Release Notes¶
NumPy 1.13.0 Release Notes¶
此版本支持Python 2.7和3.4 - 3.6。
Highlights¶
Dropped Support¶
Deprecations¶
Build System Changes¶
Future Changes¶
Compatibility notes¶
Tuple object dtypes¶
对于无意中允许的某些模糊类型的支持已被删除,形式为(old_dtype, new_dtype)包含object dtype。作为例外,(对象, [('name', 对象)])形式的dtypes仍然支持由于现有使用的证据。
DeprecationWarning to error¶
有关更多详细信息,请参阅更改部分。
partition,当使用非整数分区索引时,TypeError。NpyIter_AdvancedNew,当oa_ndim == 0和op_axes为NULL时,ValueErrornegative(bool_),当应用于布尔值的负数时,TypeError。从布尔值减去布尔值时,减去(bool _, bool _)np.equal, np.not_equal,对象标识不覆盖失败的比较。np.equal, np.not_equal,对象标识不覆盖非布尔值比较。- 布尔索引已弃用的行为已删除。有关详细信息,请参阅下面的更改。
FutureWarning to changed behavior¶
有关更多详细信息,请参阅更改部分。
numpy.average保留子类阵列 == 无和数组 / t6> 无进行元素方面的比较。np.equal, np.not_equal,对象标识不覆盖比较结果。
dtypes are now always true¶
以前bool(dtype)将回到默认的python实现,它检查len(dtype) > 0。由于dtype对象将__len__实现为记录字段数,因此标量类型的bool将计算为False是不直观。现在对所有dtypes,bool(dtype) == True
__getslice__ and __setslice__ have been removed from ndarray¶
当在Python 2.7子类化np.ndarray时,不再_necessary_在派生类上实现__*slice__,因为__*item__会正确拦截这些调用。
任何实现这些的代码都会像以前一样工作,显然只有直接调用ndarray.__getslice__的代码(例如通过super(...).__getslice__在这种情况下,。getitem __(slice(start, end))将作为替换。
np.squeeze always returns an array when passed a scalar¶
以前,这只是传递一个python标量的情况,并没有做数组推广时传递numpy标量。
C API¶
New Features¶
axes argument for unique¶
在N维数组中,用户现在可以使用numpy.unique选择沿其查找重复的N-1维元素的轴。如果axis=None(默认值),则会恢复原始行为。
Improvements¶
Partial support for 64-bit f2py extensions with MinGW¶
包含Fortran库的扩展现在可以使用免费的MinGW工具集构建,也在Python 3.5下。这对于仅执行计算并且适度使用运行时的扩展(例如,从文件读取和写入)最有效。注意这并不能消除Mingwpy的需要;如果你广泛使用运行时,你很可能会遇到issues_。相反,它应该被视为一个助盲,直到Mingwpy完全功能。
扩展也可以使用MinGW工具集使用来自(可移动)WinPython 3.4发行版的运行时库来编译,这对于具有PySide1 / Qt4前端的程序非常有用。
Performance improvements for packbits and unpackbits¶
具有布尔输入和numpy.unpackbits的函数numpy.packbits已优化为连续数据的速度明显更快。
Fix for PPC long double floating point information¶
在先前版本的numpy中,finfo函数返回有关Power PC(PPC)上longdouble float类型的双精度格式的无效信息。无效值是由于numpy算法无法处理有效位数中的可变数字位数(这是PPC长度加倍的特征)而导致的。此版本通过使用启发式检测PPC双重双精度格式的存在来绕过失败的算法。使用这些启发式的副作用是finfo函数比以前的版本更快。
Support for returning arrays of arbitrary dimensionality in apply_along_axis¶
以前,传递给apply_along_axis的函数只能返回标量或1D数组。现在,它可以返回任何维数(包括0D)的数组,并且此数组的形状将替换要迭代的数组的轴。
Changes¶
average now preserves subclasses¶
对于ndarray子类,numpy.average现在将返回子类的实例,与大多数其他numpy函数(例如mean)的行为匹配。因此,返回标量的调用现在可以返回子类数组标量。
array == None and array != None do element-wise comparison¶
以前,这些操作分别返回标量False和True。
np.equal, np.not_equal for object arrays ignores object identity¶
以前,这些函数总是将相同的对象视为相等。这具有覆盖比较失败的效果,没有返回布尔值的对象(例如np.arrays)的比较,以及其中结果不同于对象身份(例如NaN)的对象的比较。
Boolean indexing changes¶
- 布尔数组类似(例如python bools的列表)总是被当作布尔索引。
- 布尔标量(包括python
True)是合法的布尔值,从不作为整数处理。 - 布尔索引必须与它们索引的轴的维度匹配。
- 在分配的lhs上使用的布尔索引必须与rhs的维度匹配。
- 布尔索引到标量数组中返回一个新的1-d数组。这意味着
array(1)[array(True)]给出array([1]),而不是原始数组。
np.random.multivariate_normal behavior with bad covariance matrix¶
现在可以通过使用两个新的关键字参数来调整函数处理协方差矩阵时的行为:
tol可用于指定在检查协方差矩阵为正半定期时使用的容差。check_valid可用于配置在存在非正半矩阵的情况下函数将执行的操作。有效选项为ignore,warn和raise。默认值warn保留以前版本中使用的行为。
assert_array_less compares np.inf and -np.inf now¶
以前,np.testing.assert_array_less忽略所有无限值。这不是根据文档和直观的预期行为。Now, -inf < x < inf is considered True for any real number x and all other cases fail.
offset attribute value in memmap objects¶
memmap对象中的offset属性现在设置为文件的偏移量。这是仅对大于mmap.ALLOCATIONGRANULARITY的偏移量的行为更改。
NumPy 1.12.0 Release Notes¶
此版本支持Python 2.7和3.4 - 3.6。
Highlights¶
NumPy 1.12.0版本包含大量的修复和改进,但很少有超过所有其他。这使得选择的亮点有点武断,但以下可能是特别感兴趣或指示可能有未来后果的领域。
- 现在可以优化
np.einsum中的操作顺序,以实现大幅度的速度改进。 np.vectorize的新signature参数用于使用核心维度进行向量化。keepdims参数已添加到许多函数。- 用于测试警告的新上下文管理器
- 在numpy.distutils中支持BLIS
- 对PyPy的更多支持(尚未完成)
Dropped Support¶
- 支持Python 2.6,3.2和3.3已被删除。
Added Support¶
- 已添加对PyPy 2.7 v5.6.0的支持。虽然尚未完成(nditer
updateifcopy)尚未支持,但这是PyPy的C-API兼容性层的里程碑。
Build System Changes¶
- 保存库顺序,而不是重新排序以匹配目录的顺序。
Deprecations¶
分配'data'属性是一个固有的不安全操作,如gh-7083中所指出的。这种能力将在将来消除。
np.linspace现在引发DeprecationWarning,当num不能安全地解释为整数。
如果将'width'参数传递给binary_repr,不足以表示基数2(正)或2的补数(负数)形式的数字,则用于静默忽略该参数并返回一个表示使用所讨论的表单所需的最小位数。从用户的角度来看,这种行为现在被认为是不安全的,并且将来会引发错误。
Future Changes¶
- 在1.13中,除了
NAT != NAT,NAT将始终比较False,总之,NAT的行为就像NaN - 在1.13
np.average中将保留子类,以匹配大多数其他numpy函数(如np.mean)的行为。特别地,这意味着返回标量的调用可以返回0-d子类对象。
在1.13中,涉及多个字段的结构化数据的行为将以两种方式改变:
首先,索引具有多个字段的结构化数组(例如,arr [['f1', 'f3']])将返回视图进入原数组在1.13,而不是一个副本。注意,返回的视图将具有与原始数组中的中间字段相对应的额外填充字节,这与1.12中的复制不同,后者将影响诸如arr [['f1', 'f3']]。view(newdtype)。
第二,对于numpy版本1.6到1.12,结构化数据之间的分配发生“按字段名称”:目标数组中的字段设置为源数组中的同名字段,如果源没有字段,则为0:
>>> a = np.array([(1,2),(3,4)], dtype=[('x', 'i4'), ('y', 'i4')])
>>> b = np.ones(2, dtype=[('z', 'i4'), ('y', 'i4'), ('x', 'i4')])
>>> b[:] = a
>>> b
array([(0, 2, 1), (0, 4, 3)],
dtype=[('z', '<i4'), ('y', '<i4'), ('x', '<i4')])
在1.13中,分配将改为发生“按位置”:目的地的第N个字段将被设置为源的第N个字段,而不管字段名称。The old behavior can be obtained by using indexing to reorder the fields before assignment, e.g., b[['x', 'y']] = a[['y', 'x']].
Compatibility notes¶
- 使用浮动索引会引发
IndexError,例如a [0,0.0]。 - 使用非整数array_like的索引引起
IndexError,例如,a ['1', '2'] - 使用多个省略号进行索引会引起
IndexError,例如a [..., ...]。 - 用作索引值的非整数会引起
TypeError,例如在reshape,take中指定reduce轴。
np.full现在返回填充值的dtype的数组,如果没有给出dtype,而不是默认为float。np.average会在参数是ndarray的子类时发出警告,因为子类将从1.13开始保留。(见未来变化)
之前的行为取决于是否涉及numpy标量整数或numpy整数数组。
数组
- 零到负整数幂返回最小积分值。
- 1,-1到负的整数幂都返回正确的值。
- 剩余的整数在提升到负整数幂时返回零。
对于标量
- 零到负整数幂返回最小积分值。
- 1,-1到负的整数幂都返回正确的值。
- 其余的整数有时返回零,有时正确的浮点取决于整数类型组合。
除了那些常见类型为float的整数组合,例如uint64和int8,所有这些情况现在都会产生一个ValueError。人们认为,一个简单的规则是最好的方法,而不是对整数单元有特殊的例外。如果你需要负功率,使用不精确类型。
这将对假设F_CONTIGUOUS和C_CONTIGUOUS是互斥的代码产生一些影响,并且可以设置为确定现在两个数组的默认顺序。
“中点”插值器现在给出与“较低”和“较高”相同的结果,当两个重合时。'lower'+ 0.5的先前行为是固定的。
采用keepdims kwarg的numpy函数现在将值传递到ndarray子类上的相应方法。以前,keepdims关键字将被静默删除。这些函数现在具有以下行为:
- 如果用户未提供
keepdims,则不会将关键字传递给底层方法。 - 任何用户提供的
keepdims值都将作为关键字参数传递给方法。
这将在该方法不支持keepdims kwarg并且用户在keepdims中明确传递的情况下引发。
The following functions are changed: sum, product, sometrue, alltrue, any, all, amax, amin, prod, mean, std, var, nanmin, nanmax, nansum, nanprod, nanmean, nanmedian, nanvar, nanstd
前面的标识为1,现在为-1。有关详细说明,请参阅`Improvements`_中的条目。
类似于未屏蔽的中值,屏蔽的中值ma.median现在发出运行时警告,并在存在未屏蔽的NaN的片中返回NaN。
标量的精度检查已更改为与数组匹配。就是现在:
abs(actual - desired) < 1.5 * 10**(-decimal)
请注意,这比以前记录的更宽松,但与assert_array_almost_equal中使用的先前实现一致。由于实施的变化,一些非常精细的测试可能失败,之前没有失败。
当给定raise_warnings="develop"时,所有未捕获的警告现在将被视为测试失败。以前只选择了一些。没有被捕获或提高的警告(大多在释放模式下)将在测试周期中显示一次,类似于默认的python设置。
assert_warns函数和上下文管理器现在更具体到给定的警告类别。这种增加的特异性导致它们根据外部警告设置被处理。这意味着在给出错误的类别警告并在上下文之外忽略的情况下,不会发出警告。或者,增加的特异性可意味着现在将显示或提高被错误地忽略的警告。另请参见新的suppress_warnings上下文管理器。对于deprecated装饰器也是如此。
没有变化。
New Features¶
np.lib.stride_tricks.as_strided现在有一个writeable关键字参数。如果不希望对返回的数组进行写操作,则可以将其设置为False,以避免意外的不可预测的写入。
rot90中的axes关键字参数确定数组在其中旋转的平面。它在原始函数中默认为axes=(0,1)。
flipud和fliplr分别沿轴= 0和轴= 1反转数组的元素。新添加的flip函数使数组的元素沿任意给定轴反转。
np.count_nonzero现在具有axis参数,允许在不仅仅是平面化的数组对象上生成非零计数。
现在支持根据BLIS库提供的BLAS实现。请参阅site.cfg.example中的[blis]部分(在numpy repo或源分发的根目录中)。
numpy的二进制分布可能需要运行特定的硬件检查或在numpy初始化期间加载特定的库。例如,如果我们使用需要SSE2指令的BLAS库来分发numpy,我们想检查正在运行numpy的机器是否具有SSE2,以提供信息性错误。
在numpy/__init__.py中添加一个钩子以导入在标准numpy源中保持为空(bar docstring)的numpy/_distributor_init.py文件,被numpy的二进制分发的人覆盖。
已添加纳米函数nancumsum和nancumprod以通过忽略n来计算cumsum和cumprod。
np.lib.interp(x, xp, fp) now allows the interpolated array fp to be complex and will interpolate at complex128 precision.
