
NpyAuxData base;
ElementCopier_Func *func;
NpyAuxData *funcdata;
} eldoubler_aux_data;
void free_element_doubler_aux_data(NpyAuxData *data)
{
eldoubler_aux_data *d = (eldoubler_aux_data *)data;
/* Free the memory owned by this auxadata */
NPY_AUXDATA_FREE(d->funcdata);
PyArray_free(d);
}
NpyAuxData *clone_element_doubler_aux_data(NpyAuxData *data)
{
eldoubler_aux_data *ret = PyArray_malloc(sizeof(eldoubler_aux_data));
if (ret == NULL) {
return NULL;
}
/* Raw copy of all data */
memcpy(ret, data, sizeof(eldoubler_aux_data));
/* Fix up the owned auxdata so we have our own copy */
ret->funcdata = NPY_AUXDATA_CLONE(ret->funcdata);
if (ret->funcdata == NULL) {
PyArray_free(ret);
return NULL;
}
return (NpyAuxData *)ret;
}
NpyAuxData *create_element_doubler_aux_data(
ElementCopier_Func *func,
NpyAuxData *funcdata)
{
eldoubler_aux_data *ret = PyArray_malloc(sizeof(eldoubler_aux_data));
if (ret == NULL) {
PyErr_NoMemory();
return NULL;
}
memset(&ret, 0, sizeof(eldoubler_aux_data));
ret->base->free = &free_element_doubler_aux_data;
ret->base->clone = &clone_element_doubler_aux_data;
ret->func = func;
ret->funcdata = funcdata;
return (NpyAuxData *)ret;
}
-
NpyAuxData_FreeFunc¶ NpyAuxData的函数指针类型自由函数。
-
NpyAuxData_CloneFunc¶ NpyAuxData克隆函数的函数指针类型。这些函数不应该设置Python异常错误,因为它们可能从多线程上下文中调用。
-
NPY_AUXDATA_FREE(auxdata)¶ 一个宏适当地调用auxdata的自由函数,如果auxdata为NULL,则不执行任何操作。
-
NPY_AUXDATA_CLONE(auxdata)¶ 一个宏,适当地调用auxdata的克隆函数,返回辅助数据的深拷贝。
Array Iterators¶
从NumPy 1.6.0开始,这些数组迭代器被新的数组迭代器NpyIter所取代。
数组迭代器是一种快速有效地访问N维数组元素的简单方法。部分2提供了有关循环数组的有用方法的更多描述和示例。
- PyObject*
PyArray_IterNew(PyObject* arr)¶ 从数组arr返回一个数组迭代器对象。这相当于arr。flat。数组迭代器对象使得以C样式连续方式循环N维非连续数组变得容易。
- PyObject*
PyArray_IterAllButAxis(PyObject* arr, int *axis)¶ 返回一个数组迭代器,它将遍历所有轴,但在* axis中提供。返回的迭代器不能与
PyArray_ITER_GOTO1D一起使用。这个迭代器可以用来写一些类似于ufuncs的东西,其中最大轴上的循环由单独的子例程完成。如果* axis为负,那么* axis将设置为具有最小步幅的轴,并且将使用该轴。
- PyObject *
PyArray_BroadcastToShape(PyObject* arr, npy_intp *dimensions, int nd)¶ 返回一个数组迭代器,该迭代器广播以作为由维和nd提供的形状的数组进行迭代。
- void
PyArray_ITER_NEXT(PyObject* iterator)¶ 使迭代器的索引和dataptr成员偏向以指向数组的下一个元素。如果数组不是(C风格)连续的,也增加N维坐标数组。
- void
PyArray_ITER_GOTO(PyObject* iterator, npy_intp* destination)¶ 设置迭代器 index,dataptr并将成员坐标指向由N维c阵列目标指示的数组中的位置,其大小必须至少 iterator - > nd_m1 + 1。
Broadcasting (multi-iterators)¶
