Transactional Topologies
请注意: Transactional topologies 已经摒弃 -- 使用 Trident 框架替代。
Storm guarantees data processing (保证数据处理)至少一次。关于 Storm 问的最多的问题就是 "当 tuples 重发时,你会如何做呢?你会重复计算吗?"
Storm 0.7.0 版本介绍了 transactional topologies.使得你可以在复杂的计算中做到 exactly once 的消息语义.所以你可以以一种完全精准的,可伸缩,容错的方式执行程序。
和 Distributed RPC一样,transactional topologies 并不是Storm的一种功能,而是基于 Storm 原语(streams,spouts,bolts,topologies)构建的高级抽象。
这一页用来解释 transactional topology 抽象,如何使用API,并提供API实现的细节。
Concepts
我们一起来构建 transactional topologies (事务性拓扑)的第一步.我们先从简单的方法开始,不断的完善达到我们想要的设计。
Design 1
transactional topologies (事务性拓扑) 背后核心的思想就是对数据的处理提供严格的顺序性.严格的顺序性就是说,在处理tuples的时候,topology(拓扑)将当前 tuple 成功处理完后才可以进行下一个 tuple 处理。
每个tuple 都和一个 transaction id 关联.当 tuple 失败需要重新处理的时候,tuple 会绑定相同的 transaction id 重新发送.tuple 的transaction id 是自增长的,所以第一个 tuple 的 transaction id 是1,第二个就是2,以此类推.
tuples的严格顺序性使得你在 tuple 重新处理的时候可以保证 exactly-once语义.我们来看一个例子。
假设你想要计算 stream中 tuples的总数.原来你可能只会将 count 总数存储在数据库中,但是你现在将 count 总数和最新的 transaction id 存储在数据库中。在程序更新 db 中的count的时候,只有_当数据库中的transaction id和当前处理的 tuple 的transaction id 不同的时候_,才会更新 count 总数.考虑下面两种场景:
- 数据库中的 transaction id 和当前 transaction id 不同: 因为 transactions(事务)的严格顺序性,我们可以确定当前的 tuple 并不代表 count 总数。所以我们安全的自增 count,并更新 transaction id。
- 数据库中的 transaction id 和当前 transaction id 相同: 那么我们知道这个 tuple 已经被并入计数,可以跳过更新.这个 tuple 一定在第一次更新数据库之后失败过,在第二次处理成功后汇报之前.
这种合理的和强一致性的事务保证了如果tuple失败了重新处理,保存在数据库中的count也是准确的. 将 transaction id 存储到数据库和将 value 发送到kafka 设计是一样的,可以看 this design document.
另外,topology 可以在相同的事务中的更新许多状态源,并保证 exactly-once 语义.如果有失败,成功更新的会跳过重试,失败更新的会进行重试. 例如,你要处理 tweeted urls 的stream,你可以存储每一个 url 的 tweet 数量,也可以存储每一个 domain(域名)的 tweet 数量.
上面这种设计对在某一时刻处理一个 tuple 有一个比较严重的问题。必须等待每个 tuple 处理完成后,才可以进行下一个处理,这是非常低效的.这种设计需要大量的数据库调用(至少每个 tuple 一次),这个设计很少用到并行,所以它不是可扩展的.
Design 2
相对于一次只能处理一个 tuple,更好的方式就是在每个 transaction(事务)中批处理 tuples.所以如果你要做一个全局的计数,每次增加的是整个 batch 的数量.如果 batch 失败了,你需要重新处理这个失败的 batch . 相比于之前你要对每一个 tuple 分配一个 transaction id,现在是对每个 batch 分配一个 transaction id。并且处理 batch 也是严格有序的.下面是这个设计的图表:
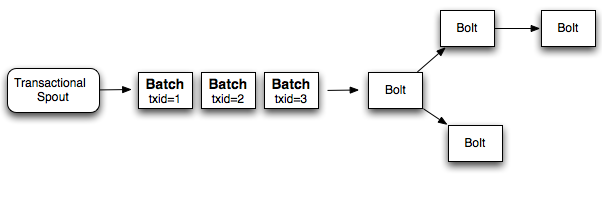
所以如果你每一个 batch 处理 1000 个 tuples,相比于 design 1(设计1)你会少做 1000x 数量级的 数据库操作.另外,这种设计利用了 Storm 的并行计算特性,每一个batch都可以并行计算.