新函数polyvalfromroots根据多项式的根计算给定点处的多项式。这对于高阶多项式是有用的,其中在机器精度下扩展为多项式系数不准确。
新函数geomspace生成几何序列。它类似于logspace,但直接指定start和stop:geomspace(start, stop) 与logspace(log10(start), log10(stop))相同。
新的上下文管理器suppress_warnings已添加到测试实用程序。此上下文管理器旨在帮助可靠地测试警告。特别是可靠地过滤/忽略警告。在3.4.x之前的Python版本中使用“忽略”过滤器忽略警告可能会导致这些(或类似)警告不能可靠地测试。
上下文管理器允许过滤(以及记录)类似于catch_warnings上下文的警告,但允许更容易的特异性。还打印没有被过滤或嵌套上下文管理器的警告将按预期工作。另外,可以使用上下文管理器作为装饰器,当多个测试需要隐藏相同的警告时,它是有用的。
这些函数包装非掩码版本,但是通过掩码值传播。有两种不同的传播模式。默认值会导致屏蔽值使用掩码来污染结果,但是如果没有其他选项,则其他模式仅输出掩码。
新的float_power ufunc类似于power函数,除了所有计算都是以float64的最小精度完成的。有关如何处理整数为负整数幂的numpy邮件列表的长期讨论,一个流行的建议是,__pow__运算符应始终返回至少float64精度的结果。float_power函数实现该选项。注意它不支持对象数组。
而不是使用usecol=(n,)来读取文件的第n列,现在允许使用usecol=n。此外,当非整数作为列索引传递时,错误消息更加用户友好。
通过bins参数将“doane”和“sqrt”估计值添加到histogram。添加了对自动化箱子估计的范围受限直方图的支持。
到roll的shift和axis参数现在彼此广播,每个指定的轴都相应移动。
在大小为1的数组上调用complex()现在将转换为python复合体。
标准np.load,np.save,np.loadtxt,np.savez现在以pathlib.Path对象作为参数,而不是文件名或打开的文件对象。
这使得np.finfo与已经具有该属性的np.iinfo一致。
此参数允许以NumPy的generalized universal functions样式为核心维度的用户定义函数进行向量化。这允许向量化更宽泛的类的功能。例如,组合两个向量以产生标量的任意距离度量可以用signature='(n),(n)->()'向量化。有关详细信息,请参阅np.vectorize。
为了帮助人们将他们的代码库从Python 2迁移到Python 3,python解释器有一个方便的选项-3,它在运行时发出警告。其中一个警告是整数除法:
$ python -3 -c "2/3"
-c:1: DeprecationWarning: classic int division
在Python 3中,新的整数除法语义也适用于numpy数组。有了这个版本,numpy会发出类似的警告:
$ python -3 -c "import numpy as np; np.array(2)/np.array(3)"
-c:1: DeprecationWarning: numpy: classic int division
以前,它包括str(字节)和unicode在Python2,但只有str(unicode)在Python3。
Improvements¶
前面的标识为1,结果是当使用reduce方法时除了LSB之外的所有位被屏蔽。新标识是-1,它应该在二进制补码机上正常工作,因为所有位将被设置为1。
广义Ufunc,包括大多数linalg模块,现在将解锁Python全局解释器锁。
在np.fft中加速相同长度的连续FFT的高速缓存不能再无边界增长。它们已被替换为LRU(最近最少使用)高速缓存,如果已经达到存储器大小或项目计数限制,则它们自动驱逐不再需要的项目。
修复了几个接口,这些接口明确禁止具有零宽度字符串dtypes(即dtype('S0')或dtype('U0')的数组,没有正确处理。特别地,改变ndarray.__new__以不隐式地将dtype('S0')转换为dtype('S1') )创建新数组时。
如果cpu在运行时支持它,则基本整数ufuncs现在使用AVX2指令。此功能目前仅在使用GCC编译时可用。
np.einsum现在支持optimize参数,这将优化收缩的顺序。For example, np.einsum would complete the chain dot example np.einsum(‘ij,jk,kl->il’, a, b, c) in a single pass which would scale like N^4; however, when optimize=True np.einsum will create an intermediate array to reduce this scaling to N^3 or effectively np.dot(a, b).dot(c). 使用中间张量来减少缩放已经应用于一般的电感总和符号。有关详细信息,请参见np.einsum_path。
快速排序类型的np.sort和np.argsort现在是一个introsort是正常快速排序,但是当没有足够的进度时更改为堆。这保持了良好的快速排序性能,同时将最差情况运行时间从O(N^2)改变到O(N*log(N))。
ediff1d函数使用数组代替平面迭代器进行减法。当to_begin或to_end不是None时,执行减法以消除复制操作。一个副作用是某些子类被更好地处理,即astropy.Quantity,因为完整的数组被创建,包装,然后开始和结束值被设置,而不是使用concatenate。
float16数组的平均值的计算现在在float32中执行以提高精度。这在诸如Theano的软件包中是有用的,其中float16的精度是足够的,并且其较小的占用面积是可取的。
Changes¶
在内部,fromnumeric.py中的许多数组类方法被调用的位置参数,而不是关键字参数,因为他们的外部签名在做。这导致在下游的“pandas”库中遇到“numpy”兼容性问题的复杂性。现在,这个模块中所有类似数组的方法都用关键字参数调用。
以前对memmap对象的操作会误导性地返回一个memmap实例,即使结果实际上没有被memmapped。例如,arr + 1或arr + arr将返回memmap实例,但输出数组中没有内存映射。版本1.12从这些操作返回普通numpy数组。
此外,减少memmap(例如.sum(axis=None))现在返回numpy标量,而不是0d memmap。
增加了基于python的警告的stacklevel,以便大多数警告将报告用户代码的违规行,而不是警告本身。现在测试传递stacklevel,以确保新的警告将接收stacklevel参数。
这会使每个违规用户代码行或用户模块显示一次“默认”或“模块”过滤器的警告,而不只是一次。在python版本3.4之前,这可能导致出现的警告,以前被错误地忽略,这可能是惊讶的,特别是在测试套装。
Contributors¶
共有139人贡献了这个版本。人们用他们的名字“+”第一次提供补丁。
- Aditya Panchal +
- Ales Erjavec +
- 亚历克斯格里芬
- Alexandr Shadchin +
- Alistair Muldal
- Allan Haldane
- Amit Aronovitch +
- Andrei Kucharavy +
- 安东尼李
- Antti Kaihola +
- Arne de Laat +
- Auke Wiggers +
- AustereCuriosity +
- Badhri Narayanan Krishnakumar +
- 本北+
- 本·罗兰+
- Bertrand Lefebvre
- 孙伯良
- CJ Carey
- 查尔斯·哈里斯
- Christoph Gohlke
- Daniel Ching +
- 丹尼尔Rasmussen +
- 丹尼尔·史密斯+
- David Schaich +
- Denis Alevi +
- Devin Jeanpierre +
- Dmitry Odzerikho
- 东风Hyun +
- 爱德华理查兹
- Ekaterina Tuzova +
- Emilien Kofman +
- 内石
- Eren Sezener +
- 埃里克·摩尔
- Eric Quintero +
- Eric Wieser +
- Erik M. Bray
- 弗雷德里克·巴斯蒂安
- Friedrich Dunne +
- Gerrit Holl
- Golnaz Irannejad +
- Graham Markall +
- Greg Knoll +
- Greg Young
- Gustavo Serra Scalet +
- Ines Wichert +
- Irvin Probst +
- Jaime Fernandez
- 詹姆斯·桑德斯+
- Jan David Mol +
- JanSchlüter
- Jeremy Tuloup +
- 约翰·柯克姆
- 约翰·Zwinck +
- 乔纳森·赫尔穆斯
- 约瑟夫·福克斯 - 拉比诺维茨
- Josh Wilson +
- 约书亚华纳+
- 朱利安·泰勒
- Ka Wo Chen +
- Kamil Rytarowski +
- Kelsey Jordahl +
- Kevin Deldycke +
- Khaled本Abdallah Okuda +
- 狮子Krischer +
- LoïcEstève+
- Luca Mussi +
- Mads Ohm Larsen +
- Manoj Kumar +
- 马里奥Emmenlauer +
- Marshall Bockrath-Vandegrift +
- 马歇尔病区+
- Marten van Kerkwijk
- Mathieu Lamarre +
- 马修·布雷特
- Matthew Harrigan +
- Matthias Geier
- Matti Picus +
- 认识Udeshi +
- Michael Felt +
- Michael Goerz +
- 迈克尔·马丁+
- Michael Seifert +
- 迈克·诺尔塔+
- Nathaniel Beaver +
- Nathaniel J. Smith
- Naveen Arunachalam +
- 尼克Papior
- NikolaForró+
- Oleksandr Pavlyk +
- Olivier Grisel
- Oren Amsalem +
- Pauli Virtanen
- Pavel Potocek +
- Pedro Lacerda +
- 彼得Creasey +
- Phil Elson +
- 菲利普·古拉+
- Phillip J. Wolfram +
- Pierre de Buyl +
- Raghav RV +
- Ralf Gommers
- Ray Donnelly +
- Rehas Sachdeva
- Rob Malouf +
- 罗伯特·凯恩
- 塞缪尔·圣 - 让
- Sanchez Gonzalez Alvaro +
- Saurabh Mehta +
- Scott Sanderson +
- 塞巴斯蒂安·伯格
- Shayan Pooya +
- Shota川口+
- Simon Conseil
- 西蒙吉本斯
- Sorin Sbarnea +
- Stefan van der Walt
- Stephan Hoyer
- Steven J Kern +
- Stuart Archibald
- Tadeu Manoel +
- Takuya Akiba +
- 托马斯·卡斯韦尔
- 汤姆鸟+
- 托尼·凯尔曼+
- 上岛上岛+
- Valentin Valls +
- Varun Nayyar
- 维克托·斯廷特+
- Warren Weckesser
- 温德尔·史密斯
- Wojtek Ruszczewski +
- Xavier Abellan Ecija +
- 雅罗斯拉夫Halchenko
- Yash Shah +
- Yinon Ehrlich +
- 余峰+
- nevimov +
Pull requests merged¶
此版本共有418个请求合并。
- #4073:BUG:更改实际输出检查以测试所有虚部...
