5. 数据集加载工具
该 sklearn.datasets 包装在 Getting Started 部分中嵌入了介绍一些小型玩具的数据集。
为了在控制数据的统计特性(通常是特征的 correlation (相关性)和 informativeness (信息性))的同时评估数据集 (n_samples 和 n_features) 的规模的影响,也可以生成综合数据。
这个软件包还具有帮助用户获取更大的数据集的功能,这些数据集通常由机器学习社区使用,用于对来自 ‘real world’ 的数据进行检测算法。
5.1. 通用数据集 API
对于不同类型的数据集,有三种不同类型的数据集接口。最简单的是样品图像的界面,下面在 样本图片 部分中进行了描述。
数据集生成函数和 svmlight 加载器分享了一个较为简化的接口,返回一个由 n_samples * n_features 组成的 tuple (X, y) 其中的 X 是 numpy 数组 y 是包含目标值的长度为 n_samples 的数组
玩具数据集以及 ‘real world’ 数据集和从 mldata.org 获取的数据集具有更复杂的结构。这些函数返回一个类似于字典的对象包含至少两项:一个具有 data 键(key)的 n_samples * n_features 形状的数组(除了20个新组之外except for 20newsgroups)和一个具有 target 键(key)的包含 target values (目标值)的 n_samples 长度的 numpy 数组。
数据集还包含一些对DESCR 描述,同时一部分也包含 feature_names 和 [](#id2)target_names的特征。有关详细信息,请参阅下面的数据集说明
5.2. 玩具数据集
scikit-learn 内置有一些小型标准数据集,不需要从某个外部网站下载任何文件。
| load_boston([return_X_y]) | Load and return the boston house-prices dataset (regression). |
| load_iris([return_X_y]) | Load and return the iris dataset (classification). |
| load_diabetes([return_X_y]) | Load and return the diabetes dataset (regression). |
| load_digits([n_class, return_X_y]) | Load and return the digits dataset (classification). |
| load_linnerud([return_X_y]) | Load and return the linnerud dataset (multivariate regression). |
| load_wine([return_X_y]) | Load and return the wine dataset (classification). |
| load_breast_cancer([return_X_y]) | Load and return the breast cancer wisconsin dataset (classification). |
这些数据集有助于快速说明在 scikit 中实现的各种算法的行为。然而,它们数据规模往往太小,无法代表真实世界的机器学习任务。
5.3. 样本图片
scikit 在通过图片的作者共同授权下嵌入了几个样本 JPEG 图片。这些图像为了方便用户对 test algorithms (测试算法)和 pipeline on 2D data (二维数据管道)进行测试。
| load_sample_images() | Load sample images for image manipulation. |
| load_sample_image(image_name) | Load the numpy array of a single sample image |

默认编码的图像是基于 uint8 dtype 到空闲内存。通常,如果把输入转换为浮点数表示,机器学习算法的效果最好。另外,如果你计划使用 matplotlib.pyplpt.imshow 别忘了尺度范围 0 - 1,如下面的示例所做的。
示例:
5.4. 样本生成器
此外,scikit-learn 包括各种随机样本的生成器,可以用来建立可控制的大小和复杂性人工数据集。
5.4.1. 分类和聚类生成器
这些生成器将产生一个相应特征的离散矩阵。
5.4.1.1. 单标签
make_blobs 和 make_classification 通过分配每个类的一个或多个正态分布的点的群集创建的多类数据集。 make_blobs 对于中心和各簇的标准偏差提供了更好的控制,可用于演示聚类。 make_classification 专门通过引入相关的,冗余的和未知的噪音特征;将高斯集群的每类复杂化;在特征空间上进行线性变换。
make_gaussian_quantiles 将single Gaussian cluster (单高斯簇)分成近乎相等大小的同心超球面分离。 make_hastie_10_2 产生类似的二进制、10维问题。
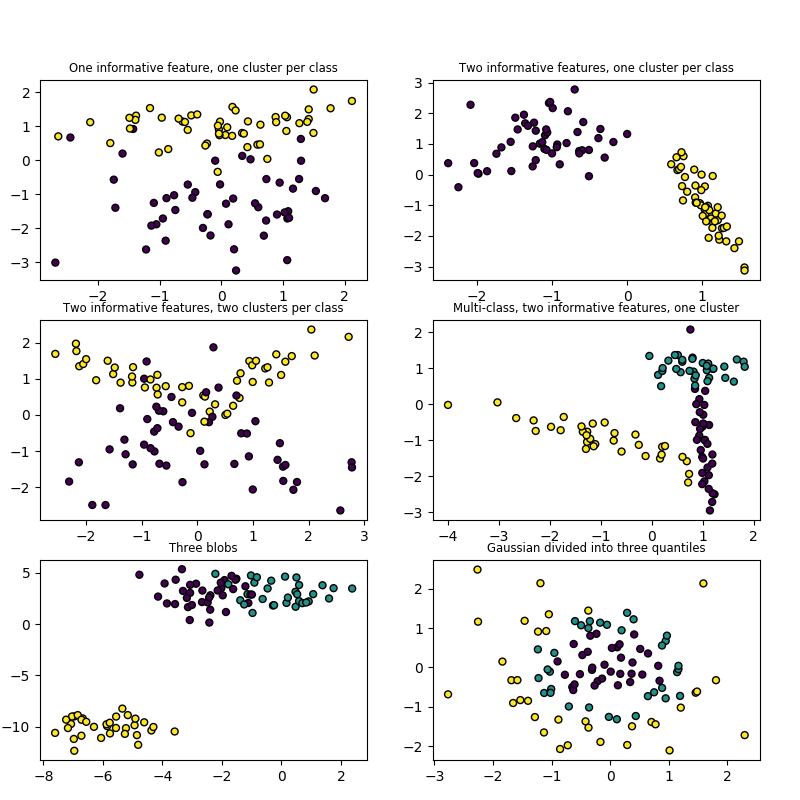