- PyObject*
PyArray_MultiIterNew(int num, ...)¶ 广播的简化接口。此函数接受要广播的数组的数目,然后是num extra(
PyObject *这些参数被转换为数组,并创建迭代器。PyArray_Broadcast。然后返回所得到的广播的多迭代器对象。然后可以使用单个循环并使用PyArray_MultiIter_NEXT(..)执行广播操作
- void
PyArray_MultiIter_GOTO(PyObject* multi, npy_intp* destination)¶ 将多迭代器对象中的每个迭代器多推进到给定的
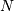 二维目标,其中是广播数组。
二维目标,其中是广播数组。
- void
PyArray_MultiIter_GOTO1D(PyObject* multi, npy_intp index)¶ 将多重迭代器对象多中的每个迭代器推进到索引的对应位置到展平的广播数组中。
- int
PyArray_Broadcast(PyArrayMultiIterObject* mit)¶ 此功能封装了广播规则。mit容器应该已经包含需要广播的所有数组的迭代器。在返回时,这些迭代器将被调整,使得每个迭代将同时完成广播。如果发生错误,则返回负数。
- int
PyArray_RemoveSmallest(PyArrayMultiIterObject* mit)¶ 此函数接受先前已“广播”的多迭代器对象,在广播结果中找到具有最小“和步长”的维度,并适配所有迭代器,以便不迭代该维度(通过有效地使它们长度-1)。返回相应的维度,除非mit - > nd为0,则返回-1。该函数对于构造类似于广播其输入的类似ufunc的例程很有用,然后调用该例程的1-d版本作为内循环。这个1-d版本通常针对速度进行优化,因此,应该在不需要大步幅跳跃的轴上执行循环。
Neighborhood iterator¶
版本1.4.0中的新功能。
邻域迭代器是迭代器对象的子类,可以用于遍历点的邻域。例如,您可能想要在3D图像的每个体素上迭代,并且对于每个这样的体素,在超立方体上迭代。邻域迭代器自动处理边界,从而使这种代码比手动边界处理更容易编写,代价是轻微的开销。
- PyObject*
PyArray_NeighborhoodIterNew(PyArrayIterObject* iter, npy_intp bounds, int mode, PyArrayObject* fill_value)¶ 此函数从现有的迭代器创建一个新的邻域迭代器。邻域将相对于由iter当前指向的位置计算,边界定义邻域迭代器的形状,模式参数定义边界处理模式。
bounds参数预期为(2 * iter-> ao-> nd)数组,例如范围bound [2 * i] - > bounds [2 * i + 1]范围,对于维度i(两个边界都包括在行走坐标中)。边界应该为每个维度排序(bounds [2 * i]
模式应为以下之一:
- NPY_NEIGHBORHOOD_ITER_ZERO_PADDING:零填充。外边界值将为0。
- NPY_NEIGHBORHOOD_ITER_ONE_PADDING:一个填充,外边界值将为1。
- NPY_NEIGHBORHOOD_ITER_CONSTANT_PADDING:常量填充。外部边界值将与fill_value中的第一个项目相同。
- NPY_NEIGHBORHOOD_ITER_MIRROR_PADDING:镜像填充。外部边界值将像数组项目被镜像一样。例如,对于数组[1,2,3,4],x [-2]为2,x [-2]为1,x [4]为4,x [等等...
- NPY_NEIGHBORHOOD_ITER_CIRCULAR_PADDING:圆形填充。外部边界值将像数组被重复一样。例如,对于数组[1,2,3,4],x [-2]为3,x [-2]为4,x [4]为1,x [5]等等...
如果模式是常量填充(NPY_NEIGHBORHOOD_ITER_CONSTANT_PADDING),fill_value应指向一个保存填充值的数组对象(如果数组包含多个项目,则第一个项目将是填充值)。对于其他情况,fill_value可以为NULL。
- 迭代器持有对iter的引用
- 在失败时返回NULL(在这种情况下,iter的引用计数不更改)
- iter本身可以是一个Neighborhood迭代器:这可以用于.e.g自动边界处理
- 该函数返回的对象应该安全地用作正常的迭代器
- 如果iter的位置改变,对PyArrayNeighborhoodIter_Next的任何后续调用是未定义的行为,并且必须调用PyArrayNeighborhoodIter_Reset。