- #4619:BUG:np.sum默默地丢弃ndarray的子类的keepdims
- #5488:ENH:add contract:优化numpy的einsum表达式
- #5706:ENH:make some masked数组方法的行为更像ndarray ...
- #5822:允许许多分布具有0的比例。
- #6054:WIP:MAINT:对多字段索引的视图添加弃用警告
- #6298:检查base_repr中的下限基线。
- #6430:修复零宽度字符串字段的问题
- #6656:ENH:usecols现在接受一个int,只有一列必须...
- #6660:为几个函数添加了pathlib支持
- #6872:ENH:lib.interp中的复数值的线性插值
- #6997:MAINT:简化mtrand.pyx助手
- #7003:BUG:修复np.place的字符串复制
- #7026:DOC:澄清np.random.uniform中的行为
- #7055:BUG:一个元素数组输入np.random中的回报
- #7063:REL:在1.11.x分支之后更新主分支。
- #7073:DOC:更新1.11.0发行说明。
- #7076:MAINT:更新git .mailmap文件。
- #7082:TST,DOC:在test_random.py中添加了广播测试
- #7087:BLD:修复非glibc-Linux上的编译
- #7088:BUG:有norm将非浮点数组转换为64位浮点数...
- #7090:ENH:在numpy.function_base中添加了“doane”和“sqrt”估计值
- #7091:恢复“BLD:修复非glibc-Linux上的编译”
- #7092:BLD:修复非glibc-Linux上的编译
- #7099:TST:抑制警告
- #7102:MAINT:删除在datetime_strings.c中始终为false的条件
- #7105:DEP:不推荐使用as_strided,将可写数组返回为默认值
- #7109:DOC:更新安装文档中的Python版本要求
- #7114:MAINT:修复文档中的拼写错误
- #7116:TST:修复了win32 virtualenv的f2py测试
- #7118:TST:修复了非版本化python可执行文件的f2py测试
- #7119:BUG:修复了mingw.lib错误
- #7125:DOC:更新文档措辞和np.percentile的示例。
- #7129:BUG:在奇数情况下固定np.percentile的“中点”插值。
- #7131:修复setuptools sdist
- #7133:ENH:savez:临时文件与目标文件一起提高...
- #7134:MAINT:修改代码字符串和注释中的一些拼写错误
- #7141:BUG:未抽取的空标量应该是连续的
- #7144:MAINT:在评论中将call_fortran更改为callfortran。
- #7145:BUG:参考#5737和#5729,在np.pagewise中固定回归。
- #7147:暂时停用__numpy_ufunc__
- #7148:ENH,TST:Bump stacklevel并添加警告测试
- #7149:TST:向temppath管理器添加缺少的后缀
- #7152:BUG:mode kwargs作为unicode传递给np.pad引发异常
- #7156:BUG:确认linspace尊重ndarray子类...
- #7167:DOC:更新mtrand.pyx的维基百科参考
- #7171:TST:修复了Anaconda non-win32的f2py测试
- #7174:DOC:修复发行说明中的破坏的熊猫链接
- #7177:ENH:np.count_nonzero的轴参数
- #7178:BUG:修正binary_repr为负数
- #7180:BUG:修复了以前尝试修复nanpercentile中的尺寸不匹配
- #7181:DOC:更新了function_base.py和test_function_base.py中的小错字
- #7191:DOC:添加vstack,hstack,dstack对堆栈文档的引用。
- #7193:MAINT:在直方图估计中删除了超重断言
- #7194:BUG:为掩码更改提高一个更安静的MaskedArrayFutureWarning。
- #7195:STY:在
numpy.ma.core中删除一些尾随空格。 - #7196:还原“DOC:添加vstack,hstack,dstack对堆栈文档的引用。
- #7197:TST:在Travis CI上使用pin virtualenv。
- #7198:ENH:解锁gufunc的GIL
- #7199:MAINT:清除直方图单元格估计器选择
- #7201:在python2中的一个文件上提升IOError
- #7202:MAINT:使可迭代返回布尔值
- #7209:TST:Bump virtualenv至14.0.6
- #7211:DOC:修正fmin示例
- #7215:MAINT:使用PySlice_GetIndicesEx而不是自定义重新实现
- #7229:ENH:implement __complex__
- #7231:MRG:允许分销商运行自定义init
- #7232:BLD:切换lapack_mkl和openblas_lapack的测试顺序
- #7239:DOC:从前一次提交中删除了残留合并标记
- #7240:将“pubic”更改为“public”。
- #7241:MAINT:将doc / sphinxext更新为numpydoc 0.6.0,并修正一些...
- #7243:ENH:为范围关键字添加支持以估计...
- #7246:DOC:metion writeable关键字在发行说明的as_strided
- #7247:TST:AppVeyor上快速失败,取代PR版本
- #7248:DOC:删除HOWTO_DOCUMENT的文档Wiki编辑器的链接。
- #7250:DOC,REL:更新1.11.0注释。
- #7251:BUG:只有基准complex256(如果存在)
- #7252:转发端口从1.11.x的修复和增强
- #7253:DOC:注释在h / v / dstack点用户堆叠/连接
- #7254:BUG:为randint单例强制执行dtype
- #7256 t>:MAINT:使用无或不是无,而不是== None
- #7257:DOC:在docstr中修复不匹配的变量名。
- #7258:ENH:Make numpy floor_divide and remainder agree with Python ...
- #7260:BUG / TST:修复#7259,不要对已经是标量的“强制标量”...
- #7261:添加了自我到mailmap
- #7266:BUG:Segfault for classes with欺骗性__len__
- #7268:ENH:add geomspace function
- #7274:BUG:在np.delete中保留数组顺序
- #7275:DEP:警告分配ndarray的“data”属性
- #7276:DOC:apply_along_axis missing whitespace inserted(在冒号前)
- #7278:BUG:返回unravel_index数组可写
- #7279:TST:固定元素被混洗
- #7280:MAINT:删除多余的尾部分号。
- #7285:BUG:使Randint向后兼容Pandas
- #7286:MAINT:修复ma和多项式模块的文档/注释中的拼写错误。
- #7292:澄清assert_equal中repr失败的错误。
- #7294:ENH:向BLIS添加对numpy.distutils的支持
- #7295:DOC:了解代码和开始部分到dev doc
- #7296:还原#3907的不正确传播MaskedArray的部分...
- #7299:DOC:在docstrings中修复不匹配的变量名。
- #7300:DOC:dev:停止推荐保持本地主服务器更新为...
- #7301:DOC:更新发行说明
- #7305:BUG:删除mtrand中的数据竞争:两个线程可以突变...
- #7307:DOC:链接中缺少一些字符。
- #7308:BUG:返回时增加错误的引用
- #7310:STY:修复有序列表的GitHub呈现> 9
- #7311:ENH:使_pointer_type_cache功能
- #7313:DOC:quickstart doc中的校正语法错误
- #7325:BUG,MAINT:改进fromnumeric.py接口以实现下游兼容性
- #7328:DEP:在linspace中使用浮点索引不推荐使用
- #7331:在win32上添加注释,TST:修复MemoryError
- #7332:检查np.irr Fixes#6744中没有解决方案
- #7338:TST:在CI中安装
pytz。 - #7340:DOC:修复了tensordot文档中的数学呈现。
- #7341:TST:为#6469添加测试
- #7344:DOC:在文档和注释中修复更多拼写错误。
- #7346:广义翻转
- #7347:ENH广义rot90
- #7348:维护:从ureduce中移除了额外的空间
- #7349:MAINT:隐藏屏蔽的内部MA计算的nan警告
- #7350:BUG:MA ufuncs应将掩码设置为False,而不是数组([False])
- #7351:TST:修复一些MA测试,以避免查看.data属性
- #7358:BUG:pull请求与问题#7353相关
- #7359:更新7314,DOC:明确random.seed的有效整数范围...
- #7361:MAINT:修复复制和粘贴忽略。
- #7363:ENH:不要取消共享屏蔽未来警告更少噪音
- #7366:TST:fix#6542,添加测试以检查非可迭代参数引发...
- #7373:ENH:添加bitwise_and identity
- #7378:添加NumPy徽标和分隔符
- #7382:MAINT:cleanup np.average
- #7385:DOC:关于pypi的车轮/窗轮的注意事项
- #7386:已将标签图标添加到Travis状态
- #7397:BUG:__len__失败的对象的类型不正确
- #7398:DOC:fix typo
- #7404:对Python 3.4及更高版本使用PyMem_RawMalloc
- #7406:ENH ufunc调用memmap返回一个ndarray
- #7407:BUG:在就地累积之前,在递减之前修复减少
- #7410:DOC:将nanprod添加到数学例程列表
- #7414:Tweak corrcoef
- #7415:DOC:文件修正
- #7416:BUG:直方图范围处理不正确,自动...