虽然这种设计优于 design 1(设计1),但是它仍然不能有效的利用资源.topology中的workers会花费大量的时间等待其他部分的计算完成。例如,一个 topology(拓扑)像下面这样:

当 bolt 1 完成部分处理后,它所在的 worker 将是空闲的,直到剩余的 bolt 完成后,下一个 batch 才会从spout发送出来.
Design 3 (Storm's design)
一个关键的实现就是并不是所有处理 batch 的工作都要严格有序。例如,当计算一个全局计数,需要计算两部分:
- 计算每一个 batch 的局部 count
- 通过局部 count 更新数据库里的全局 count
第二部分在计算 batch 过程中需要严格有序,但是没有理由不并行计算第一部分。所以当 batch 1 正在更新数据库时,batch 2到10 可以计算他们的局部 count.
Storm 不同之处在于将 batch 计算分成两部分来完成:
- 处理阶段:这个阶段是可以并行处理 batches 的。
- 提交阶段:提交阶段,batches是严格有序的.所以 batch 2必须等到 batch 1提交成功后才可以进行提交.
这两个阶段合起来称之为 “transaction”(事务)。许多 batch 在某一时间内处于处理阶段,但只有一个 batch 处于提交阶段。如果处理阶段或者提交失败有失败的话,将重新处理 batch(两个阶段都会重新处理).
Design details
当使用 transactional topologies ,Storm 为你提供以下信息:
- Manages state: Storm 执行 transactional topologies 的时候,将所有的状态存储到 zookeeper.其中包括当前的 transaction id,也包括定义每个 batch 参数的 metadata信息.
- Coordinates the transactions: Storm会管理一切必要的事情,来确定 transaction 什么时候处理或者提交.
- Fault detection: Storm利用acking框架来有效地确定批处理成功处理,成功提交或失败的时间。Storm 然后会适当地重新处理 batch 。你不必做任何暗示或anchoring - Strom管理所有这一切。
- First class batch processing API: Storm 在常规螺栓之上层叠一个API,以允许批量处理 tuples。 Storm管理所有协调,以确定任务何时已经接收到该特定事务的所有 tuples。Storm 也将照顾清理每笔交易的任何累计状态(如部分计数)。
最后需要注意的是, transactional topologies(事务拓扑)需要一个可以重播一批精确信息的 source queue.像 Kestrel 是无法做到的. Apache Kafka 非常适合当这个 spout, , 而且 storm-kafka 包含一个用于 Kafka 的事务性 spout 实现.
The basics through example
你通过使用 TransactionalTopologyBuilder 构建 transactional topologies .下面是一个 topology(拓扑)的 transactional topology 定义,用来计算输入 tuples 的总数. 代码来自于 storm-starter 的TransactionalGlobalCount .
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"), PARTITION_TAKE_PER_BATCH);
TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, 3);
builder.setBolt("partial-count", new BatchCount(), 5)
.shuffleGrouping("spout");
builder.setBolt("sum", new UpdateGlobalCount())
.globalGrouping("partial-count");
TransactionalTopologyBuilder 将构造函数的输入作为 transactional topology 的id,还有 topology 内的 spout id,一个事务性的 spout,还有事务性 spout 的并行度.transactional topology 的id 是用来在Zookeeper中存储 topology 的处理状态用的,以便如果重新启动 topology后,将从停止的地方继续运行.