PyArrayIterObject \*iter; PyArrayNeighborhoodIterObject \*neigh_iter; iter = PyArray_IterNew(x); //For a 3x3 kernel bounds = {-1, 1, -1, 1}; neigh_iter = (PyArrayNeighborhoodIterObject*)PyArrayNeighborhoodIter_New( iter, bounds, NPY_NEIGHBORHOOD_ITER_ZERO_PADDING, NULL); for(i = 0; i < iter->size; ++i) { for (j = 0; j < neigh_iter->size; ++j) { // Walk around the item currently pointed by iter->dataptr PyArrayNeighborhoodIter_Next(neigh_iter); } // Move to the next point of iter PyArrayIter_Next(iter); PyArrayNeighborhoodIter_Reset(neigh_iter); }
- int
PyArrayNeighborhoodIter_Reset(PyArrayNeighborhoodIterObject* iter)¶ 将迭代器位置重置为邻域的第一个点。这应该在每当PyArray_NeighborhoodIterObject给出的iter参数被改变时被调用(见例子)
- int
PyArrayNeighborhoodIter_Next(PyArrayNeighborhoodIterObject* iter)¶ 调用后,iter-> dataptr指向邻域的下一个点。在访问邻域的每个点之后调用此函数是未定义的。
Array Scalars¶
- PyObject*
PyArray_Return(PyArrayObject* arr)¶ 此函数窃取对arr的引用。
此函数检查arr是否为0维数组,如果是,返回相应的数组标量。当0维数组可以返回到Python时,应该使用它。
- PyObject*
PyArray_Scalar(void* data, PyArray_Descr* dtype, PyObject* itemsize)¶ 通过从数据所指向的内存中复制返回给定枚举typenum和itemsize的数组标量对象。如果swap为非零,则此函数将字节交换数据(如果适用于数据类型),因为数组标量总是以正确的机器字节顺序。
- PyObject*
PyArray_ToScalar(void* data, PyArrayObject* arr)¶ 返回从由数据指向的内存复制的数组对象arr指示的类型和项目大小的数组标量对象,如果arr 不是机器字节顺序。
- PyObject*
PyArray_FromScalar(PyObject* scalar, PyArray_Descr* outcode)¶ 从标量返回由outcode确定的类型的0维数组,它应该是数组标量对象。如果outcode为NULL,则从标量确定类型。
- void
PyArray_ScalarAsCtype(PyObject* scalar, void* ctypeptr)¶ 在ctypeptr中返回一个指向数组标量中实际值的指针。没有错误检查,因此标量必须是数组标量对象,ctypeptr必须有足够的空间来保存正确的类型。对于灵活大小的类型,将数据的指针复制到ctypeptr的内存中,对于所有其他类型,实际数据将复制到ctypeptr 。
- void
PyArray_CastScalarToCtype(PyObject* scalar, void* ctypeptr, PyArray_Descr* outcode)¶ 将数组标量标量中的数据(转换为outcode指示的数据类型)返回到ctypeptr其必须足够大以处理传入的存储器)。
- PyObject*
PyArray_TypeObjectFromType(int type)¶ 从类型号类型返回标量类型对象。相当于
PyArray_DescrFromType(type) - > typeobj,除了引用计数和错误检查。在成功时返回对typeObject的新引用,或在失败时返回NULL。
- NPY_SCALARKIND
PyArray_ScalarKind(int typenum, PyArrayObject** arr)¶ 有关NumPy 1.6.0中引入的替代机制,请参阅函数
PyArray_MinScalarType。返回由typenum表示的标量和* arr中的数组(如果arr不是
NULL)。数组假定为秩0,并且仅当typenum表示有符号整数时使用。If arr is notNULLand the first element is negative thenNPY_INTNEG_SCALARis returned, otherwiseNPY_INTPOS_SCALARis returned. 可能的返回值为NPY_{kind}_SCALAR其中{kind}可以是INTPOS,INTNEG, FLOAT,COMPLEX,BOOL或OBJECT。NPY_NOSCALAR也是枚举值NPY_SCALARKIND变量可以承担。
- int
PyArray_CanCoerceScalar(char thistype, char neededtype, NPY_SCALARKIND scalar)¶ 有关NumPy类型升级的详细信息,请参阅函数