- #7418:DOC:次要拼写错误,hermefik - > hermefit。
- #7421:ENH:添加np.nancumsum和np.nancumprod
- #7423:BUG:正在修复PR#7416
- #7430:DOC:更新1.11.0-注释。
- #7433:MAINT:FutureWarning,用于更改np.average子类处理
- #7437:np.full现在默认为填充值的dtype。
- #7438:允许同时滚动多个轴。
- #7439:BUG:除非必要,否则不要尝试序列重复
- #7442:MANT:简化对角线长度计算逻辑
- #7445:BUG:引用计数泄漏在bincount中,修复#6805
- #7446:DOC:ndarray拼写错误
- #7447:BUG:标量整数负功率给出错误的结果。
- #7448:DOC:数组“另请参阅”链接到full和full_like而不是填充
- #7456:BUG:int overflow in reshape,fixes#7455,fixes#7293
- #7463:BUG:修复数组太大的错误,对于宽dtypes。
- #7466:BUG:segfault inplace object reduceat,fixes#7465
- #7468:BUG:更多内容缩减,修复#615
- #7469:MAINT:更新git .mailmap
- #7472:MAINT:更新.mailmap。
- #7477:MAINT:最近的贡献者还有更多.mailmap更新。
- #7481:BUG:修正PyArray_OrderConverter中的segfault
- #7482:BUG:_GenericBinaryOutFunction中的内存泄漏
- #7489:更快的real_if_close。
- #7491:DOC:更新关于下游兼容性的子类化文档
- #7496:BUG:不要对整数幂ufunc循环使用pow。
- #7504:DOC:从keepdims文档字符串中删除“arr”
- #7505:MAIN:fix to#7382,make scl in np.average writeable
- #7507:MAINT:删除nose.SkipTest导入。
- #7508:DOC:link frompyfunc and vectorize
- #7511:numpy.power(0,0)应返回1
- #7515:BUG:MaskedArray.count无法正确处理负轴
- #7518:BUG:扩展glibc复杂的trig函数黑名单到glibc <...>
- #7521:DOC:重写memmap更改的写入
- #7522:BUG:修复了其他错误命令的迭代
- #7526:DOC:移除了额外的:const:
- #7529:BUG:np.lexsort中带有无效轴的浮动异常
- #7534:MAINT:更新setup.py以反映支持的python版本。
- #7536:MAINT:在mtrand.pyx中始终使用PyCapsule而不是PyCObject
- #7539:MAINT:清除随机素材
- #7549:BUG:允许没有Liux编译器的正常恢复
- #7562:BUG:Fix test_from_object_array_unicode(test_defchararray.TestBasic)...
- #7565:BUG:修复test_ctypeslib和test_indexing用于调试解释器
- #7566:MAINT:使用manylinux1 wheel for cython
- #7568:当值高于...时,在Python 3.x中修正一个假阳性OverflowError
- #7579: DOC: clarify purpose of Attributes section
- #7584:BUG:修复#7572,路径中的百分比
- #7586:使np.ma.take在标量上工作
- #7587:BUG:linalg.norm():不要将对象数组转换为float
- #7598:从存档加载时将数据组大小转换为int64
- #7602:DOC:从ufunc列表中删除isreal和iscomplex
- #7605:DOC:修正不正确的Gamma分布参数化注释
- #7609:BUG:在提高TypeError时修复TypeError
- #7611:ENH:暴露测试运行程序raise_warnings选项
- #7614:BLD:避免在exec_command中使用os.spawnve而使用os.spawnv
- #7618:BUG:np.gradient的距离arg必须是标量,修正docstring
- #7626:DOC:RST定义列表修复
- #7627:MAINT:统一tup处理,移动tup使用后的所有PyTuple_SetItem ...
- #7630:MAINT:在PyDictProxy_Check宏周围添加ifdef
- #7631:MAINT:linalg:修复注释,简化数学
- #7634:BLD:system_info.py中正确的C编译器定制关闭...
- #7635:BUG:ma.median替代修订#7592
- #7636:MAINT:清理testing.assert_raises_regexp,2.6特定代码...
- #7637:MAINT:导入多阵列失败时更清晰的异常消息。
- #7639:TST:修复master中的一组测试错误。
- #7643:DOC:对linspace docstring的微小更改
- #7651:BUG:一个任意幂仍为1。int数组的破坏edgecase
- #7655:BLD:删除Intel编译器标志-xSSE4.2
- #7658:BUG:修正1D屏蔽数组的错误打印
- #7659:BUG:对于字段类型为str(mvoid)的临时修订
- #7664:BUG:使用字节交换传输和copyswap修复Unicode
- #7667:恢复直方图一致性
- #7668:ENH:不要在测试中检查模块类型.__ dict__ explicit。
- #7669:BUG:布尔分配没有GIL释放时传输需要API
- #7673:DOC:创建Numpy 1.11.1发行说明。
- #7675:BUG:修正最终仓位右边缘的处理。
- #7678:BUG:Fix np.clip bug Visual Studio 2015的NaN处理
- #7679:MAINT:修复arraytypes.c.src中的C ++注释。
- #7681:DOC:更新1.11.1发行说明。
- #7686:ENH:将FFT缓存更改为有界LRU缓存
- #7688:DOC:修复损坏的genfromtxt示例在用户指南。关闭gh-7662。
- #7689:BENCH:添加correlate / convolve基准。
- #7696:DOC:更新轮制作/上传说明
- #7699:BLD:保存库顺序
- #7704:ENH:将位属性添加到np.finfo
- #7712:BUG:使用新的FFT缓存修复竞争条件
- #7715:BUG:删除np.place中的内存泄漏
- #7719:BUG:修复np.random.shuffle中不同...的数组的segfault
- #7723:将mkl_info.dir_env_var从MKL更改为MKLROOT
- #7727:DOC:Datetime中的更正单位array.datetime.rst
- #7729:DOC:fix typo in savetxt docstring(closing#7620)
- #7733:更新7525,DOC:Fix order ='A'np.array的文档。
- #7734:更新7542,ENH:将polyrootval添加到numpy.polynomial
- #7735:BUG:修复在OS X与Python 3.x的问题,其中npymath.ini是...
- #7739:DOC:提及发行说明中#6430的更改。
- #7740:DOC:添加对poisson rng的引用
- #7743:更新7476,DEP:不推荐使用数字类型类型代码,关闭#2148
- #7744:DOC:从ufuncs列表中删除“ones_like”(不是)
- #7746:DOC:澄清rcond在numpy.linalg.lstsq中的效果。
- #7747:更新7672,BUG:确保我们不除以零
- #7748:DOC:更新doc32中的float32平均值示例
- #7754:更新7612,ENH:添加broadcast.ndim以在其他地方匹配代码。
- #7757:更新7175,BUG:无效读取大小为4的PyArray_FromFile
- #7759:BUG:修复numpy.i对numpy API的支持
- #7760:ENH:make assert_almost_equal&assert_array_almost_equal一致。
- #7766:修正英文拼写错误
- #7771:DOC:从日志空间链接geomspace
- #7773:DOC:删除冗余
- #7777:DOC:更新Numpy 1.11.1发行说明。
- #7785:DOC:更新车轮制造程序以进行发布
- #7789:MRG:在Windows上添加64位轮盘
- #7791:f2py.compile问题(#7683)
- #7799:“lambda”不允许在示例中用作关键字参数...
- #7803:BUG:将'c'PEP3118 / struct类型解释为'S1'。
- #7807:DOC:公式中错位的括号
- #7817:BUG:确保npy_mul_with_overflow_
检测到溢出。 - #7818:numpy / distutils / misc_util.py修复#7809:检查_tmpdirs ...
- #7820:MAINT:为空数组分配较少的字节。
- #7823:BUG:固定掩码数组行为的标量输入np.ma.atleast_ * d
- #7834:DOC:添加了一个示例
- #7839:Pypy修复
- #7840:修复ATLAS版本检测
- #7842:修正版本已添加的代码
- #7848:MAINT:修复已弃用的Python imp模块的剩余使用。
- #7853:BUG:确保numpy全局变量在重新加载后保持身份。
- #7863:ENH:将快速排序转换为introsort
- #7866:文档runtests extra argv
- #7871:BUG:正确处理introsort深度限制
- #7879:DOC:fix typo in loadtxt(closing#7878)
- #7885: Handle NetBSD specific
- #7889:DOC:#7881。修复链接以记录数组
- #7894:fixup-7790,BUG:从np.array构建ma.array,其中包含...
- #7898:拼写和语法修复。
- #7903:BUG:修复float16类型,由于排序错误而未被调用
- #7908:BLD:固定检测最近的MKL版本
- #7911:BUG:修复问题#7835(ma.median of 1d)
- #7912:ENH:跳过或避免gc / objectmodel差异btwn pypy和cpython
- #7918:ENH:allow numpy.apply_along_axis()使用ndarray子类
- #7922:ENH:为#6458添加ma.convolve和ma.correlate
- #7925:Monkey-patch _msvccompile.gen_lib_option像任何其他编译器
- #7931:BUG:检查npy_math_complex中的HAVE_LDOUBLE_DOUBLE_DOUBLE_LE。
- #7936:ENH:改进鸭子在iscomplexobj里面打字
- #7937:BUG:防止通用快速排序中的错误比较。
- #7938:DOC:将cbrt添加到数学摘要页面
- #7941:BUG:确保numpy全局变量在重新加载后保持身份。
- #7943:DOC:#7927。删除与Python相关的memmap的已弃用的注释...
- #7952:BUG:使用关键字参数初始化扩展基类。
- #7956:BLD:从setup.py结尾处的内置文件中删除__NUMPY_SETUP__
- #7963:BUG:MSVCCompiler以指数方式增长“lib”和“include”env字符串。
- #7965:BUG:使用后无法修改元组
- #7976:DOC:固定的文档维度的返回值
- #7977:DOC:创建1.11.2发行说明。
- #7979 t>:DOC:在add _(installed_)库中更正了允许的关键字
- #7980:ENH:添加运行时的能力选择ufunc循环,添加AVX2整数...
- #7985:Rebase 7763,ENH:添加新的警告抑制/过滤上下文
- #7987:DOC:另请参见np.load和np.memmap在np.lib.format.open_memmap中
- #7988:DOC:在文档中包含cbrt,间距和工厂的docstring
- #7999:ENH:向快速ufunc循环宏添加inplace个案
- #8006:DOC:更新1.11.2发行说明。
- #8008:MAINT:删除剩余imp模块导入。
- #8009:DOC:修正了c-info.ufunc-tutorial中的三个错别字
- #8011:DOC:更新1.11.2发行说明。
- #8014:BUG:修复fid.close()以使用os.close(fid)
- #8016:BUG:修复numpy.ma.median。
- #8018:BUG:如果keepdims为True,轴修正np.ma.count的返回值
- #8021:DOC:将Numpy的所有非代码实例更改为NumPy
- #8027:ENH:将平台独立的lib目录添加到PYTHONPATH
- #8028:DOC:更新1.11.2发行说明。
- #8030:BUG:fix np.ma.median with only one non-masked value and a axis ...
- #8038:MAINT:更新rollaxis中的错误消息。
- #8040:更新add_newdocs.py
- #8042:BUG:core:修复NpyIter缓冲中的不连续数组
- #8045:DOC:更新1.11.2发行说明。
- #8050:remove refcount语义,现在a.resize()几乎总是需要...
- #8051:清除信号NaN异常
- #8054:ENH:向量化向量化添加签名参数...
- #8057:BUG:lib:简化(并修复)pad对pad_width的处理
- #8061:BUG:financial.pmt修改输入(问题#8055)
- #8064:MAINT:将。PMIP文件添加到.gitignore
- #8065:BUG:断言fromfile结束早于pyx_processing
- #8066:BUG,TST:在Travis脚本中修复python3-dbg错误
- #8071:MAINT:添加Tempita到randint助手
- #8075:DOC:修正nan_to_num中isinf的描述
- #8080:BUG:非整数可以在dtype偏移量中结束
- #8081:将过期的网址更新为nose.readthedocs.io
- #8083:ENH:运行时/整数除法的弃用警告...