transactional topology 有一个 TransactionalSpout,TransactionalSpout在TransactionalTopologyBuilder 构造器中定义.在这个例子中,MemoryTransactionalSpout 用于从内存中分区的数据源(DATA变量)中读取数据。第二个参数定义数据的字段,第三个参数指定了每批 tuples 发出的 tuple最大数量.用于定义自己的 transactional spouts 将在本教程后面讨论。
然后就是 bolts,这个 topology(拓扑)并行计划全局 count.第一个 Bolt BatchCount 使用 shuffle grouping 随机分割 input stream。第二个 Bolt UpdateGlobalCount 使用 global grouping,并将局部 count相加来获取 batch count. 如果有需要,它会更新数据库中的全局 count.
下面是 BatchCount 的定义:
public static class BatchCount extends BaseBatchBolt {
Object _id;
BatchOutputCollector _collector;
int _count = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_count++;
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "count"));
}
}
BatchCount 在每一个 bacth 被处理的时候,都会实例化.真正运行 bolt 的是 BatchBoltExecutor ,用来管理这些对象的创建和清理.
prepare 方法使用 Storm config,topology上下文,output collector,这个批次 tuples的id来进行参数设置。在transactional topologies(事务拓扑)中,id将是一个 TransactionAttempt 对象。这个 batch bolt 的后巷可以在 distributed rpc 中使用,也可以使用不同类型的id. BatchBolt 也可以使用 id 的类型配置参数,因此如果你打算在 transactional topologies(事务拓扑)中使用 batch bolt,你可以继承BaseTransactionalBolt:
public abstract class BaseTransactionalBolt extends BaseBatchBolt<TransactionAttempt> {
}
所有在transactional topology(事务拓扑)中发送的 tuples 必须让 TransactionAttempt 作为第一个字段,这可以让Storm 知道 tuple属于哪个 batch.所以当你发送 tuple的时候,必须保证这个要求.
TransactionAttempt 包含两个值:"transaction id"和 "attempt id". "transaction id" 是batch的唯一性标识,同一个batch无论重复多少次处理,都不会改变. "attempt id" 是 batch中 tuple的唯一标识,Storm用来区分相同 batch中不同的tuples。 没有 attempt id, Storm 可能会从 bacth发送之前开始重新处理。这是很可怕的.
每个 batch 发送的时候,transaction id 都加1.所以,第一个 batch 的id是1,第二个就是2,以此类推.
batch中的每个 tuple都会调用 execute 方法. 在每次调用这个方法的时候,你应该在本地实例变量中累计 batch 的状态. BatchCount bolt 通过本地 counter 对每个 tuple 自增.
最后,当任务接受到指定的 batch 的所有tuples时,会调用 finishBatch 方法.当调用此方法时,BatchCount 会向 output stream 发出局部的count.
下面是 UpdateGlobalCount 的定义:
public static class UpdateGlobalCount extends BaseTransactionalBolt implements ICommitter {
TransactionAttempt _attempt;
BatchOutputCollector _collector;
int _sum = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt attempt) {
_collector = collector;
_attempt = attempt;
}
@Override
public void execute(Tuple tuple) {
_sum+=tuple.getInteger(1);
}
@Override
public void finishBatch() {
Value val = DATABASE.get(GLOBAL_COUNT_KEY);
Value newval;
if(val == null || !val.txid.equals(_attempt.getTransactionId())) {
newval = new Value();
newval.txid = _attempt.getTransactionId();
if(val==null) {
newval.count = _sum;
} else {
newval.count = _sum + val.count;
}
DATABASE.put(GLOBAL_COUNT_KEY, newval);
} else {
newval = val;
}
_collector.emit(new Values(_attempt, newval.count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "sum"));
}
}
UpdateGlobalCount 对于 transactional topologies 是特殊的,所以它继承BaseTransactionalBolt 类.在 execute 方法中,UpdateGlobalCount 通过将局部 batch累加在一起得到此 batch 的count.有趣的事情发生在 finishBatch 方法中.