make_circles and :func:[](#id9)make_moons生成二维分类数据集时可以帮助确定算法(如质心聚类或线性分类),包括可以选择性加入高斯噪声。它们有利于可视化。用球面决策边界对高斯数据生成二值分类。
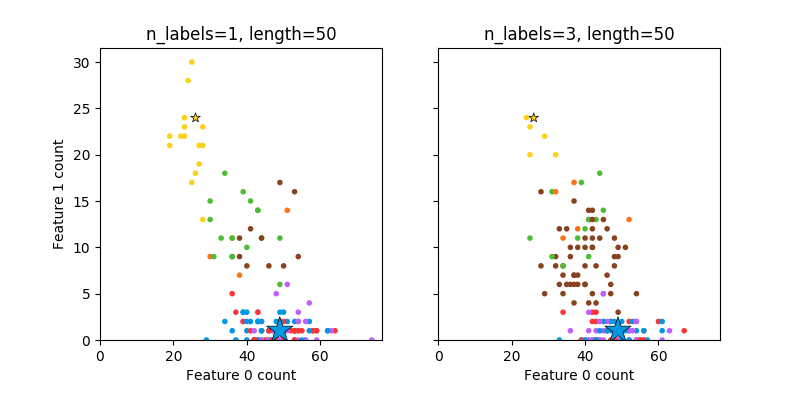
5.4.1.2. 多标签
make_multilabel_classification 生成多个标签的随机样本,反映从a mixture of topics(一个混合的主题)中引用a bag of words (一个词袋)。每个文档的主题数是基于泊松分布随机提取的,同时主题本身也是从固定的随机分布中提取的。同样地,单词的数目是基于泊松分布提取的,单词通过多项式被抽取,其中每个主题定义了单词的概率分布。在以下方面真正简化了 bag-of-words mixtures (单词混合包):
- 独立绘制的每个主题词分布,在现实中,所有这些都会受到稀疏基分布的影响,并将相互关联。
- 对于从文档中生成多个主题,所有主题在生成单词包时都是同等权重的。
- 随机产生没有标签的文件,而不是基于分布(base distribution)来产生文档
5.4.1.3. 二分聚类
| make_biclusters(shape, n_clusters[, noise, …]) | Generate an array with constant block diagonal structure for biclustering. |
| make_checkerboard(shape, n_clusters[, …]) | Generate an array with block checkerboard structure for biclustering. |
5.4.2. 回归生成器
make_regression 产生的回归目标作为一个可选择的稀疏线性组合的具有噪声的随机的特征。它的信息特征可能是不相关的或低秩(少数特征占大多数的方差)。
其他回归生成器产生确定性的随机特征函数。 make_sparse_uncorrelated 产生目标为一个有四个固定系数的线性组合。其他编码明确的非线性关系:make_friedman1 与多项式和正弦相关变换相联系; make_friedman2 包括特征相乘与交互; make_friedman3 类似与对目标的反正切变换。
5.4.3. 流形学习生成器
| make_s_curve([n_samples, noise, random_state]) | Generate an S curve dataset. |
| make_swiss_roll([n_samples, noise, random_state]) | Generate a swiss roll dataset. |
5.4.4. 生成器分解
| make_low_rank_matrix([n_samples, …]) | Generate a mostly low rank matrix with bell-shaped singular values |
| make_sparse_coded_signal(n_samples, …[, …]) | Generate a signal as a sparse combination of dictionary elements. |
| make_spd_matrix(n_dim[, random_state]) | Generate a random symmetric, positive-definite matrix. |
| make_sparse_spd_matrix([dim, alpha, …]) | Generate a sparse symmetric definite positive matrix. |
5.5. Datasets in svmlight / libsvm format
scikit-learn 中有加载svmlight / libsvm格式的数据集的功能函数。此种格式中,每行 采用如 <label> <feature-id>:<feature-value><feature-id>:<feature-value> ... 的形式。这种格式尤其适合稀疏数据集,在该模块中,数据集 X 使用的是scipy稀疏CSR矩阵, 特征集 y 使用的是numpy数组。
你可以通过如下步骤加载数据集:
>>> from sklearn.datasets import load_svmlight_file
>>> X_train, y_train = load_svmlight_file("/path/to/train_dataset.txt")
...
你也可以一次加载两个或多个的数据集:
>>> X_train, y_train, X_test, y_test = load_svmlight_files(
... ("/path/to/train_dataset.txt", "/path/to/test_dataset.txt"))
...
这种情况下,保证了 X_train 和 X_test 具有相同的特征数量。 固定特征的数量也可以得到同样的结果:
>>> X_test, y_test = load_svmlight_file(
... "/path/to/test_dataset.txt", n_features=X_train.shape[1])
...