- #8084:DOC:修复np.roots的错误返回类型说明。
- #8087:BUG:financial.pmt修改输入#8055
- #8088:MAINT:删除重复的randint助手代码。
- #8093:MAINT:在用作上下文管理器时修复assert_raises_regex
- #8096:ENH:Vendorize tempita。
- #8098:DOC:增强np.linalg.eig * h的描述/用法
- #8103:Pypy修复
- #8104:修复cpuinfo主函数的测试代码
- #8107:BUG:以precision = 0修复数组打印。
- #8109:修复了大索引的ravel_multi_index中的错误(问题#7546)
- #8110:BUG:distutils:在fcompiler / gnu.py中修复rpath的问题
- #8111:ENH:为发布作者和公关添加工具。
- #8112:DOC:修复“另请参阅”linalg中的链接。
- #8114:BUG:core:在PyLong_AsSsize_t后添加缺少错误检查
- #8121:DOC:改进histogram2d()示例。
- #8122:BUG:当dtype是对象时修复MaskedArray中的破碎pickle(返回...
- #8124:BUG:修正构建中断
- #8125:Rebase,BUG:固定F阶对象数组的deepcopy。
- #8127:BUG:整数到负整数权力应该出错。
- #8141:改进对损坏的系统的配置检查
- #8142:BUG:np.ma.mean and var should return scalar if no mask
- #8148:BUG:在npy_load_module中导入完整模块路径
- #8153:MAINT:在python中公开void标量“base”属性
- #8156:DOC:添加了一个标量为空索引的示例,#8138
- #8160:BUG:fix _array2string的结构化数组(问题#5692)
- #8164:MAINT:更新NumPy 1.12.0的邮件映射
- #8165:Fixup 8152,BUG:assert_allclose(...,equal_nan = False)不...
- #8167:Fixup 8146,DOC:Clarify when PyArray_ {Max,Min,Ptp} return ...
- #8168:DOC:genfromtxt()docstring中的小写拼写修复。
- #8173:BLD:在AIX上启用构建
- #8174:DOC:警告dtype.descr仅用于PEP3118
- #8177:MAINT:添加python 3.6支持suppress_warnings
- #8178:MAINT:在Python 3.6中修复ResourceWarning new。
- #8180:FIX:protect stolen ref by PyArray_NewFromDescr in array_empty
- #8181:ENH:改进宣告找到github squash-merge提交。
- #8182:MAINT:更新.mailmap
- #8183:MAINT:Ediff1d性能
- #8184:MAINT:在` nan 1.s match 1.12之前执行 assert_allclose
- #8188:DOC:'highest'是randint()
- #8189:BUG:如果arr不可写,setfield应该引发
- #8190:ENH:添加一个float_power函数,其精度至少为float64。
- #8197:DOC:向np.ufunc.outer添加缺少的参数
- #8198:DEP:不再使用keepdims参数进行累加
- #8199:MAINT:将路径更改为enut in distutils.system_info。关闭gh-8195。
- #8200:BUG:修复结构化数组格式函数
- #8202:ENH:通过解释器专门化dev软件包的名称
- #8205:DOC:将开发说明从SSH更改为HTTPS访问。
- #8216:DOC:补丁文档错误atleast_nd和frombuffer
- #8218:BUG:ediff1d应返回子类
- #8219:DOC:将SciPy引用转换为链接。
- #8222:ENH:Make numpy.mean()做更精确的计算
- #8227:BUG:更好地检查np.random.uniform中的无效边界。
- #8231:ENH:Refactor numpy **运算符numpy标量整数幂
- #8234:DOC:在numpy.asarray中复制时进行澄清
- #8236:DOC:修复文档拉取请求。
- #8238:MAINT:更新pavement.py
- #8239:ENH:改进通知工具。
- #8240:REL:准备1.12.x分支
- #8243:BUG:更新运算符**测试新行为。
- #8246:REL:为1.12版本的RELAXED_STRIDE_CHECKING重置步幅。
- #8265:BUG:np.piecewise不工作的标量
- #8272:TST:路径测试应该在比较时解析符号链接
- #8282:DOC:更新1.12.0发行说明。
- #8286:BUG:修复pavement.py write_release_task。
- #8296:BUG:修复mapiter_ @ name @中反转子空间的迭代。
- #8304:BUG:修复PyUFunc_GenericReduction中的PyPy崩溃。
- #8319:BLD:blacklist powl(longdouble power function)。
- #8320:BUG:如果找到OpenBLAS,MKL或BLIS,请勿链接到Accelerate。
- #8322:BUG:参数的固定类型规范
- #8336:BUG:修正packbits和unpackbits以正确处理空数组
- #8338:BUG:修复在python 3中间歇性失败的test_api测试
- #8339:BUG:修正ndarray.tofile附加模式下大文件损坏。
- #8359:BUG:为Python 3.6修复suppress_warnings(再次)。
- #8372:BUG:修正ma.median和nanpercentile。
- #8373:BUG:正确的大写字母大小写
- #8379:DOC:更新1.12.0-notes.rst。
- #8390:ENH:retune apply_along_axis nanmedian cutoff 1.12
- #8391:DEP:修复Python 3.6中已弃用的转义字符串字符。
- #8394:DOC:创建1.11.3发行说明。
- #8399:BUG:在announce.py中修正作者搜索
- #8402:DOC,MAINT:更新1.12.0注释和mailmap。
- #8418:BUG:修复1.12的ma.median偶数元素
- #8424:DOC:修复工具和发行说明更符合markdown。
- #8427:BUG:为assert_equal和其他测试函数添加一个锁
- #8431:BUG:修复当func1d()返回一个非ndarray时的apply_along_axis()。
- #8432:BUG:让linspace接受具有array_interface的输入。
- #8437:TST:在Python最终发布之后将3.6-dev测试更新到3.6。
- #8439:DOC:更新1.12.0发行说明。
- #8466:MAINT:更新邮件映射条目。
- #8467:DOC:back-port gh-8464缺少的部分。
- #8476:DOC:更新1.12.0发行说明。
- #8477:DOC:更新1.12.0发行说明。
NumPy 1.11.3 Release Notes¶
Numpy 1.11.3修复了在ndarray.tofile中使用以附加模式打开的非常大的文件时导致文件损坏的错误。它支持Python 2.6 - 2.7和3.2 - 3.5。Linux,Windows和OS X的车轮可以在PyPI上找到。
Pull Requests Merged¶
Numpy 1.11.2支持Python 2.6 - 2.7和3.2 - 3.5。它修复了在Numpy 1.11.1中发现的错误和回归,并包括几个构建相关的改进。Linux,Windows和OS X的车轮可以在PyPI上找到。
Pull Requests Merged¶
省略了以后合并和发行说明更新覆盖的修订。
- #7736 BUG:许多功能默默地丢弃'keepdims'kwarg。
- #7738 ENH:添加额外的kwargs并更新许多MA方法的doc。
- #7778 DOC:更新Numpy 1.11.1发行说明。
- #7793 BUG:MaskedArray.count不正确处理负轴。
- #7816 BUG:修复数组太大的错误为宽dtypes。
- #7821 BUG:确保npy_mul_with_overflow_
检测到溢出。 - #7824 MAINT:为空数组分配较少的字节。
- #7847 MAINT,DOC:修复一些imp模块使用并更新f2py.compile docstring。
- #7849 MAINT:修复已弃用的Python imp模块的剩余使用。
- #7851 BLD:修复ATLAS版本检测。
- #7896 BUG:从包含padding的np.array构造ma.array。
- #7904 BUG:修复float16类型,由于排序错误而未被调用。
- #7917 BUG:numpy的生产安装不应该需要鼻子。
- #7919 BLD:修复此库最近版本的MKL检测。
- #7920 BUG:修复问题#7835(ma.median of 1d)。
- #7932 BUG:Monkey-patch _msvccompile.gen_lib_option like other compilers。
- #7939 BUG:检查npy_math_complex中的HAVE_LDOUBLE_DOUBLE_DOUBLE_LE。
- #7953 BUG:防止通用快速排序中的错误比较。
- #7954 BUG:使用关键字参数初始化扩展基类。
- #7955 BUG:确保numpy全局变量在重新加载后保持身份。
- #7972 BUG:MSVCCompiler以指数方式增长“lib”和“include”env字符串。
- #8005 BLD:在setup.py结束时从内置中删除__NUMPY_SETUP__。
- #8010 MAINT:删除剩余imp模块导入。
- #8020 BUG:修复np.ma.count的返回值,如果keepdims为True,axis为None。
- #8024 BUG:修复numpy.ma.median。
- #8031 BUG:修正np.ma.median,只有一个非屏蔽值。
- #8044 BUG:修复NeptIter缓冲中有不连续数组的错误。
Numpy 1.11.1支持Python 2.6 - 2.7和3.2 - 3.5。它修复了在Numpy 1.11.0中发现的错误和回归,并包括几个构建相关的改进。Linux,Windows和OSX的轮可以在pypi上找到。
Fixes Merged¶
- #7506 BUG:当鼻子不可用时,确保numpy在python 2.6上导入。
- #7530 BUG:np.lexsort中带有无效轴的浮动异常。
- #7535 BUG:将glibc complex trig functions blacklist扩展为glibc
- #7551 BUG:允许没有编译器的正常恢复。
- #7558 BUG:常量填充期望错误类型在constant_values。
- #7578 BUG:修复Python 3.x中的OverflowError。在swig界面。
- #7590 BLD:修复configparser.InterpolationSyntaxError。
- #7597 BUG:使np.ma.take在标量上工作。
- #7608 BUG:linalg.norm():不要将对象数组转换为float。
- #7638 BLD:在system_info.py中更正C编译器定制。
- #7654 BUG:masmedian of 1d数组应该返回一个标量。
- #7656 BLD:删除硬编码英特尔编译器标志-xSSE4.2。
- #7660 BUG:对象字段类型的str(mvoid)的临时修订。
- #7665 BUG:修复1D屏蔽数组的不正确打印。
- #7670 BUG:在直方图中更正初始索引估计。
- #7671 BUG:布尔分配没有GIL释放时传输需要API。
- #7676 BUG:修正最终直方图bin右边缘的处理。
- #7680 BUG:Fix np.clip bug Visual Studio 2015的NaN处理。
- #7724 BUG:修复np.random.shuffle中的segfaults。
- #7731 MAINT:将mkl_info.dir_env_var从MKL更改为MKLROOT。
- #7737 BUG:修复了在OS X上使用Python 3.x,npymath.ini未安装的问题。
此版本支持Python 2.6 - 2.7和3.2 - 3.5,并包含一些增强和改进。还请注意下面列出的构建系统更改,因为它们可能具有细微的效果。
由于工具链损坏,此版本没有提供Windows(TM)二进制文件。Windows(TM)Python包的提供者之一是你的最好的选择。
Highlights¶
这些改进的细节可以在下面找到。
- datetime64类型现在是时区naive。
- dtype参数已添加到
randint。 - 改进了两个数组可能共享内存的检测。
np.histogram的自动bin大小估计。- A @ A.T和点(A,A.T)的速度优化。
- 用于重组数轴的新功能
np.moveaxis。
Build System Changes¶
- Numpy现在使用
setuptools来构建它,而不是普通的distutils。这修复了在依赖于Numpy的项目文件(见gh-6551)的setup.py文件中使用install_requires='numpy'。它可能影响Numpy本身的构建/安装方法的方式。请报告Numpy问题跟踪器上的任何意外行为。 - Bento构建支持和相关文件已删除。