PyArray_ResultType,在NumPy 1.6.0中更新。实现标量强制的规则。如果此函数返回非零,则标量只会从thistype静默强制转换为requiredtype。如果标量为
NPY_NOSCALAR,则此函数等效于PyArray_CanCastSafely。规则是相同KIND的标量可以被强制转换为相同KIND的数组。这个规则意味着高精度标量永远不会导致相同KIND的低精度数组被upcast。
Data-type descriptors¶
警告
数据类型对象必须引用计数,以便了解对不同C-API调用的数据类型引用的操作。标准规则是,当返回一个数据类型对象时,它是一个新的引用。除非另有说明,采用PyArray_Descr *对象并返回数组类型的数组类型的函数。因此,您必须拥有对用作此类函数的输入的任何数据类型对象的引用。
- int
PyArray_DescrCheck(PyObject* obj)¶ 如果obj是数据类型对象(
PyArray_Descr *),则计算为true。
- PyArray_Descr*
PyArray_DescrNew(PyArray_Descr* obj)¶ 返回从obj复制的新数据类型对象(字段引用刚刚更新,以便新对象指向同一字段字典,如果有)。
- PyArray_Descr*
PyArray_DescrNewFromType(int typenum)¶ 从typenum指示的内置(或用户注册的)数据类型创建一个新的数据类型对象。所有内置类型不应该更改任何字段。这将创建
PyArray_Descr结构的新副本,以便您可以根据需要填充它。对于需要具有新elsize成员的灵活数据类型,为了在数组构造中有意义,该功能尤其需要。
- PyArray_Descr*
PyArray_DescrNewByteorder(PyArray_Descr* obj, char newendian)¶ 创建一个新的数据类型对象,其字节顺序根据newendian设置。所有引用的数据类型对象(在数据类型对象的subdescr和fields成员中)也被更改(递归)。如果遇到
NPY_IGNORE的字节顺序,它将被单独保留。如果newendian为NPY_SWAP,则交换所有字节顺序。其他有效的newendian值是NPY_NATIVE,NPY_LITTLE和NPY_BIG,它们都导致返回的数据类型描述符(及其所有引用的数据类型描述符)具有相应的字节顺序。
- PyArray_Descr*
PyArray_DescrFromObject(PyObject* op, PyArray_Descr* mintype)¶ 从对象op(应为“嵌套”序列对象)和最小数据类型描述符mintype(可以为
NULL)确定适当的数据类型对象。类似于数组(op)。dtype。不要将此函数与PyArray_DescrConverter混淆。此函数基本上查看(嵌套)序列中的所有对象,并根据找到的元素确定数据类型。
- PyArray_Descr*
PyArray_DescrFromScalar(PyObject* scalar)¶ 从数组标量对象返回数据类型对象。不进行检查以确保标量是数组标量。如果不能确定合适的数据类型,则默认返回
NPY_OBJECT的数据类型。
- PyArray_Descr*
PyArray_DescrFromType(int typenum)¶ 返回与typenum对应的数据类型对象。typenum可以是枚举类型之一,枚举类型之一的字符代码或用户定义类型。
- int
PyArray_DescrConverter(PyObject* obj, PyArray_Descr** dtype)¶ 将任何兼容的Python对象obj转换为dtype中的数据类型对象。大量的Python对象可以转换为数据类型对象。有关完整的说明,请参阅Data type objects (dtype)。此版本的转换器将无对象转换为
NPY_DEFAULT_TYPE数据类型对象。此函数可与PyArg_ParseTuple处理中的“O&”字符代码一起使用。
- int
PyArray_DescrConverter2(PyObject* obj, PyArray_Descr** dtype)¶ 将任何兼容的Python对象obj转换为dtype中的数据类型对象。此版本的转换器转换无对象,以使返回的数据类型为
NULL。此函数也可以与PyArg_ParseTuple处理中的“O&”字符一起使用。
- int
Pyarray_DescrAlignConverter(PyObject* obj, PyArray_Descr** dtype)¶ 像
PyArray_DescrConverter,除了它像编译器那样在字边界上对齐C语言结构对象。
- int
Pyarray_DescrAlignConverter2(PyObject* obj, PyArray_Descr** dtype)¶ 像
PyArray_DescrConverter2除了它像字体边界上的C语言结构对象作为编译器。
- PyObject *
PyArray_FieldNames(PyObject* dict)¶ 取字段字典dict,例如附加到数据类型对象的字典字典,并构造字段名称的有序列表,例如存储在