相关链接:
svmlight / libsvm 格式的公共数据集: https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets
更快的API兼容的实现: https://github.com/mblondel/svmlight-loader
5.6. 从外部数据集加载
scikit-learn使用任何存储为numpy数组或者scipy稀疏数组的数值数据。 其他可以转化成数值数组的类型也可以接受,如pandas中的DataFrame。
以下推荐一些将标准纵列形式的数据转换为scikit-learn可以使用的格式的方法:
- pandas.io 提供了从常见格式(包括CSV,Excel,JSON,SQL等)中读取数据的工具.DateFrame 也可以从由 元组或者字典组成的列表构建而成.Pandas能顺利的处理异构的数据,并且提供了处理和转换 成方便scikit-learn使用的数值数据的工具。
- scipy.io 专门处理科学计算领域经常使用的二进制格式,例如.mat和.arff格式的内容。
- numpy/routines.io 将纵列形式的数据标准的加载为numpy数组
- scikit-learn的 :func:[
](#id18)datasets.load_svmlight_file处理svmlight或者libSVM稀疏矩阵 - scikit-learn的
datasets.load_files处理文本文件组成的目录,每个目录名是每个 类别的名称,每个目录内的每个文件对应该类别的一个样本
对于一些杂项数据,例如图像,视屏,音频。您可以参考:
- skimage.io 或 Imageio 将图像或者视屏加载为numpy数组
- scipy.misc.imread (requires the Pillow package)将各种图像文件格式加载为 像素灰度数据
- scipy.io.wavfile.read 将WAV文件读入一个numpy数组
存储为字符串的无序(或者名字)特征(在pandas的DataFrame中很常见)需要转换为整数,当整数类别变量 被编码成独热变量(sklearn.preprocessing.OneHotEncoder)或类似数据时,它或许可以被最好的利用。 参见 预处理数据.
注意:如果你要管理你的数值数据,建议使用优化后的文件格式来减少数据加载时间,例如HDF5。像 H5Py, PyTables和pandas等的各种库提供了一个Python接口,来读写该格式的数据。
5.7. Olivetti 脸部数据集
该数据集包含 1992年4月至1994年4月在AT&T实验室剑桥采集的一组面部图像。 该 sklearn.datasets.fetch_olivetti_faces 函数是从AT&T下载 数据存档的数据获取/缓存函数。
如原网站所述:
有四十个不同的个体,每个个体有十张不同的图片。对于某些个体,图像在不同时间拍摄并且改变 照明和面部表情(睁开/闭上眼睛, 微小/不微笑)和面部细节(戴眼镜/不带眼镜)。所有的图像采用 黑色均匀的背景,个体处于直立的正面位置。(容许一定的侧移)
图像被量化为256个的灰度级并以8位无符号整数的形式存储;加载器将这些无符号整数转换为[0,1]之间 的浮点值,这样能方面很多算法的使用。
该数据库的”目标”一个是从0到39的整数,代表着图中人物的身份。然而,由于每一类只有十个样例,从 无监督学习或半监督学习的角度来看,这个相对较小的数据集更加有趣。
原始的数据集由92 x 112大小的图像组成,然而这里提供的版本由64 x 64大小的图像组成。
当使用这些图像时, 请致谢AT&T剑桥实验室。
5.8. 20个新闻组文本数据集
20个新闻组文本数据集包含有关20个主题的大约18000个新闻组,被分为两个子集:一个用于 训练(或者开发),另一个用于测试(或者用于性能评估)。训练和测试集的划分是基于某个特定日期 前后发布的消息。
这个模块包含两个加载器。第一个是 sklearn.datasets.fetch_20newsgroups, 返回一个能够被文本特征提取器接受的原始文本列表,例如 sklearn.feature_extraction.text.CountVectorizer 使用自定义的参数来提取特征向量。第二个是 sklearn.datasets.fetch_20newsgroups_vectorized, 返回即用特征,换句话说就是,这样就没必要使用特征提取器了。
5.8.1. 用法
sklearn.datasets.fetch_20newsgroups是一个用于从原始的20个新闻组网址( 20 newsgroups website)
下载数据归档的数据获取/缓存函数,提取 ~/scikit_learn_data/20news_home 文件夹中的 归档内容。并且在训练集或测试集文件夹,或者两者上调用函数 sklearn.datasets.load_files:
>>> from sklearn.datasets import fetch_20newsgroups
>>> newsgroups_train = fetch_20newsgroups(subset='train')
>>> from pprint import pprint
>>> pprint(list(newsgroups_train.target_names))
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
真实数据在属性 filenames 和 target 中,target属性就是类别的整数索引:
>>> newsgroups_train.filenames.shape
(11314,)
>>> newsgroups_train.target.shape
(11314,)
>>> newsgroups_train.target[:10]
array([12, 6, 9, 8, 6, 7, 9, 2, 13, 19])
可以通过将类别列表传给 sklearn.datasets.fetch_20newsgroups 函数来实现只加载一部分的类别:
>>> cats = ['alt.atheism', 'sci.space']
>>> newsgroups_train = fetch_20newsgroups(subset='train', categories=cats)
>>> list(newsgroups_train.target_names)
['alt.atheism', 'sci.space']
>>> newsgroups_train.filenames.shape
(1073,)
>>> newsgroups_train.target.shape
(1073,)
>>> newsgroups_train.target[:10]
array([1, 1, 1, 0, 1, 0, 0, 1, 1, 1])
5.8.2. 将文本转换成向量
为了用文本数据训练预测或者聚类模型,首先需要做的是将文本转换成适合统计分析的数值 向量。这能使用 sklearn.feature_extraction.text 的功能来实现,正如下面展示的 从一个20个新闻的子集中提取单个词的 TF-IDF 向量的例子
>>> from sklearn.feature_extraction.text import TfidfVectorizer
>>> categories = ['alt.atheism', 'talk.religion.misc',
... 'comp.graphics', 'sci.space']
>>> newsgroups_train = fetch_20newsgroups(subset='train',
... categories=categories)
>>> vectorizer = TfidfVectorizer()
>>> vectors = vectorizer.fit_transform(newsgroups_train.data)
>>> vectors.shape
(2034, 34118)