- 单文件构建支持和相关文件已删除。
Future Changes¶
以下是Numpy 1.12.0的更改。
- 支持Python 2.6,3.2和3.3将被删除。
- 轻松的步幅检查将成为默认值。有关此更改暗示的更广泛讨论,请参阅1.8.0发行说明。
- datetime64“不是时间”(NaT)值的行为将被改变以匹配浮点“不是数字”(NaN)值:涉及NaT的所有比较将返回False,除了NaT!= NaT,它将返回真正。
- 使用浮点索引将引发IndexError,例如a [0,0.0]。
- 使用非整数array_like的索引将产生
IndexError,例如a ['1', '2'] - 使用多个省略号进行索引会产生
IndexError,例如a [..., ...]。 - 用作索引值的非整数将引起
TypeError,例如在reshape,take中指定reduce轴。
在未来的版本中将进行以下更改。
- 在
numpy.testing中公开的rand函数将被删除。该函数从早期的Numpy留下,并使用Python随机模块实现。应使用numpy.random的随机数生成器。 ndarray.view方法将只允许使用不同大小的dtype来查看c_contiguous数组,导致最后一个维度更改。这与当前行为(其中f_contiguous但不是c_contiguous)可以被视为不同大小的dtype类型(导致第一维更改)不同。- 切割
MaskedArray将返回数据和掩码的视图。当前,掩码是写时复制,并且对切片中的掩码的改变不传播到原始掩码。有关详细信息,请参阅下面的FutureWarnings部分。
Compatibility notes¶
datetime64 changes¶
在以前版本的NumPy实验datetime64类型总是存储时间以UTC。默认情况下,从字符串创建datetime64对象或打印datetime64对象将从或转换为本地时间:
# old behavior
>>>> np.datetime64('2000-01-01T00:00:00')
numpy.datetime64('2000-01-01T00:00:00-0800') # note the timezone offset -08:00
datetime64用户的一致认为,这种行为是不可取的,并且与datetime64通常使用(例如,通过pandas)不一致。对于大多数使用情况,首选的时区naive datetime类型,类似于Python标准库中的datetime.datetime类型。因此,datetime64不再假设输入在本地时间,也不打印本地时间:
>>>> np.datetime64('2000-01-01T00:00:00')
numpy.datetime64('2000-01-01T00:00:00')
为了向后兼容,datetime64仍然解析时区偏移,它通过转换为UTC来处理。但是,生成的datetime是时区naive:
>>> np.datetime64('2000-01-01T00:00:00-08')
DeprecationWarning: parsing timezone aware datetimes is deprecated;
this will raise an error in the future
numpy.datetime64('2000-01-01T08:00:00')
作为此更改的推论,我们不再禁止在数据时间之间使用日期单位和数据时间与时间单位进行投射。使用时区天真数据时,从日期到时间的转换规则不再含糊不清。
linalg.norm return type changes¶
linalg.norm函数的返回类型现在是无异常的浮点。一些规范类型先前返回了整数。
polynomial fit changes¶
numpy多项式包中的各种拟合函数不再接受度数指定的非整数。
np.dot now raises TypeError instead of ValueError¶
此行为模拟其他函数的行为,例如np.inner。如果两个参数不能转换为公共类型,则可能会根据它们的顺序产生TypeError或ValueError。现在,np.dot现在总是提出TypeError。
FutureWarning to changed behavior¶
- 在
np.lib.split中,无论要拆分的数组的大小如何,结果中的空数组始终具有维(0,)。这已更改,以便保留尺寸。从Numpy 1.9开始,此变更的FutureWarning已经到位,但是由于错误,有时没有提出警告,维度已经保留。
% and // operators¶
这些运算符分别使用remainder和floor_divide函数实现。这些函数现在基于fmod,并且一起计算,以便彼此兼容以及与浮点类型的Python版本兼容。与以前的结果相比,结果应该略微更准确或彻底修正错误,但是在舍入使由floor_divide返回的整数有差异的情况下,结果可能会有很大不同。Some corner cases also change, for instance, NaN is always returned for both functions when the divisor is zero, divmod(1.0, inf) returns (0.0, 1.0) except on MSVC 2008, and divmod(-1.0, inf) returns (-1.0, inf).
C API¶
删除PyUFuncObject结构的check_return和inner_loop_selector成员(用reserved插槽替换它们以保留结构布局)。这些从来没有用于任何东西,所以不可能有任何第三方代码使用它们,但我们在这里提到它的完整性。
object dtype detection for old-style classes¶
在python 2中,作为旧式用户定义类的实例的对象不再自动在dtype-detection处理程序中被计为“object”类型。相反,如在python 3中,它们可能潜在地计数为序列,但是只有当它们定义了__ len __和__ getitem __方法时。这修复了python 2和3之间的segfault和不一致。
New Features¶
np.histogram现在提供插件估计器,用于自动估计最佳箱数。将['auto','fd','scott','rice','sturges']之一作为参数传递给“bins”会导致使用相应的估计器。添加了使用Airspeed Velocity的基准套件,转换了之前基于vbench的套件。您可以通过
python runtests.py - bench在本地运行套件。有关详细信息,请参见benchmarks/README.rst。添加了可以精确检查两个数组是否具有内存重叠的新函数
np.shares_memory。np.may_share_memory现在还可以选择花更多的精力来减少误报。SkipTest和KnownFailureException异常类在numpy.testing命名空间中公开。在测试功能中提高它们,以标记要跳过的测试或将其标记为已知故障。f2py.compile有一个新的extension关键字参数,允许为生成的临时文件指定fortran扩展名。例如,文件可以指定为*.f90。verbose参数也被激活,以前被忽略。已将
dtype参数添加到np.random.randint现在可以生成以下类型的随机ndarrays:np.bool,np.int8,np.uint8,np.int16,np.uint16,np.int32,np.uint32,np.int64,np.uint64,np.int _ ``, ``np.intp
规格是精确的,而不是C型。因此,在某些平台上
np.int64可能是long而不是长 长 t4 >即使指定的dtype为结果类型取决于给定精度使用的C类型numpy。字节序规范也被忽略,生成的数组总是以本地字节顺序。long long,因为两者可能具有相同的精度。新的
np.moveaxis功能允许通过显式提供源轴和目标轴将一个或多个数轴移动到新位置。此功能应比当前rollaxis功能更易于使用,并提供更多功能。各种
numpy.polynomial拟合的deg参数已经扩展为接受要包括在拟合中的项的度数的列表,所有其他项的系数被约束为零。该变化是向后兼容的,传递标量deg会像前面一样工作。一个用于在Python版本添加到npy_math库之后建模的浮点类型的divmod函数。
Improvements¶
np.gradient now supports an axis argument¶
为了一致性,将axis参数添加到np.gradient。它允许指定计算梯度的轴。
np.lexsort now supports arrays with object data-type¶
当类型不实现合并排序类型的argsort方法时,函数现在内部调用泛型npy_amergesort。
np.ma.core.MaskedArray now supports an order argument¶
当构建新的MaskedArray实例时,可以使用类似于调用np.ndarray时的order参数进行配置。The addition of this argument allows for the proper processing of an order argument in several MaskedArray-related utility functions such as np.ma.core.array and np.ma.core.asarray.
Memory and speed improvements for masked arrays¶
使用mask=True创建一个蒙版数组mask=False)现在使用np.onesnp.zeros)创建掩码,这更快,并避免大的内存峰值。另一个优化是为了避免打印掩码数组时的内存峰值和无用的计算。
ndarray.tofile now uses fallocate on linux¶
该函数现在使用fallocate系统调用在支持它的文件系统上预留足够的磁盘空间。
Optimizations for operations of the form A.T @ A and A @ A.T¶
之前,gemm BLAS操作用于所有矩阵产品。现在,如果矩阵乘积在矩阵和其转置之间,它将使用syrk BLAS运算来提高性能。此优化已扩展到@,numpy.dot,numpy.inner和numpy.matmul。
注意:需要转置和非转置矩阵来共享数据。
np.testing.assert_warns can now be used as a context manager¶
这符合assert_raises的行为。
Speed improvement for np.random.shuffle¶
np.random.shuffle现在对于1d ndarrays更快。
Changes¶
Pyrex support was removed from numpy.distutils¶
方法build_src.generate_a_pyrex_source将保持可用;它已经被用户支持Cython而不是Pyrex。建议切换到一个更好的支持的构建Cython扩展的方法。
np.broadcast can now be called with a single argument¶
在这种情况下,生成的对象将简单地模拟单个数组的迭代。此更改取消了区分
- if len(x)== 1:
- shape = x [0] .shape
- 其他:
- shape = np.broadcast(* x).shape
而是可以在所有情况下使用np.broadcast。
np.trace now respects array subclasses¶
这种行为模仿诸如np.diagonal等其他函数的行为,并且确保例如对于掩蔽的数组np.trace(ma)和ma.trace()给出相同的结果。
np.dot now raises TypeError instead of ValueError¶
此行为模拟其他函数的行为,例如np.inner。如果两个参数不能转换为公共类型,则可能会根据它们的顺序产生TypeError或ValueError。现在,np.dot现在总是提出TypeError。
linalg.norm return type changes¶
linalg.norm函数现在以浮点形式执行其所有计算,并返回浮动结果。此更改修复了由于整数溢出和具有最小值的有符号整数(例如,int8(-128))的abs失败所导致的错误。对于一致性,即使在整数可能工作的情况下也使用浮点。
Deprecations¶
Views of arrays in Fortran order¶
F_CONTIGUOUS标志用于表示使用改变元素大小的dtype将改变第一个索引的视图。这对于数组(F_CONTIGUOUS和C_CONTIGUOUS)总是有问题的,因为C_CONTIGUOUS优先。轻松的步幅检查导致更多的这种双连续数组,并打破一些现有的代码作为结果。注意,这也影响通过分配数组的dtype属性来更改dtype。此弃用的目的是在将来某个时间将视图限制为C_CONTIGUOUS数组。有关向后兼容的工作是使用a.T.view(...).T。还可以将一个参数添加到视图方法中以显式地请求Fortran顺序视图,但不会向后兼容。
Invalid arguments for array ordering¶
目前可以在array.flatten或array.ravel的方法中传递order参数的参数,这些参数不是下列参数之一:'C','F','A','K'(注意所有这些可能的值都是unicode和不区分大小写)。在将来的版本中不允许这样的行为。
Random number generator in the testing namespace¶
Python标准库随机数生成器以前在testing命名空间中显示为testing.rand。不建议使用此生成器,它将在以后的版本中删除。使用numpy.random命名空间中的生成器。
Random integer generation on a closed interval¶