PyArray_Descr
Conversion Utilities¶
For use with PyArg_ParseTuple¶
所有这些函数都可以在PyArg_ParseTuple(...)中使用“O&”格式说明符自动将任何Python对象转换为所需的C对象。如果成功,所有这些函数返回NPY_SUCCEED,如果不成功,返回NPY_FAIL。所有这些函数的第一个参数是一个Python对象。第二个参数是要将Python对象转换为的C类型的地址。
警告
一定要理解在使用这些转换函数时你应该采取什么步骤来管理内存。这些功能可能需要释放内存,和/或根据您的使用更改特定对象的引用计数。
- int
PyArray_Converter(PyObject* obj, PyObject** address)¶ 将任何Python对象转换为
PyArrayObject。如果PyArray_Check(obj)为TRUE,则其引用计数增加,并且引用放置在地址中。如果obj不是数组,则使用PyArray_FromAny将其转换为数组。不管返回什么,当你完成后,你必须在address中DECREF这个例程返回的对象。
- int
PyArray_OutputConverter(PyObject* obj, PyArrayObject** address)¶ 这是一个给函数的输出数组的默认转换器。如果obj为
Py_None或NULL,则* address将为NULL调用就会成功。如果PyArray_Check(obj)为TRUE,则在* address中返回,而不增加其引用计数。
- int
PyArray_IntpConverter(PyObject* obj, PyArray_Dims* seq)¶ 将小于
NPY_MAXDIMS的任何Python序列obj转换为npy_intp的C数组。Python对象也可以是单个数字。seq变量是指向具有成员ptr和len的结构的指针。成功返回后,seq - > ptr包含指向必须释放的内存的指针,以避免内存泄漏。对存储器大小的限制允许该转换器方便地用于旨在被解释为数组形状的序列。
- int
PyArray_BufferConverter(PyObject* obj, PyArray_Chunk* buf)¶ 使用(单段)缓冲区接口将任何Python对象obj转换为具有详细描述对象使用其内存块的成员的变量。buf变量是指向具有base,ptr,len和flags成员的结构的指针。
PyArray_Chunk结构与Python的缓冲区对象是二进制兼容的(通过32位平台上的len成员和64位平台上的ptr成员或Python 2.5)。返回时,基本成员设置为obj(或者如果obj已经是指向另一个对象的缓冲对象,则其基本成员)。如果你需要保持内存,一定要INCREF基本成员。内存块由buf - > ptr member指向,并且长度为buf - > len。如果obj具有可写缓冲区接口,则buf的标志成员为NPY_BEHAVED_RO,并设置NPY_ARRAY_WRITEABLE标志。
- int
PyArray_AxisConverter(PyObject * obj, int* axis)¶ 转换一个Python对象obj,将一个轴参数表示为适当的值,以传递给接受整数轴的函数。具体来说,如果obj为无,则轴设置为
NPY_MAXDIMS,它由采用轴参数的C-API函数正确解释。
- int
PyArray_SortkindConverter(PyObject* obj, NPY_SORTKIND* sort)¶ 将Python字符串转换为
NPY_QUICKSORT(以“q”或“Q”开头),NPY_HEAPSORT(以“h”或“H”开头)或NPY_MERGESORT(以“m”或“M”开头)。
- int
PyArray_SearchsideConverter(PyObject* obj, NPY_SEARCHSIDE* side)¶ 将Python字符串转换为
NPY_SEARCHLEFT(以“l”或“L”开头)或NPY_SEARCHRIGHT(以“r”或“R”开头)之一。
- int
PyArray_OrderConverter(PyObject* obj, NPY_ORDER* order)¶ Convert the Python strings ‘C’, ‘F’, ‘A’, and ‘K’ into the
NPY_ORDERenumerationNPY_CORDER,NPY_FORTRANORDER,NPY_ANYORDER, andNPY_KEEPORDER.
- int
PyArray_CastingConverter(PyObject* obj, NPY_CASTING* casting)¶ Convert the Python strings ‘no’, ‘equiv’, ‘safe’, ‘same_kind’, and ‘unsafe’ into the
NPY_CASTINGenumerationNPY_NO_CASTING,NPY_EQUIV_CASTING,NPY_SAFE_CASTING,NPY_SAME_KIND_CASTING, andNPY_UNSAFE_CASTING.