提取的TF-IDF向量非常稀疏,在一个超过30000维的空间中采样, 平均只有159个非零成分(少于.5%的非零成分):
>>> vectors.nnz / float(vectors.shape[0])
159.01327433628319
sklearn.datasets.fetch_20newsgroups_vectorized 是一个返回即用的tfidf特征的函数 ,而不是返回文件名。
5.8.3. 过滤文本进行更加逼真的训练
分类器很容易过拟合一个出现在20个新闻组数据中的特定事物,例如新闻组标头。许多分类器有 很好的F分数,但是他们的结果不能泛化到不在这个时间窗的其他文档。
例如,我们来看一下多项式贝叶斯分类器,它训练速度快并且能获得很好的F分数。
>>> from sklearn.naive_bayes import MultinomialNB
>>> from sklearn import metrics
>>> newsgroups_test = fetch_20newsgroups(subset='test',
... categories=categories)
>>> vectors_test = vectorizer.transform(newsgroups_test.data)
>>> clf = MultinomialNB(alpha=.01)
>>> clf.fit(vectors, newsgroups_train.target)
>>> pred = clf.predict(vectors_test)
>>> metrics.f1_score(newsgroups_test.target, pred, average='macro')
0.88213592402729568
(Classification of text documents using sparse features 的例子将训练和测试数据混合, 而不是按时间划分,这种情况下,多项式贝叶斯能得到更高的0.88的F分数.你是否还不信任这个分类器的内部实现?)
让我们看看信息量最大一些特征是:
>>> import numpy as np
>>> def show_top10(classifier, vectorizer, categories):
... feature_names = np.asarray(vectorizer.get_feature_names())
... for i, category in enumerate(categories):
... top10 = np.argsort(classifier.coef_[i])[-10:]
... print("%s: %s" % (category, " ".join(feature_names[top10])))
...
>>> show_top10(clf, vectorizer, newsgroups_train.target_names)
alt.atheism: sgi livesey atheists writes people caltech com god keith edu
comp.graphics: organization thanks files subject com image lines university edu graphics
sci.space: toronto moon gov com alaska access henry nasa edu space
talk.religion.misc: article writes kent people christian jesus sandvik edu com god
你现在可以看到这些特征过拟合了许多东西:
- 几乎所有的组都通过标题是出现更多还是更少来区分,例如
NNTP-Posting-Host:和Distribution:标题 - 正如他的标头或者签名所表示,另外重要的特征有关发送者是否隶属于一个大学。
- “article”这个单词是一个重要的特征,它基于人们像 “In article [article ID], [name] <[e-mail address]> wrote:” 的方式引用原先的帖子频率。
- 其他特征和当时发布的特定的人的名字和e-mail相匹配。
有如此大量的线索来区分新闻组,分类器根本不需要从文本中识别主题,而且他们的性能都一样好。
由于这个原因,加载20个新闻组数据的函数提供了一个叫做 remove 的参数,来告诉函数需要从文件 中去除什么类别的信息。 remove 应该是一个来自集合 ('headers', 'footers', 'quotes') 的子集 的元组,来告诉函数分别移除标头标题,签名块还有引用块。
>>> newsgroups_test = fetch_20newsgroups(subset='test',
... remove=('headers', 'footers', 'quotes'),
... categories=categories)
>>> vectors_test = vectorizer.transform(newsgroups_test.data)
>>> pred = clf.predict(vectors_test)
>>> metrics.f1_score(pred, newsgroups_test.target, average='macro')
0.77310350681274775
由于我们移除了跟主题分类几乎没有关系的元数据,分类器的F分数降低了很多。 如果我们从训练数据中也移除这个元数据,F分数将会更低:
>>> newsgroups_train = fetch_20newsgroups(subset='train',
... remove=('headers', 'footers', 'quotes'),
... categories=categories)
>>> vectors = vectorizer.fit_transform(newsgroups_train.data)
>>> clf = MultinomialNB(alpha=.01)
>>> clf.fit(vectors, newsgroups_train.target)
>>> vectors_test = vectorizer.transform(newsgroups_test.data)
>>> pred = clf.predict(vectors_test)
>>> metrics.f1_score(newsgroups_test.target, pred, average='macro')
0.76995175184521725
其他的一些分类器能够更好的处理这个更难版本的任务。试着带 --filter 选项和不带 --filter 选项运行
Sample pipeline for text feature extraction and evaluation 来比较结果间的差异。
推荐
当使用20个新闻组数据中评估文本分类器时,你应该移除与新闻组相关的元数据。你可以通过设置
remove=('headers', 'footers', 'quotes') 来实现。F分数将更加低因为这更符合实际
例子
- Sample pipeline for text feature extraction and evaluation
- Classification of text documents using sparse features
5.9. 从 mldata.org 上下载数据集
mldata.org 是一个公开的机器学习数据 repository ,由 PASCAL network 负责支持。
sklearn.datasets 包可以使用函数 sklearn.datasets.fetch_mldata 直接从 repository 下载数据集。
举个例子,下载 MNIST 手写数字字符识别数据集:
>>> from sklearn.datasets import fetch_mldata