In accordance with the Python C API, which gives preference to the half-open interval over the closed one, np.random.random_integers is being deprecated in favor of calling np.random.randint, which has been enhanced with the dtype parameter as described under “New Features”. 但是,np.random.random_integers不会很快删除。
FutureWarnings¶
Assigning to slices/views of MaskedArray¶
当前,被掩蔽的数组的切片包含原始数据的视图和掩模的写时拷贝视图。因此,对片的掩码的任何改变将导致产生原始掩码的副本,并且改变新掩码而不是原始掩码。例如,如果我们对原始片段进行切片,那么查看 = original [:]对一个数组中的数据的修改将影响另一个数据的数据,但是因为掩码将在赋值操作期间被复制,所以掩码的改变将保持局部。类似的情况发生在使用MaskedArray(data, t> mask)显式构造屏蔽数组时,返回的数组将包含data,但掩码将是mask的写入时复制视图。
在将来,这些情况将被规范化,使得数据和掩码数组被以相同的方式对待,并且对它们的修改将在视图之间传播。在1.11中,每当用户代码修改视图的掩码时,numpy将发出MaskedArrayFutureWarning警告,以后可能会导致值传播回原来的值。为了使这些警告沉默,并使你的代码对即将到来的更改具有鲁棒性,你有两个选择:如果你想保持当前行为,在修改掩码之前调用masked_view.unshare_mask()。如果您想早日获得未来行为,请使用masked_view._sharedmask = False。但是,请注意,设置_sharedmask属性会中断以下显式调用masked_view.unshare_mask()。
NumPy 1.10.4 Release Notes¶
这个版本是由segfault回归驱动的bugfix源版本。没有为此版本提供Windows二进制文件,因为我们用来生成这些文件的工具链中似乎存在错误。希望这个问题将在下一个版本中修复。在此期间,我们建议使用Windows二进制文件的提供程序之一。
Compatibility notes¶
- 跟踪函数现在调用ndarray的子类的trace方法,除了矩阵,当前的行为被保留。这是为了帮助AstroPy的单位包,并希望不会导致问题。
Issues Fixed¶
- gh-6922 BUG:numpy.recarray.sort segfaults在Windows上。
- gh-6937 BUG:busday_offset做了错误的事情与modifiedpreceding滚动。
- gh-6949 BUG:当切分recarray的子类时,类型丢失。
Merged PRs¶
以下PR已合并到1.10.4中。当PR是反向端口时,将列出原始PR对主机的PR编号。
- gh-6840 TST:更新1.10.x中的travis测试脚本
- gh-6843 BUG:修复在test_f2py中只使用python 3的FileNotFoundError。
- gh-6884 REL:更新pavement.py和setup.py以反映当前版本。
- gh-6916 BUG:修复test_f2py,使它在runtests.py中正确运行。
- gh-6924 BUG:Fix segfault gh-6922。
- gh-6942修复datetime roll ='modifiedpreceding'错误。
- gh-6943 DOC,BUG:修复一些胶乳一代的问题。
- gh-6950 BUG跟踪不是子类感知,np.trace(ma)!= ma.trace()。
- gh-6952 BUG recarray切片应保留子类。
N / A这个版本没有发生,由于各种螺丝涉及PyPi。
这个版本处理了在1.10.1中出现的许多错误,并添加了各种构建和发布改进。
Numpy 1.10.1支持Python 2.6 - 2.7和3.2 - 3.5。
Compatibility notes¶
Relaxed stride checking is no longer the default¶
有后面的兼容性问题涉及视图改变需要在更长的时间范围内处理的多维Fortran数组的dtype。
Fix swig bug in numpy.i¶
轻松的步幅检查揭示了array_is_fortran(a)中的一个错误,它使用PyArray_ISFORTRAN检查Fortran连续性而不是PyArray_IS_F_CONTIGUOUS。你可能想使用更新的numpy.i重新生成swigged文件
Deprecate views changing dimensions in fortran order¶
如果一个新的描述符导致一个非C连续数组的dtype属性改变形状,这将不建议这样做。这有效地阻止了使用改变沿第一轴的元素尺寸的dtype来观察多维Fortran数组。
弃用的原因是,当启用了松弛步长检查时,C和Fortran连续的数组总是被视为C连续的,它破坏了一些代码,这两个代码相互排斥为ndim> 1的非标量数组。此弃用准备了始终启用宽松步幅检查的方法。
Issues Fixed¶
- gh-6019对于具有多维列的结构化数组,蒙版数组repr失败。
- gh-6462空数组的中位数产生IndexError。
- gh-6467用于记录数组访问的性能回归。
- gh-6468 numpy.interp使用'left'值,即使x [0] == xp [0]。
- gh-6475当其中一个参数是memmap时,np.allclose返回一个memmap。
- gh-6491广播stride_tricks数组时出错。
- gh-6495 gfortran中无法识别的命令行选项'-ffpe-summary'。
- gh-6497对recarrays执行reduce操作失败。
- gh-6498在1.10发行说明中提及默认转换规则的更改。
- gh-6530空输入上的分区函数错误。
- gh-6532 numpy.inner有时返回错误的不准确的值。
- gh-6563意图(出)破碎在f2py的最新版本。
- gh-6569无法运行测试'python setup.py build_ext -i'
- gh-6572广播stride_tricks数组组件时出错。
- gh-6575 BUG:拆分产生空数组,其维数不正确
- gh-6590 Fortran数组问题1.10。
- gh-6602随机__all__缺少选择和dirichlet。
- gh-6611 ma.dot不再总是返回1.10中的屏蔽数组。
- gh-6618在numpy.i中的make_fortran()中的NPY_FORTRANORDER
- gh-6636 numpy.recarray中嵌套类型的内存泄漏
- gh-6641字段的子集重新排序生成结构化数组。
- gh-6667 ma.make_mask处理ma.nomask输入不正确。
- gh-6675优化blas检测在主和1.10。
- gh-6678获取意外错误:X.dtype = complex(或Y = X.view(complex))
- gh-6718 f2py测试失败在pip安装numpy-1.10.1在virtualenv。
- gh-6719编译Cython文件时出错:不允许没有gil的分裂分裂。
- gh-6771 Numpy.rec.fromarrays丢失版本1.9.2和1.10.1之间的dtype元数据
- gh-6781维护/1.10.x中的travis-ci脚本需要修复。
- gh-6807 1.10.2的Windows测试错误
Merged PRs¶
以下PR已合并到1.10.2中。当PR是反向端口时,将列出原始PR对主机的PR编号。
- gh-5773 MAINT:当使用它们与pytest时,隐藏测试助手tracebacks。
- gh-6094 BUG:修复了掩码结构化数组的字符串表示形式的错误。
- gh-6208 MAINT:通过删除不必要的安全检查来加速字段访问。
- gh-6460 BUG:通过较小侵入性程序替换os.environ.clear。
- gh-6470 BUG:修复numpy distutils中的AttributeError。
- gh-6472 MAINT:使用Python 3.5而不是3.5-dev进行travis 3.5测试。
- gh-6474 REL:更新sdist和自动切换测试警告的Paver脚本。
- gh-6478 BUG:修复OS X构建的英特尔编译器标志。
- gh-6481 MAINT:现在支持带有空格的LIBPATH Python 2.7+和Win32。
- gh-6487 BUG:允许在f2py中数组的定义中嵌套使用参数。
- gh-6488 BUG:扩展公共块,而不是覆盖在f2py。
- gh-6499 DOC:提及inplace操作的默认转换已更改。
- gh-6500 BUG:作为子阵列查看的重新查询不会转换为np.record类型。
- gh-6501 REL:为构建的文档添加“make upload”命令,更新“make dist”。
- gh-6526 BUG:修复在setup.py中使用__doc__的-OO模式。
- gh-6527 BUG:修正空数组的中位数时的IndexError。
- gh-6537 BUG:make ma.atleast_ * with scalar argument return数组。
- gh-6538 BUG:修复ma.masked_values不收缩掩码如果要求。
- gh-6546 BUG:修正非连续数组的内积回归。
- gh-6553 BUG:修复空输入的分区和argpartition错误。
- gh-6556 BUG:在使用as_strided数组的broadcast_arrays中出错。
- gh-6558 MAINT:轻微更新为“make upload”doc构建命令。
- gh-6562 BUG:在recarray中禁用视图安全检查。
- gh-6567 BUG:恢复一些导入*修复在f2py。
- gh-6574 DOC:Numpy 1.10.2的发行说明。
- gh-6577 BUG:修复#6569,允许build_ext -inplace
- gh-6579 MAINT:修复文档上传规则中的错误。
- gh-6596 BUG:固定训练,用于放松步伐检查。
- gh-6606 DOC:更新1.10.2发行说明。
- gh-6614 BUG:添加选择和dirichlet到numpy.random .__ all__。
- gh-6621 BUG:修正swig make_fortran函数。
- gh-6628 BUG:Make allclose return python bool。
- gh-6642 BUG:在_convert_from_dict中修复memleak。
- gh-6643 ENH:make recarray.getitem return a recarray。
- gh-6653 BUG:修复ma dot,总是返回masked数组。
- gh-6668 BUG:ma.make_mask应该总是返回nomask为nomask参数。
- gh-6686 BUG:修复assert_string_equal中的错误。
- gh-6695 BUG:修复删除在构建期间创建的tempdir。
- gh-6697 MAINT:修复PyArray_FROM_OT的宏定义中的虚假分号。
- gh-6698 TST:test np.print大整数的错误。
- gh-6717 BUG:Readd fallback CBLAS检测linux。
- gh-6721 BUG:修正为#6719。
- gh-6726 BUG:修复由松弛步幅回滚暴露的bug。
- gh-6757 BUG:如果检测到cblas,则链接cblas库。
- gh-6756 TST:只测试f2py,不是f2py2.7等,修复#6718。
- gh-6747 DEP:不再使用通过描述更改非C连续数组的形状。
- gh-6775 MAINT:包括从__future__样板文件中丢失它的一些文件。
- gh-6780 BUG:元数据不会复制到base_dtype。
- gh-6783 BUG:修复travis ci测试新的google基础设施。
- gh-6785 BUG:interp的快速和脏的修复。
- gh-6813 TST,BUG:使test_mvoid_multidim_print适用于32位系统。
- gh-6817 BUG:禁用32位msvc9编译器优化npy_rint。
- gh-6819 TST:在Windows 2.x的Python 2.x上修复test_mvoid_multidim_print故障。
初始支持mingwpy被还原,因为它导致非Windows构建的问题。
- gh-6536 BUG:恢复gh-5614修复非Windows构建问题
np.lib.split的修复被还原,因为它导致“修复”行为将出现在Numpy 1.11,这已经存在于Numpy 1.9。有关这一问题的讨论,请参阅gh-6575。
轻松的步幅检查恢复。有后面的兼容性问题涉及视图改变需要在更长的时间范围内处理的多维Fortran数组的dtype。
- gh-6735 MAINT:不检查1.10的默认值。
Notes¶
Numpy 1.10.1版本中的错误导致在项目中依赖于Numpy的RuntimeWarning和DeprecationWarning引发异常。这已经修复。
这个版本处理了一些在1.10.0中出现的构建问题。大多数用户不会看到这些问题。差异是:
- 使用msvc9或msvc10编译32位Windows现在需要SSE2。这是最容易的修复,看起来是一些错误编译代码,当SSE2没有使用。如果你需要编译为没有SSE2支持的32位Windows系统,mingw32应该仍然工作。
- 使用VS2008编译python2.7 SDK更容易
- 更改Intel编译器选项,以便生成代码以支持不带SSE4.2的系统。