首先,你会看到这个 Bolt 实现了 ICommitter 接口.这就告诉Storm finishBatch 方法是事务提交阶段的一部分.所以调用 finishBatch 将会按照 transaction id 严格有序(另一方面,execute的调用可能发生在处理阶段或者提交阶段)。将 Bolt 标记为 committer的另外一种方式就是 在 TransactionalTopologyBuilder 中使用setCommitterBolt 方法,而不是 setBolt。
UpdateGlobalCount 中的 finishBatch 的代码从数据库获取当前值,并将 transaction id 与此批次的 transaction id 进行比较。如果他们是一样的,它什么都不做。否则,数据库中的值就增加此batch 的局部 count。
在 TransactionalWords 类中的storm-start中可以找到更多涉及到更新多个数据库的transactional topology示例.
Transactional Topology API
本节概述了事务拓扑API的不同部分。
Bolts
transactional topology(事务拓扑)中有三种 Bolt:
- BasicBolt: 这个 Bolt 不处理 batches of tuples,只基于单个tuple输入发送tuples.
- BatchBolt: 这个 Bolt 处理 batches of tuples,对于每个 tuple 调用
execute,并在处理完 batch后调用finishBatch方法。 - BatchBolt's that are marked as committers: 这个 Bolt 和常规的
Batch Bolt之间的唯一区别是调用finishBatch时。Committer bolt 已经在提交阶段调用finishBatch方法。提交阶段只有在所有先前 batch 成功提交之后才能保证发生,并且将重新尝试,直到 topology(拓扑)结构中的所有 Bolt 成功完成批处理的提交。有两种方式使 BatchBolt成为 committer,通过使BatchBolt实现 ICommitter 标记接口,或者通过在TransactionalTopologyBuilder中使用setCommiterBolt方法.
Processing phase vs. commit phase in bolts
为了确定 transaction(事务)的处理阶段和提交阶段之间的差异,我们来看一个示例 topology(拓扑):
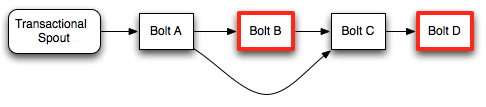
在这种 topology(拓扑)中,只有具有红色轮廓的 Bolts 才是 committers。
在处理阶段,Bolt A将从 Spout 处理完整的 batch ,调用 finishBatch 并将 tuples 发送到 Bolt B和C.Bolt B是一个 committer,因此它将处理所有的 tuple,但是不会调用 finishBatch。 Bolt C也不会有finishBatch 调用,因为它不知道它是否已经收到Bolt B的所有tuple(因为Bolt B正在等待事务提交)。最后,Bolt D将在其 execute 方法的调用期间接收 Bolt C 的tuple.
当 batch 提交时,将在Bolt B上调用 finishBatch 。一旦完成,Bolt C现在可以检测到它已经接收到所有的 tuple,并将调用 finishBatch。最后,Bolt D将收到完整的 batch 并调用 finishBatch。
请注意,即使Bolt D是 committer,它在收到整个 batch 时也不必等待第二个提交消息。由于它在提交阶段收到整个batch ,所以它将继续并完成 transaction(事务)事务。
Committer bolts 在提交阶段就像 batch bolts 那样运行。committer bolts 和 batch bolts之间的唯一区别是committer bolts在 transaction(拓扑)的处理阶段不会调用 finishBatch。
Acking
请注意,在使用transactional topologies(事务拓扑)时,您不必执行任何操作或 anchoring。Storm管理下面的所有这些。acking 策略被大量优化。
Failing a transaction
当使用常规 bolts 时,可以在 OutputCollector 上调用 fail 方法来使该 tuple 的成员的 tuples tree失败。由于transactional topologies(事务拓扑) 隐藏了您的acking框架,因此它们提供了一种不同的机制来使 batch 失败(并导致 batch 被重播)。只是抛出一个 FailedException. 与常规异常不同,这只会导致特定 batch 重播,并且不会使进程崩溃。
Transactional spout
TransactionalSpout 接口与普通Spout接口完全不同。 TransactionalSpout 实现发送批量的 tuples,并且必须确保为相同的事务ID始终发出同一批 tuples。
topology(拓扑)拓扑正在执行时,transactional spout 看起来像这样:
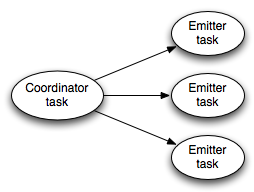
左边的 coordinator(协调器) 是一个常规的Storm spout,每当一个批处理被发送到一个事务中时,它会发出一个 tuple。emitters(发射器)作为常规Storm bolt 执行,并负责发射 batch 的实际 tuples。emitters(发射器)使用 all grouping 订阅 coordinator(协调器)的“batch emit” stream。
对于它发出的 tuple,需要是等幂的,需要一个 TransactionalSpout 来存储少量的状态。状态存储在Zookeeper中。
实现 TransactionalSpout 的细节在 the Javadoc 中.