>>> mnist = fetch_mldata('MNIST original', data_home=custom_data_home)
MNIST 手写数字字符数据集包含有 70000 个样本,每个样本带有从 0 到 9 的标签,并且样本像素尺寸大小为 28x28:
>>> mnist.data.shape
(70000, 784)
>>> mnist.target.shape
(70000,)
>>> np.unique(mnist.target)
array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
首次下载之后,数据集被缓存在本地的由 data_home 关键字指定的路径中,路径默认是 ~/scikit_learn_data/
>>> os.listdir(os.path.join(custom_data_home, 'mldata'))
['mnist-original.mat']
mldata.org 里的数据集在命名规则和数据格式上不遵循严格的约定。 sklearn.datasets.fetch_mldata 可以应对大多数的常见情况,并且允许个人对数据集的默认设置进行调整:
-
mldata.org 中的数据大多都是以
(n_features, n_samples)这样的组织形式存在。 这与scikit-learn中的习惯约定是不一致的,所以sklearn.datasets.fetch_mldata默认情况下通过transpose_data关键字控制对这个矩阵进行转置运算。:```py >>> iris = fetch_mldata('iris', data_home=custom_data_home) >>> iris.data.shape (150, 4) >>> iris = fetch_mldata('iris', transpose_data=False, ... data_home=custom_data_home) >>> iris.data.shape (4, 150)
```
-
数据集有多列的时候,
sklearn.datasets.fetch_mldata这个函数会识别目标列和数据列, 并将它们重命名为target(目标)和data(数据)。 这是通过在数据集中寻找名为label(标签)和data(数据)的数组来完成的, 如果选择第一个数组是target(目标),而第二个数组是data(数据),则前边的设置会失效。 这个行为可以通过对关键字target_name和data_name进行设置来改变,设置的值可以是具体的名字也可以是索引数字, 数据集中列的名字和索引序号都可以在 mldata.org 中的 “Data” 选项卡下找到:```py >>> iris2 = fetch_mldata('datasets-UCI iris', target_name=1, data_name=0, ... data_home=custom_data_home) >>> iris3 = fetch_mldata('datasets-UCI iris', target_name='class', ... data_name='double0', data_home=custom_data_home)
```
5.10. 带标签的人脸识别数据集
这个数据集是一个在互联网上收集的名人 JPEG 图片集,所有详细信息都可以在官方网站上获得:
每张图片的居中部分都是一张脸。典型人物人脸验证是给定两幅图片,二元分类器必须能够预测这两幅图片是否是同一个人。
另一项任务人脸识别或面部识别说的是给定一个未知的面孔,通过参考一系列已经学习经过鉴定的人的照片来识别此人的名字。
人脸验证和人脸识别都是基于经过训练用于人脸检测的模型的输出所进行的任务。 最流行的人脸检测模型叫作 Viola Jones是在 OpenCV 库中实现的。 LFW 人脸数据库中的人脸是使用该人脸检测器从各种在线网站上提取的。
5.10.1. 用法
scikit-learn 提供两个可以自动下载、缓存、解析元数据文件的 loader (加载器),解码 JPEG 并且将 slices 转换成内存映射过的 NumPy 数组(numpy.memmap)。 这个数据集大小超过 200 MB。第一个加载器通常需要超过几分钟才能完全解码 JPEG 文件的相关部分为 NumPy 数组。 如果数据集已经被加载过,通过在磁盘上采用内存映射版( memmaped version )的 memoized, 即 ~/scikit_learn_data/lfw_home/ 文件夹使用 joblib,再次加载时间会小于 200ms。
第一个 loader (加载器)用于人脸识别任务:一个多类分类任务(属于监督学习):
>>> from sklearn.datasets import fetch_lfw_people
>>> lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
>>> for name in lfw_people.target_names:
... print(name)
...
Ariel Sharon
Colin Powell
Donald Rumsfeld
George W Bush
Gerhard Schroeder
Hugo Chavez
Tony Blair
默认的 slice 是一个删除掉大部分背景,只剩下围绕着脸周围的长方形的形状:
>>> lfw_people.data.dtype
dtype('float32')
>>> lfw_people.data.shape
(1288, 1850)
>>> lfw_people.images.shape
(1288, 50, 37)
在 target(目标) 数组中,[](#id31)1140个人脸图片中的每一个图都分配一个属于某人的 id:
>>> lfw_people.target.shape
(1288,)
>>> list(lfw_people.target[:10])
[5, 6, 3, 1, 0, 1, 3, 4, 3, 0]
第二个 loader (加载器)通常用于人脸验证任务: 每个样本是属于或不属于同一个人的两张图片:
>>> from sklearn.datasets import fetch_lfw_pairs
>>> lfw_pairs_train = fetch_lfw_pairs(subset='train')
>>> list(lfw_pairs_train.target_names)
['Different persons', 'Same person']
>>> lfw_pairs_train.pairs.shape
(2200, 2, 62, 47)
>>> lfw_pairs_train.data.shape
(2200, 5828)
>>> lfw_pairs_train.target.shape
(2200,)
:func:`sklearn.datasets.fetch_lfw_people` 和 :func:`sklearn.datasets.fetch_lfw_pairs` 函数,都可以通过 ``color=True`` 来获得 RGB 颜色通道的维度,在这种情况下尺寸将为 ``(2200, 2, 62, 47, 3)`` 。
sklearn.datasets.fetch_lfw_pairs 数据集细分为 3 类: train set(训练集)、test set(测试集)和一个 10_folds 评估集, 10_folds 评估集意味着性能的计算指标使用 10 折交叉验证( 10-folds cross validation )方案。
参考文献:
- Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. Gary B. Huang, Manu Ramesh, Tamara Berg, and Erik Learned-Miller. University of Massachusetts, Amherst, Technical Report 07-49, October, 2007.