- int
PyArray_ClipmodeConverter(PyObject* object, NPY_CLIPMODE* val)¶ 将Python字符串的“clip”,“wrap”和“raise”转换为
NPY_CLIPMODE枚举NPY_CLIP,NPY_WRAP和NPY_RAISE。
- int
PyArray_ConvertClipmodeSequence(PyObject* object, NPY_CLIPMODE* modes, int n)¶ 将剪辑模式序列或单个剪辑模式转换为
NPY_CLIPMODE值的C数组。在调用此函数之前,必须知道剪辑模式的数量n。提供此函数以帮助功能允许每个维度使用不同的剪辑模式。
Other conversions¶
- int
PyArray_PyIntAsInt(PyObject* op)¶ 将各种类型的Python对象(包括数组和数组标量)转换为标准整数。出错时,返回-1并设置异常。你可能会发现有用的宏:
#define error_converting(x) (((x) == -1) && PyErr_Occurred()
- int
PyArray_IntpFromSequence(PyObject* seq, npy_intp* vals, int maxvals)¶ 将以seq传递的任何Python序列(或单个Python号)转换为(最多)maxvals个指针大小的整数,并将它们放在vals t2 >数组。当返回转换对象的数量时,该序列可以小于maxvals。
- int
PyArray_TypestrConvert(int itemsize, int gentype)¶ 将打字字符(itemize)转换为基本枚举数据类型。对应于有符号和无符号整数,浮点数和复数浮点数的typestring字符被识别和转换。返回gentype的其他值。此函数可用于将字符串'f4'转换为
NPY_FLOAT32。
Miscellaneous¶
Importing the API¶
为了使用来自另一个扩展模块的C-API,必须使用import_array()命令。如果扩展模块是自包含在一个单一的.c文件,那就是所有需要做的。然而,如果扩展模块涉及需要C-API的多个文件,则必须采取一些额外的步骤。
- void
import_array(void)¶ 此函数必须在将使用C-API的模块的初始化部分中调用。它导入存储函数指针表的模块,并将正确的变量指向它。
-
PY_ARRAY_UNIQUE_SYMBOL¶
-
NO_IMPORT_ARRAY¶ 使用这些#defines你可以在单个扩展模块的多个文件中使用C-API。在每个文件中,您必须将
PY_ARRAY_UNIQUE_SYMBOL定义为将保存C-API的某个名称(,例如 myextension_ARRAY_API)。这必须在之前完成,包括numpy / arrayobject.h文件。在模块初始化例程中,调用import_array()。此外,在没有模块初始化的文件中,sub_routine在包含numpy / arrayobject.h之前定义NO_IMPORT_ARRAY。假设我有两个文件coolmodule.c和coolhelper.c,需要编译和链接到一个单一的扩展模块。假设coolmodule.c包含所需的initcool模块初始化函数(调用import_array()函数)。然后,coolmodule.c将在顶部:
#define PY_ARRAY_UNIQUE_SYMBOL cool_ARRAY_API #include numpy/arrayobject.h
另一方面,coolhelper.c将包含在顶部:
#define NO_IMPORT_ARRAY #define PY_ARRAY_UNIQUE_SYMBOL cool_ARRAY_API #include numpy/arrayobject.h
你也可以把普通的最后两行放入一个扩展本地头文件,只要你确保NO_IMPORT_ARRAY #define之前#include该文件。
Checking the API Version¶
因为在大多数平台上,python扩展不像通常的库一样使用,所以在构建时或运行时不能自动检测到某些错误。例如,如果你使用只对numpy> = 1.3.0可用的函数构建一个扩展,并且以后用numpy 1.2导入扩展,你将不会得到一个导入错误(但是在调用该函数时几乎肯定会出现分段错误) 。这就是为什么提供几个函数来检查numpy版本。宏NPY_VERSION和NPY_FEATURE_VERSION对应于用于构建扩展的numpy版本,而函数PyArray_GetNDArrayCVersion和PyArray_GetNDArrayCFeatureVersion返回的版本对应于运行时numpy的版本。
ABI和API兼容性的规则可以总结如下:
- 每当
NPY_VERSION!= PyArray_GetNDArrayCVersion时,扩展必须重新编译(ABI不兼容)。NPY_VERSION== PyArray_GetNDArrayCVersion和NPY_FEATURE_VERSION
在每个numpy的版本中自动检测ABI不兼容性。在numpy 1.4.0中添加了API不兼容性检测。如果你想支持许多不同的numpy版本与一个扩展二进制,你必须建立你的扩展与最低的NPY_FEATURE_VERSION尽可能。
- unsigned int