Partitioned Transactional Spout
一种常见的事务性出水口是从许多队列经纪人的一组分区中读取批次的。例如,这是 TransactionalKafkaSpout 的工作原理。 IPartitionedTransactionalSpout会自动执行管理每个分区的状态的记账工作,以确保幂等重播。有关详细信息。 请参阅 the Javadoc
Configuration
transactional topologies(事务性拓扑)有两个重要的配置位:
- Zookeeper: 默认情况下,transactional topologies(事务拓扑)将在用于管理Storm集群的Zookeeper实例中存储状态。您可以使用“transactional.zookeeper.servers”和“transactional.zookeeper.port”配置覆盖此配置。
- Number of active batches permissible at once: 您必须对可以一次处理的 batches 数设置限制。您可以使用“topology.max.spout.pending”配置进行配置。如果您没有设置此配置,它将默认为1。
What if you can't emit the same batch of tuples for a given transaction id?
到目前为止,关于 transactional topologies(事务拓扑)的讨论假设您可以随时为相同的事务ID发出完全相同批次 tuple 。那么如果不可能,你该怎么办?
考虑一下这个不可能的例子。假设您正在从分区消息代理读取 tuple (流在许多机器上分区),单个事务将包含所有单个机器的 tuple 。现在假设其中一个节点在事务失败的同时下降。没有那个节点,就不可能重播刚刚为该事务ID播放的同一批 tuples。您的 topology(拓扑)拓扑中的处理将停止,因为它无法重播相同的批处理。唯一可能的解决方案是为该事务ID发出不同于之前发出的不同批处理。即使 batch 更改,仍然可以实现一次消息传递语义?
事实证明,您仍然可以使用非幂等的事务性端口在处理过程中实现完全一致的消息传递语义,尽管这在开发 topology(拓扑)中需要更多的工作。
如果 batch 可以更改给定的事务ID,那么我们迄今为止使用的逻辑“如果数据库中的事务ID与当前事务的id相同,则跳过更新”不再有效。这是因为当前批次与上次 transaction 提交的 batch 不同,因此结果不一定相同。您可以通过在数据库中存储更多的状态来解决此问题。我们再次使用在数据库中存储全局计数的示例,并假设批次的部分计数存储在partialCount变量中。
而不是在数据库中存储一个如下所示的值:
class Value {
Object count;
BigInteger txid;
}
对于非幂等事务端口,您应该存储一个如下所示的值:
class Value {
Object count;
BigInteger txid;
Object prevCount;
}
更新的逻辑如下:
- 如果当前 batch 的 transaction id 与数据库中的 transaction id 相同,请设置
val.count = val.prevCount + partialCount。 - 否则,设置
val.prevCount = val.count,val.count = val.count + partialCount和val.txid = batchTxid。
这个逻辑是有效的,因为一旦你第一次提交一个特定的事务id,所有的事务id都不会再被提交。
transactional topologies (事务拓扑)有一些更细微的方面,使不透明的transactional spouts 口成为可能.