5.10.2. 示例
Faces recognition example using eigenfaces and SVMs
5.11. 森林覆盖类型
这个数据集中的样本对应美国的 30×30m 的 patches of forest(森林区域), 收集这些数据用于预测每个 patch 的植被 cover type (覆盖类型),即优势树种。 总共有七个植被类型,使得这是一个多分类问题。 每个样本有 54 个特征,在 dataset’s 的主页 中有具体的描述。 有些特征是布尔指标,其他的是离散或者连续的量。
sklearn.datasets.fetch_covtype 将加载 covertype 数据集; 它返回一个类似字典的对象,并在数据成员中使用特征矩阵以及 target 中的目标值。 如果需要,数据集可以从网上下载。
5.12. RCV1 数据集
路透社语料库第一卷( RCV1 )是路透社为了研究目的提供的一个拥有超过 800,000 份手动分类的新闻报导的文档库。该数据集在 [1] 中有详细描述。
sklearn.datasets.fetch_rcv1 将加载以下版本: RCV1-v2, vectors, full sets, topics multilabels:
>>> from sklearn.datasets import fetch_rcv1
>>> rcv1 = fetch_rcv1()
它返回一个类似字典的对象,具有以下属性:
data: 特征矩阵是一个 scipy CSR 稀疏矩阵,有 804414 个样品和 47236 个特征。 非零值包含 cosine-normalized(余弦归一化),log TF-IDF vectors。 按照年代顺序近似划分,在 [1] 提出: 前 23149 个样本是训练集。后 781265 个样本是测试集。 这是官方的 LYRL2004 时间划分。数组有 0.16% 个非零值:
>>> rcv1.data.shape
(804414, 47236)
target: 目标值是存储在 scipy CSR 的稀疏矩阵,有 804414 个样本和 103 个类别。 每个样本在其所属的类别中的值为 1,在其他类别中值为 0。数组有 3.15% 个非零值:
>>> rcv1.target.shape
(804414, 103)
sample_id: 每个样本都可以通过从 2286 到 810596 不等的 ID 来标识:
>>> rcv1.sample_id[:3]
array([2286, 2287, 2288], dtype=uint32)
target_names: 目标值是每个样本的 topic (主题)。每个样本至少属于一个 topic (主题)最多 17 个 topic 。 总共有 103 个 topics ,每个 topic 用一个字符串表示。 从 <cite>GMIL</cite> 出现 5 次到 <cite>CCAT</cite> 出现 381327 次,该语料库频率跨越五个数量级:
>>> rcv1.target_names[:3].tolist()
['E11', 'ECAT', 'M11']
如果有需要的话,可以从 rcv1 homepage 上下载该数据集。 数据集压缩后的大小大约是 656 MB。
参考文献
| [1] | (1, 2) Lewis, D. D., Yang, Y., Rose, T. G., & Li, F. (2004). RCV1: A new benchmark collection for text categorization research. The Journal of Machine Learning Research, 5, 361-397. |
5.13. 波士顿房价数据集
5.13.1. 注释
数据集特征:
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 实例数量: | 506 | | --- | --- | | 属性数量: | 13 数值型或类别型,帮助预测的属性 | | --- | --- |
:中位数(第14个属性)经常是学习目标
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 属性信息 (按顺序): |
- CRIM 城镇人均犯罪率
- ZN 占地面积超过2.5万平方英尺的住宅用地比例
- INDUS 城镇非零售业务地区的比例
- CHAS 查尔斯河虚拟变量 (= 1 如果土地在河边;否则是0)
- NOX 一氧化氮浓度(每1000万份)
- RM 平均每居民房数
- AGE 在1940年之前建成的所有者占用单位的比例
- DIS 与五个波士顿就业中心的加权距离
- RAD 辐射状公路的可达性指数
- TAX 每10,000美元的全额物业税率
- PTRATIO 城镇师生比例
- B 1000(Bk - 0.63)^2 其中 Bk 是城镇的黑人比例
- LSTAT 人口中地位较低人群的百分数
- MEDV 以1000美元计算的自有住房的中位数
| | --- | --- | | 缺失属性值: | 无 | | --- | --- | | 创建者: | Harrison, D. and Rubinfeld, D.L. | | --- | --- |
这是UCI ML(欧文加利福尼亚大学 机器学习库)房价数据集的副本。 http://archive.ics.uci.edu/ml/datasets/Housing
该数据集是从位于卡内基梅隆大学维护的StatLib图书馆取得的。
Harrison, D. 和 Rubinfeld, D.L. 的波士顿房价数据:’Hedonic prices and the demand for clean air’, J. Environ. Economics & Management, vol.5, 81-102, 1978,也被使用在 Belsley, Kuh & Welsch 的 ‘Regression diagnostics …’, Wiley, 1980。 注释:许多变化已经被应用在后者第244-261页的表中。
波士顿房价数据已被用于许多涉及回归问题的机器学习论文中。
参考资料
- Belsley, Kuh & Welsch, ‘Regression diagnostics: Identifying Influential Data and Sources of Collinearity’, Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
- many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)
5.14. 威斯康辛州乳腺癌(诊断)数据库
5.14.1. 注释
数据集特征:
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 实例数量: | 569 | | --- | --- | | 属性数量: | 30 (数值型,帮助预测的属性和类) | | --- | --- | | Attribute Information: | | --- | | |
- radius 半径(从中心到边缘上点的距离的平均值)
- texture 纹理(灰度值的标准偏差)
- perimeter 周长
- area 区域
- smoothness 平滑度(半径长度的局部变化)