PyArray_GetNDArrayCVersion(void)¶ 这只是返回值
NPY_VERSION。每当ABI级别发生向后不兼容更改时,NPY_VERSION会更改。因为它在C-API中,然而,从当前标题中定义的值比较该函数的输出提供了一种方式来测试C-API是否已经改变,因此需要重新编译使用C-API的扩展模块-API。这将在函数import_array中自动检查。
- unsigned int
PyArray_GetNDArrayCFeatureVersion(void)¶ 版本1.4.0中的新功能。
这只是返回值
NPY_FEATURE_VERSION。每当API更改(例如添加一个函数)时,NPY_FEATURE_VERSION都会更改。更改的值并不总是需要重新编译。
Internal Flexibility¶
- int
PyArray_SetNumericOps(PyObject* dict)¶ NumPy存储Python可调用对象的内部表,用于实现数组的算术运算以及某些数组计算方法。此函数允许用户使用自己的版本替换任何或所有这些Python对象。字典的键(dict)是要替换的命名函数,配对值是要使用的Python可调用对象。应注意,用于替换内部数组操作的函数本身不会回调到该内部数组操作(除非您已经设计了处理该操作的函数),否则可能导致未检查的无限递归(可能导致程序崩溃)。表示可以替换的操作的键名称是:
add, subtract, multiply, divide, remainder, power, square, reciprocal, ones_like, sqrt, negative, absolute, invert, left_shift, right_shift, bitwise_and, bitwise_xor, bitwise_or, less, less_equal, equal, not_equal, greater, greater_equal, floor_divide, true_divide, logical_or, logical_and, floor, ceil, maximum, minimum, rint.这些函数包含在这里,因为它们在数组对象的方法中至少使用一次。如果被分配的对象之一不可调用,函数返回-1(不设置Python错误)。
- PyObject*
PyArray_GetNumericOps(void)¶ 返回一个包含存储在内部算术运算表中的可调用Python对象的Python字典。此字典的键在
PyArray_SetNumericOps的说明中给出。
Memory management¶
- char*
PyDataMem_NEW(size_t nbytes)¶
-
PyDataMem_FREE(char* ptr)¶
- char*
PyDataMem_RENEW(void * ptr, size_t newbytes)¶ 宏分配,释放和重新分配内存。这些宏在内部用于创建数组。
- npy_intp*
PyDimMem_NEW(nd)¶
-
PyDimMem_FREE(npy_intp* ptr)¶
- npy_intp*
PyDimMem_RENEW(npy_intp* ptr, npy_intp newnd)¶ 宏分配,释放和重新分配维度和跨越内存。
-
PyArray_malloc(nbytes)¶
-
PyArray_free(ptr)¶
-
PyArray_realloc(ptr, nbytes)¶ 这些宏使用不同的内存分配器,具体取决于常量
NPY_USE_PYMEM。当NPY_USE_PYMEM为0时,如果NPY_USE_PYMEM为1,则使用系统malloc,然后使用Python内存分配器。
Threading support¶
这些宏仅在NPY_ALLOW_THREADS在编译扩展模块期间求值为True时才有意义。否则,这些宏等同于空格。Python为每个Python进程使用单个全局解释器锁(GIL),因此一次只能执行一个线程(即使在多CPU系统上)。当调用可能需要时间来计算(并且对于其他线程,如更新的全局变量)没有副作用的编译函数时,GIL应该被释放,以便其他Python线程可以运行,同时执行耗时的计算。这可以使用两组宏来实现。通常,如果在代码块中使用组中的一个宏,则所有这些宏必须在相同的代码块中使用。Currently, NPY_ALLOW_THREADS is defined to the python-defined WITH_THREADS constant unless the environment variable NPY_NOSMP is set in which case NPY_ALLOW_THREADS is defined to be 0.
Group 1¶
此组用于调用可能需要一些时间但不使用任何Python C-API调用的代码。因此,GIL应在其计算期间释放。
NPY_BEGIN_ALLOW_THREADS¶等效于
Py_BEGIN_ALLOW_THREADS,除非它使用NPY_ALLOW_THREADS来确定宏是否被替换为空格。
NPY_END_ALLOW_THREADS¶等同于
Py_END_ALLOW_THREADS,除非它使用NPY_ALLOW_THREADS来确定宏是否被替换为空格。
NPY_BEGIN_THREADS_DEF¶放在变量声明区。这个宏设置存储Python状态所需的变量。
