Field Collapsing 字段折叠
允许基于字段对结果进行折叠。折叠操作是通过每个选择每个折叠键的顶部文档来实现的。例如下面的query获取每个user的最佳tweet并且根据他们的likes数量排序。
GET /twitter/tweet/_search
{
"query": {
"match": {
"message": "elasticsearch"
}
},
"collapse" : {
"field" : "user" 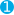
},
"sort": ["likes"], 
"from": 10 
}
 使用user字段来折叠结果集
使用user字段来折叠结果集
 按照likes数量进行排序获取顶部文档
按照likes数量进行排序获取顶部文档
 定义第一个折叠结果的偏移量
定义第一个折叠结果的偏移量
*警告:* 响应结果中的hits总数表示匹配的文档总数而不是折叠的,去重后的聚合总数是未知的。
用于折叠的字段必须是单值的keyword或numeric字段并开启doc_values(文档值)。
注意: 折叠只应用于顶部文档,而且不会影响聚合。
扩大折叠的显示结果
它也可以通过_inner_hits_参数来扩大每个折叠的顶部文档。
GET /twitter/tweet/_search
{
"query": {
"match": {
"message": "elasticsearch"
}
},
"collapse" : {
"field" : "user",
"inner_hits": {
"name": "last_tweets",
"size": 5,
"sort": [{ "date": "asc" }]
},
"max_concurrent_group_searches": 4
},
"sort": ["likes"]
}
使用"user"字段折叠结果集
name参数用来分割结果响应中的inner_hits
每个折叠内inner_hits检索到的数目
每个分组的排序方式
每个分组内允许检索inner_hits的并发请求数量
查看inner hits 对于所支持的选项的完整列表和响应的格式。
该分组的扩展是通过向响应中返回的每个折叠的命中发送一个额外的查询来完成的。请求参数 max_concurrent_group_searches 可用于控制这个阶段并发搜索的最大数量。 默认值是基于数据节点的数量和默认的搜索线程池大小。
*警告:* collapse(折叠)不能用于与[scroll](/display/Elasticsearch/Scroll),, 一同使用。