- compactness 紧凑度(周长 ^ 2 /面积 - 1.0)
- concavity 凹面(轮廓的凹部的严重性)
- concave points 凹点(轮廓的凹部的数量)
- symmetry 对称性
- fractal dimension 分形维数(海岸线近似 - 1)
-
py 类:- WDBC-Malignant 恶性
- WDBC-Benign 良性
对每个图像计算这些特征的平均值,标准误差,以及“最差”(因为是肿瘤)或最大值(最大的前三个值的平均值) |
得到30个特征。例如,字段 3 是平均半径,字段 13 是半径的标准误差,字段 23 是最差半径。
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 统计摘要: |
| | | | | --- | --- | --- | | radius (mean): | 6.981 | 28.11 | | texture (mean): | 9.71 | 39.28 | | perimeter (mean): | 43.79 | 188.5 | | area (mean): | 143.5 | 2501.0 | | smoothness (mean): | 0.053 | 0.163 | | compactness (mean): | 0.019 | 0.345 | | concavity (mean): | 0.0 | 0.427 | | concave points (mean): | 0.0 | 0.201 | | symmetry (mean): | 0.106 | 0.304 | | fractal dimension (mean): | 0.05 | 0.097 | | radius (standard error): | 0.112 | 2.873 | | texture (standard error): | 0.36 | 4.885 | | perimeter (standard error): | 0.757 | 21.98 | | area (standard error): | 6.802 | 542.2 | | smoothness (standard error): | 0.002 | 0.031 | | compactness (standard error): | 0.002 | 0.135 | | concavity (standard error): | 0.0 | 0.396 | | concave points (standard error): | 0.0 | 0.053 | | symmetry (standard error): | 0.008 | 0.079 | | fractal dimension (standard error): | 0.001 | 0.03 | | radius (worst): | 7.93 | 36.04 | | texture (worst): | 12.02 | 49.54 | | perimeter (worst): | 50.41 | 251.2 | | area (worst): | 185.2 | 4254.0 | | smoothness (worst): | 0.071 | 0.223 | | compactness (worst): | 0.027 | 1.058 | | concavity (worst): | 0.0 | 1.252 | | concave points (worst): | 0.0 | 0.291 | | symmetry (worst): | 0.156 | 0.664 | | fractal dimension (worst): | 0.055 | 0.208 |
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 缺失属性值: | 无 | | --- | --- | | 类别分布: | 212 - 恶性, 357 - 良性 | | --- | --- | | 创建者: | Dr. William H. Wolberg, W. Nick Street, Olvi L. Mangasarian | | --- | --- | | 捐助者: | Nick Street | | --- | --- | | 日期: | 1995年11月 | | --- | --- |
| | --- | --- |
这是UCI ML(欧文加利福尼亚大学 机器学习库)威斯康星州乳腺癌(诊断)数据集的副本。 https://goo.gl/U2Uwz2
这些特征是从乳房肿块的细针抽吸术(FNA)的数字图像中计算得到,描述了图像中存在的细胞核的特征。
上述的分离平面是由多表面方法树(MSM-T)[K.P.Bennett, “Decision Tree Construction Via Linear Programming.” Proceedings of the 4th Midwest Artificial Intelligence and Cognitive Science Society, pp.97-101, 1992], a classification method which uses linear programming to construct a decision tree. 相关特征是在1-4的特征和1-3的分离平面中使用穷举法搜索选取出的。
用于分离平面的线性规划在三维空间中描述如下: [K. P. Bennett and O. L. Mangasarian: “Robust Linear Programming Discrimination of Two Linearly Inseparable Sets”, Optimization Methods and Software 1, 1992, 23-34].
该数据库也可通过UW CS ftp服务器获得:
ftp ftp.cs.wisc.edu cd math-prog/cpo-dataset/machine-learn/WDBC/
5.14.2. 参考资料
- W.N. Street, W.H. Wolberg and O.L. Mangasarian. Nuclear feature extraction for breast tumor diagnosis. IS&T/SPIE 1993 International Symposium on Electronic Imaging: Science and Technology, volume 1905, pages 861-870, San Jose, CA, 1993.
- O.L. Mangasarian, W.N. Street and W.H. Wolberg. Breast cancer diagnosis and prognosis via linear programming. Operations Research, 43(4), pages 570-577, July-August 1995.
- W.H. Wolberg, W.N. Street, and O.L. Mangasarian. Machine learning techniques to diagnose breast cancer from fine-needle aspirates. Cancer Letters 77 (1994) 163-171.