当 transaction 失败时,处理阶段中的所有后续 transaction 也被认为是失败的。这些 transactions 将被重新排放和再处理。没有这种行为,可能会发生以下情况:
- Transaction A emits tuples 1-50
- Transaction B emits tuples 51-100
- Transaction A fails
- Transaction A emits tuples 1-40
- Transaction A commits
- Transaction B commits
- Transaction C emits tuples 101-150
在这种情况下,跳过 tuple 41-50。由于所有后续 transactions 失败,将会发生:
- Transaction A emits tuples 1-50
- Transaction B emits tuples 51-100
- Transaction A fails (and causes Transaction B to fail)
- Transaction A emits tuples 1-40
- Transaction B emits tuples 41-90
- Transaction A commits
- Transaction B commits
- Transaction C emits tuples 91-140
通过失败所有后续 transactions 失败,不会跳过 tuples。这也表明 transactions spout的要求是它们总是发出最后一个 transactions 处理的位置.
一个非幂等的 transactional spout 更简明地称为“不透明的投资点”(不透明与幂幂相反)。 IOpaquePartitionedTransactionalSpout 是一个用于实现不透明分区transactional spouts的接口,其中 OpaqueTransactionalKafkaSpout 是一个示例。只要您使用本节所述的更新策略,OpaqueTransactionalKafkaSpout可以承受丢失的单个Kafka节点,而不会牺牲精度。
Implementation
transactional topologies(事务拓扑)的实现非常优雅。管理提交协议,检测故障和流水线批处理似乎很复杂,但一切事情都是对Storm 原语的简单映射.
数据流程如何工作:
transactional spout 是如何工作的
- Transactional spout is a subtopology consisting of a coordinator spout and an emitter bolt
- The coordinator is a regular spout with a parallelism of 1
- The emitter is a bolt with a parallelism of P, connected to the coordinator's "batch" stream using an all grouping
- When the coordinator determines it's time to enter the processing phase for a transaction, it emits a tuple containing the TransactionAttempt and the metadata for that transaction to the "batch" stream
- Because of the all grouping, every single emitter task receives the notification that it's time to emit its portion of the tuples for that transaction attempt
- Storm automatically manages the anchoring/acking necessary throughout the whole topology to determine when a transaction has completed the processing phase. The key here is that *the root tuple was created by the coordinator, so the coordinator will receive an "ack" if the processing phase succeeds, and a "fail" if it doesn't succeed for any reason (failure or timeout).
- If the processing phase succeeds, and all prior transactions have successfully committed, the coordinator emits a tuple containing the TransactionAttempt to the "commit" stream.
- All committing bolts subscribe to the commit stream using an all grouping, so that they will all receive a notification when the commit happens.
- Like the processing phase, the coordinator uses the acking framework to determine whether the commit phase succeeded or not. If it receives an "ack", it marks that transaction as complete in zookeeper.
更多概念:
- Transactional spouts are a sub-topology consisting of a spout and a bolt
- the spout is the coordinator and contains a single task
- the bolt is the emitter
- the bolt subscribes to the coordinator with an all grouping
- serialization of metadata is handled by kryo. kryo is initialized ONLY with the registrations defined in the component configuration for the transactionalspout
- the coordinator uses the acking framework to determine when a batch has been successfully processed, and then to determine when a batch has been successfully committed.
- state is stored in zookeeper using RotatingTransactionalState
- commiting bolts subscribe to the coordinators commit stream using an all grouping
- CoordinatedBolt is used to detect when a bolt has received all the tuples for a particular batch.
- this is the same abstraction that is used in DRPC
- for commiting bolts, it waits to receive a tuple from the coordinator's commit stream before calling finishbatch
- so it can't call finishbatch until it's received all tuples from all subscribed components AND its received the commit stream tuple (for committers). this ensures that it can't prematurely call finishBatch