pyspider 

 ¶
¶
A Powerful Spider(Web Crawler) System in Python. TRY IT NOW!
- Write script in Python
- Powerful WebUI with script editor, task monitor, project manager and result viewer
- MySQL, MongoDB, Redis, SQLite, Elasticsearch; PostgreSQL with SQLAlchemy as database backend
- RabbitMQ, Beanstalk, Redis and Kombu as message queue
- Task priority, retry, periodical, recrawl by age, etc...
- Distributed architecture, Crawl Javascript pages, Python 2&3, etc...
Tutorial: http://docs.pyspider.org/en/latest/tutorial/
Documentation: http://docs.pyspider.org/
Release notes: https://github.com/binux/pyspider/releases
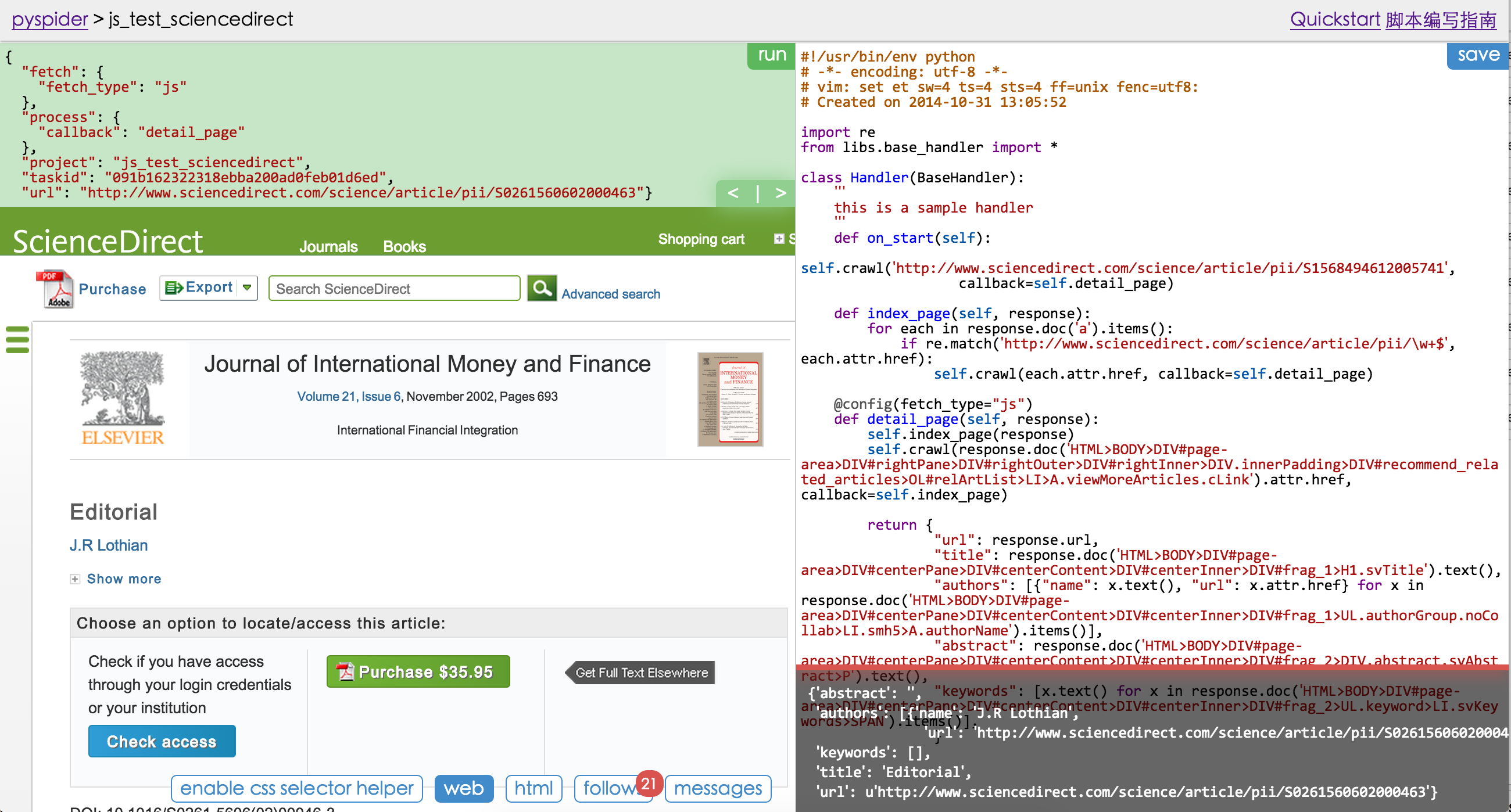
Sample Code¶
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
Installation¶
pip install pyspider- run command
pyspider, visit http://localhost:5000/
Quickstart: http://docs.pyspider.org/en/latest/Quickstart/
Contribute¶
- Use It
- Open Issue, send PR
- User Group
- 中文问答
TODO¶
v0.4.0¶
- [x] local mode, load script from file.
- [x] works as a framework (all components running in one process, no threads)
- [x] redis
- [x] shell mode like
scrapy shell - [ ] a visual scraping interface like portia
more¶
- [x] edit script with vim via WebDAV
License¶
Licensed under the Apache License, Version 2.0