5.15. 糖尿病数据集
5.15.1. 注释
从442例糖尿病患者中获得了十个基线变量,年龄,性别,体重指数,平均血压和六个血清测量值,以及一个我们感兴趣的,在基线后一年疾病发展的定量测量值。
数据集特征:
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 实例数量: | 442 | | --- | --- | | 属性数量: | 前10列是数值型的帮助预测的值 | | --- | --- | | 目标: | 第11列是基线后一年疾病进展的定量测量址 | | --- | --- | | 属性: |
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | Age年龄: | | | --- | --- | | Sex性别: | | | --- | --- | | Body mass index体重指数: | | --- | | | | | Average blood pressure平均血压: | | --- | | | | | S1血清测量值1: | | | --- | --- | | S2血清测量值2: | | | --- | --- | | S3血清测量值3: | | | --- | --- | | S4血清测量值4: | | | --- | --- | | S5血清测量值5: | | | --- | --- | | S6血清测量值6: | | | --- | --- |
| | --- | --- |
注意: 这10个特征变量都已经分别以均值为中心,并按照标准偏差乘以样本数(n_samples)进行缩放(即每列的平方和为1)。
源 URL: http://www4.stat.ncsu.edu/~boos/var.select/diabetes.html
更多信息,请参阅: Bradley Efron, Trevor Hastie, Iain Johnstone and Robert Tibshirani (2004) “Least Angle Regression,” Annals of Statistics (with discussion), 407-499. (http://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf)
5.16. 光学识别手写数字数据集
5.16.1. 注释
数据集特征:
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 实例数量: | 5620 | | --- | --- | | 属性数量: | 64 | | --- | --- | | 属性信息: | 8x8 范围在(0-16)的整型像素值图片 | | --- | --- | | 缺失属性值: | 无 | | --- | --- | | 创建者: |
- Alpaydin ([email protected])
| | --- | --- | | 日期: | 1998年7月 | | --- | --- |
这是UCI ML(欧文加利福尼亚大学 机器学习库)手写数字数据集的测试集的副本。 http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
数据集包含手写数字的图像:10个类别中每个类都是一个数字。
从预印表格中提取手写数字的标准化的位图这一过程,应用了NIST提供的预处理程序。 这些数据是从43人中得到,其中30人为训练集,13人为测试集。32x32位图被划分为4x4的非重叠块, 并且在每个块中计数像素数。这产生8×8的输入矩阵,其中每个元素是0-16范围内的整数。 这个过程降低了维度,并且在小的变形中提供了不变性。
有关NIST处理程序的信息,请参见 M. D. Garris, J. L. Blue, G.T. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C. L. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469, 1994.
5.16.2. 参考资料
- C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their Applications to Handwritten Digit Recognition, MSc Thesis, Institute of Graduate Studies in Science and Engineering, Bogazici University.
- Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika.
- Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin. Linear dimensionalityreduction using relevance weighted LDA. School of Electrical and Electronic Engineering Nanyang Technological University. 2005.
- Claudio Gentile. A New Approximate Maximal Margin Classification Algorithm. NIPS. 2000.
5.17. 鸢尾花数据集
5.17.1. 注释
数据集特征:
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 实例数量: | 150 (三个类各有50个) | | --- | --- | | 属性数量: | 4 (数值型,数值型,帮助预测的属性和类) | | --- | --- | | Attribute Information: | | --- | | |
- sepal length 萼片长度(厘米)
- sepal width 萼片宽度(厘米)
- petal length 花瓣长度(厘米)
- petal width 花瓣宽度(厘米)
-
py class:- Iris-Setosa 山鸢尾
- Iris-Versicolour 变色鸢尾
- Iris-Virginica 维吉尼亚鸢尾
| | 统计摘要: | | | --- | --- |
| sepal length: | 4.3 | 7.9 | 5.84 | 0.83 | 0.7826 |
| sepal width: | 2.0 | 4.4 | 3.05 | 0.43 | -0.4194 |
| petal length: | 1.0 | 6.9 | 3.76 | 1.76 | 0.9490 (high!) |
| petal width: | 0.1 | 2.5 | 1.20 | 0.76 | 0.9565 (high!) |
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 缺失属性值: | 无 | | --- | --- | | 类别分布: | 3个类别各占33.3% | | --- | --- | | 创建者: | R.A. Fisher | | --- | --- | | 捐助者: | Michael Marshall (MARSHALL%[email protected]) | | --- | --- | | 日期: | 1988年7月 | | --- | --- |
这是UCI ML(欧文加利福尼亚大学 机器学习库)鸢尾花数据集的副本。 http://archive.ics.uci.edu/ml/datasets/Iris
著名的鸢尾花数据库,首先由R. Fisher先生使用。
这可能是在模式识别文献中最有名的数据库。Fisher的论文是这个领域的经典之作,到今天也经常被引用。(例如:Duda&Hart) 数据集包含3个类,每类有50个实例,每个类指向一种类型的鸢尾花。一类与另外两类线性分离,而后者不能彼此线性分离。
5.17.2. 参考资料
- Fisher,R.A. “The use of multiple measurements in taxonomic problems” Annual Eugenics, 7, Part II, 179-188 (1936); also in “Contributions to Mathematical Statistics” (John Wiley, NY, 1950).
- Duda,R.O., & Hart,P.E. (1973) Pattern Classification and Scene Analysis. (Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) “Nosing Around the Neighborhood: A New System Structure and Classification Rule for Recognition in Partially Exposed Environments”. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) “The Reduced Nearest Neighbor Rule”. IEEE Transactions on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al”s AUTOCLASS II conceptual clustering system finds 3 classes in the data.
- Many, many more …
5.18. Linnerrud 数据集
5.18.1. 注释
数据集特征:
<colgroup><col class="field-name"> <col class="field-body"></colgroup> | 实例数量: | 20 | | --- | --- | | 属性数量: | 3 | | --- | --- | | 缺失属性值: | 无 | | --- | --- |
Linnerud 数据集包含两个小的数据集:
- 运动 : 一个包含以下内容的列表:运动数据,关于3个运动相关变量的20个观测值:体重,腰围和脉搏。
- 生理 : 一个包含以下内容的数据表:生理数据,关于三个生理变量的20个观测值:下巴,仰卧起坐和跳跃。
5.18.2. 参考资料
- Tenenhaus, M. (1998). La regression PLS: theorie et pratique. Paris: Editions Technic.