NPY_BEGIN_THREADS¶放在不需要Python解释器的代码之前(没有Python C-API调用)。此宏保存Python状态并释放GIL。
NPY_END_THREADS¶放置在不需要Python解释器的代码后面。此宏获取GIL并从保存的变量恢复Python状态。
NPY_BEGIN_THREADS_DESCR(PyArray_Descr *dtype)¶只有在dtype不包含任何可能需要Python解释器的Python对象时,才有助于释放GIL。相当于
NPY_END_THREADS_DESCR(PyArray_Descr *dtype)¶用于在使用此宏的BEGIN形式释放GIL的情况下重新获得GIL。
NPY_BEGIN_THREADS_THRESHOLDED(int loop_size)¶仅在loop_size超过最小阈值(当前设置为500)时用于释放GIL。应该与.. c:macro :: NPY_END_THREADS匹配,以重新获得GIL。
Default buffers¶
-
NPY_BUFSIZE¶ 用户可设置的内部缓冲区的默认大小。
-
NPY_MIN_BUFSIZE¶ 最小尺寸的用户可设置内部缓冲区。
-
NPY_MAX_BUFSIZE¶ 用户可设置缓冲区允许的最大大小。
Other constants¶
-
NPY_NUM_FLOATTYPE¶ 浮点类型的数量
-
NPY_MAXDIMS¶ 数组中允许的最大维数。
-
NPY_VERSION¶ ndarray对象的当前版本(检查这个变量是否被定义以保证numpy / arrayobject.h头被使用)。
-
NPY_FALSE¶ 定义为0,与Bool一起使用。
-
NPY_TRUE¶ 定义为1与Bool一起使用。
-
NPY_FAIL¶ 使用
PyArg_ParseTuple类函数中的“O&”语法调用的失败转换器函数的返回值。
-
NPY_SUCCEED¶ 使用
PyArg_ParseTuple类函数中的“O&”语法调用的成功转换器函数的返回值。
Miscellaneous Macros¶
-
PyArray_SAMESHAPE(a1, a2)¶ 如果数组a1和a2具有相同的形状,则计算为True。
-
PyArray_MAX(a, b)¶ 返回a和b的最大值。如果(a)或(b)是表达式,它们将被求值两次。
-
PyArray_MIN(a, b)¶ 返回a和b的最小值。如果(a)或(b)是表达式,它们将被求值两次。
-
PyArray_CLT(a, b)¶
-
PyArray_CGT(a, b)¶
-
PyArray_CLE(a, b)¶
-
PyArray_CGE(a, b)¶
-
PyArray_CEQ(a, b)¶
-
PyArray_CNE(a, b)¶ 使用NumPy对词典顺序的定义,实现两个复数(具有实数和imag成员的结构)之间的复杂比较:首先比较实部,然后如果实部相等,则比较复数部分。
-
PyArray_XDECREF_ERR(PyObject *obj)¶ DECREF的数组对象可以设置
NPY_ARRAY_UPDATEIFCOPY标志,而不会将内容复制回原始数组。重置基础对象上的NPY_ARRAY_WRITEABLE标志。当使用NPY_ARRAY_UPDATEIFCOPY时,这对于从错误状态恢复非常有用。
Enumerated Types¶
-
NPY_SCALARKIND¶ 指示在确定标量强制规则中区分的标量的“种类”的数量的特殊变量类型。此变量可以取值
NPY_{KIND},其中{KIND}可以是NOSCALAR,BOOL_SCALAR,INTPOS_SCALAR,INTNEG_SCALAR,FLOAT_SCALAR,COMPLEX_SCALAR ,OBJECT_SCALAR-
NPY_NSCALARKINDS¶ 定义为标量类型的数量(不包括
NPY_NOSCALAR)。
-
-
NPY_ORDER¶ 枚举类型,指示数组应解释的元素顺序。创建全新数组时,通常只使用NPY_CORDER和NPY_FORTRANORDER,而在提供一个或多个输入时,顺序可以基于它们。
-
NPY_ANYORDER¶ Fortran的顺序如果所有的输入都是Fortran,否则C。
-
NPY_CORDER¶ C命令。
-
NPY_FORTRANORDER¶ Fortran顺序。
-
NPY_KEEPORDER¶ 尽可能接近输入的顺序,即使输入既不是C也不是Fortran顺序。
-
-
NPY_CLIPMODE¶ 指示应在某些功能中应用的剪辑类型的变量类型。
NPY_RAISE大多数操作的默认值,如果索引超出边界则引发异常。
NPY_CLIP如果索引超出范围,则将其限制为有效范围。
NPY_WRAP如果索引超出范围,则将索引包装到有效范围。
-
NPY_CASTING¶ 版本1.6中的新功能。
一种枚举类型,指示应该如何进行许可数据转换。这是由NumPy 1.6中添加的迭代器使用的,并且旨在在未来版本中更广泛地使用。
-
NPY_NO_CASTING¶ 只允许相同类型。
-
NPY_EQUIV_CASTING¶ 允许相同的转换,涉及字节交换。
-
NPY_SAFE_CASTING¶ 仅允许不会导致值被舍入,截断或以其他方式更改的转换。
-
NPY_SAME_KIND_CASTING¶ 允许任何安全投射,并在同种类型之间投射。例如,此规则允许使用float64 - > float32。
-
NPY_UNSAFE_CASTING¶ 允许任何投放,无论可能发生什么类型的数据丢失。
-