- 一些_config测试函数需要显式的整数返回,以避免openSUSE rpmlinter错误。
- 我们遇到了一个问题,pipy不允许重复使用文件名,导致的扩散。。 * .postN发布。不仅是名字失去了,一些包不能使用postN后缀。
Numpy 1.10.1支持Python 2.6 - 2.7和3.2 - 3.5。
提交:
45a3d84 DEP:在设置dtype时,取消满的警告。0c1a5df BLD:import setuptools允许使用VS2008编译python2.7 sdk 04211c6 BUG:在有序比较中屏蔽nan到1 826716f DOC:记录在32位平台上msvc需要SSE2的原因。49fa187 BLD:为32位msvc 9和10编译器启用SSE2 dcbc4cc MAINT:从配置检查中删除Wreturn类型警告d6564cb BLD:不为SSE4.2处理器专门构建15cb66f BLD:不为SSE4.2处理器专门构建c38bc08 DOC:fix var。参考百分位数docstring 78497f4 DOC:同步1.10.0-notes.rst在1.10.x分支与主。
此版本支持Python 2.6 - 2.7和3.2 - 3.5。
Highlights¶
- numpy.distutils现在通过传递给setup.py build的-parallel / -j参数支持并行编译
- numpy.distutils现在支持通过site.cfg进行附加定制以控制编译参数,即运行时库,额外的链接/编译标志。
- 添加np.linalg.multi_dot:计算单个函数调用中两个或多个数组的点积,同时自动选择最快的求值顺序。
- 新函数np.stack提供了用于沿着新轴连接数组序列的通用接口,补充np.concatenate用于沿现有轴连接。
- 将nanprod添加到纳米功能集。
- 在Python 3.5中支持'@'运算符。
Dropped Support¶
- _dotblas模块已删除。CBLAS支持现在在Multiarray中。
- testcalcs.py文件已删除。
- polytemplate.py文件已删除。
- npy_PyFile_Dup和npy_PyFile_DupClose已从npy_3kcompat.h中删除。
- splitcmdline已从numpy / distutils / exec_command.py中删除。
- try_run和get_output已从numpy / distutils / command / config.py中删除
- 数组打印不再支持a._format属性。
- 从np.genfromtxt中删除的关键字
skiprows和missing。 - 从np.correlate中移除关键字
old_behavior。
Future Changes¶
- 在像
arr1 == arr2的数组比较中,许多角落案例涉及字符串或结构化dtypes,现在发出FutureWarning或DeprecationWarning,并且将来会更改为执行元素法比较或引发错误。 - 在
np.lib.split中,无论要拆分的数组的大小如何,结果中的空数组始终具有维(0,)。在Numpy 1.11中,行为将被改变,以便维度将被保留。从Numpy 1.9开始,此变更的FutureWarning已经到位,但是由于错误,有时没有提出警告,维度已经保留。 - SafeEval类将在Numpy 1.11中删除。
- alterdot和restoredot函数将在Numpy 1.11中删除。
有关这些更改的详细信息,请参阅下文。
Compatibility notes¶
Default casting rule change¶
内部操作的默认投射已更改为'same_kind'。例如,如果n是整数的数组,并且f是浮点数组,则n + = f t0>将导致在不太可能的情况下,示例代码不是实际的错误,可以通过将其重写为TypeError,而在以前的Numpy版本中,浮动将被默认转换为int。np.add(n, f, t2> out = n, casting ='unsafe')。自Numpy 1.7起,旧的'unsafe'默认值已被弃用。
numpy version string¶
开发版本的numpy版本字符串已从x.y.z.dev-githash更改为x.y.z.dev0+githash(注意+),以符合PEP 440。
relaxed stride checking¶
默认情况下,NPY_RELAXED_STRIDE_CHECKING现在为true。
更新:在1.10.2中,由于后兼容性原因,NPY_RELAXED_STRIDE_CHECKING的默认值已更改为false。需要更多的时间才能使其成为默认值。
Concatenation of 1d arrays along any but axis=0 raises IndexError¶
使用axis!= 0从NumPy 1.7以来引发了DeprecationWarning,它现在引发一个错误。
np.ravel, np.diagonal and np.diag now preserve subtypes¶
There was inconsistent behavior between x.ravel() and np.ravel(x), as well as between x.diagonal() and np.diagonal(x), with the methods preserving subtypes while the functions did not. 这已被修复,并且现在的功能像方法一样,保留子类型,除了在矩阵的情况下。矩阵是特殊情况下的向后兼容性,仍然像以前一样返回1-D数组。如果你需要保留矩阵子类型,使用方法而不是函数。
rollaxis and swapaxes always return a view¶
以前,返回了一个视图,除非没有对轴的顺序进行更改,在这种情况下返回了输入数组。在所有情况下都返回视图。
nonzero now returns base ndarrays¶
以前,在1-D输入(返回基本ndarray)和更高维度(保留的子类)之间存在不一致。行为已经统一,返回现在将是一个基础ndarray。子类仍然可以通过提供自己的非零方法来覆盖此行为。
C API¶
swapaxes的更改也适用于PyArray_SwapAxes C函数,该函数现在在所有情况下返回视图。
非零的更改也适用于PyArray_Nonzero C函数,该函数现在在所有情况下返回基准ndarray。
dtype结构(PyArray_Descr)在结尾处有一个新成员来缓存其哈希值。这不应该影响任何良好的应用程序。
对连接函数的更改DeprecationWarning也会影响PyArray_ConcatenateArrays,
recarray field return types¶
以前,通过attribute和by访问的recarray字段的返回类型不一致,字符串类型的字段作为chararrays返回。现在,通过属性或索引访问的字段将返回非结构化类型的字段的ndarray,以及结构化类型的字段的recarray。值得注意的是,这会影响包含空白字符串的字符串,因为尾部空格从字符串中剪除,但保留在字符串类型的ndarrays。此外,嵌套结构化字段的dtype.type现在被继承。
recarray views¶
查看ndarray作为recarray现在自动将dtype转换为np.record。请参阅新记录数组文档。此外,查看具有非结构化dtype的recarray不再将结果的类型转换为ndarray - 结果将保持为recarray。
‘out’ keyword argument of ufuncs now accepts tuples of arrays¶
当使用ufunc的'out'关键字参数时,可以提供数组的一个元组,每个ufunc输出一个。对于具有单个输出的ufunc,单个数组也是有效的“out”关键字参数。以前,可以在“out”关键字参数中提供单个数组,它将用作具有多个输出的ufuncs的第一个输出,已被弃用,现在将导致DeprecationWarning在将来。
byte-array indices now raises an IndexError¶
在Python 3中使用字节字符串索引ndarray现在引发一个IndexError而不是ValueError。
Masked arrays containing objects with arrays¶
对于这种(罕见的)屏蔽数组,获取单个屏蔽项不再返回损坏的屏蔽数组,而是项的完全屏蔽版本。
Median warns and returns nan when invalid values are encountered¶
类似于平均值,中值和百分位数现在发出运行时警告,并在存在NaN的切片中返回NaN。要计算中值或百分位数而忽略无效值,请使用新的nanmedian或nanpercentile函数。
Functions available from numpy.ma.testutils have changed¶
numpy.testing的所有函数曾经从numpy.ma.testutils获得,但并不是所有的函数都被重新定义为使用masked数组。这些函数中的大多数现在已从numpy.ma.testutils中删除,并保留了一个小子集以保留向后兼容性。从长远来看,这应该有助于避免错误使用错误的功能,但它可能会导致一些进口问题。
New Features¶
Reading extra flags from site.cfg¶
以前定制依赖库和numpy本身的编译只能通过distutils包中的代码更改来完成。现在,numpy.distutils从site.cfg的每个组读取以下额外的标志:
runtime_library_dirs/rpath,设置要覆盖的运行时库目录LD_LIBRARY_PATH
extra_compile_args,向源代码的编译添加额外的标志extra_link_args,在链接库时添加额外的标志
这应该至少部分地完成用户定制。
np.cbrt to compute cube root for real floats¶
np.cbrt包装C99立方根函数cbrt。与np.power(x,1./3. )相比它被明确定义为负实数浮点和一点快。
numpy.distutils now allows parallel compilation¶
通过将-parallel = n或-jn传递到setup.py build,扩展的编译现在在n t3 >并行进程。并行化限于一个扩展中的文件,因此使用Cython的项目不会获利,因为它从单个文件构建扩展。
genfromtxt has a new max_rows argument¶
已将max_rows参数添加到genfromtxt,以限制在单个调用中读取的行数。使用此功能,可以通过重复调用函数来读取存储在单个文件中的多个数组。
New function np.broadcast_to for invoking array broadcasting¶
np.broadcast_to根据numpy的广播规则手动将数组广播到给定形状。该功能类似于broadcast_arrays,其实际上已被重写为在内部使用broadcast_to,但只需要一个数字组。
New context manager clear_and_catch_warnings for testing warnings¶
当Python发出警告时,它会在模块属性__warningregistry__中记录此警告已在导致警告的模块中发出。一旦发生这种情况,就不可能再次发出警告,除非您清除__warningregistry__中的相关条目。这使得测试警告很困难和脆弱,因为如果你的测试来自另一个已经引起警告的,你将不能发出警告或测试它。上下文管理器clear_and_catch_warnings清除模块注册表中的警告,并在退出时重置它们,这意味着警告可以重新启动。
cov has new fweights and aweights arguments¶
fweights和aweights参数通过对观察向量应用两种类型的加权,为协方差计算增加了新的功能。fweights的数组指示每个观察向量的重复的数目,并且aweights的数组提供它们的相对重要性或概率。
Support for the ‘@’ operator in Python 3.5+¶
Python 3.5增加了对PEP465中提出的矩阵乘法运算符'@'的支持。对此的初步支持已经实现,并且还添加了一个等效函数matmul用于测试目的,并在早期的Python版本中使用。函数是初步的,其可选参数的顺序和数量可以改变。
New argument norm to fft functions¶
默认归一化具有未缩放的直接变换,并且逆变换由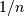 缩放。通过将关键字参数
缩放。通过将关键字参数norm设置为"ortho"(默认为None),可以获得酉变换,将缩放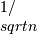 。
。
Improvements¶
np.digitize using binary search¶
np.digitize现在按照np.searchsorted实现。这意味着二进制搜索用于对值进行二进制化,对于大于先前线性搜索的二进制数,这些二进制搜索的尺度更好。它也删除了对输入数组为一维的要求。
np.poly now casts integer inputs to float¶
np.poly现在将整数类型的1维输入数组转换为双精度浮点,以防止在计算monic多项式时的整数溢出。通过传递对象类型的数组,仍然可以获得更高的精度结果,例如,与Python ints。
np.interp can now be used with periodic functions¶
np.interp现在具有提供输入数据xp的周期的新参数周期。在这种情况下,输入数据被正确地归一化为给定周期,并且一个结束点被添加到xp的每个末端,以便关闭前一周期周期和下一周期周期,从而产生正确的插值行为。
np.pad supports more input types for pad_width and constant_values¶
constant_values参数现在接受NumPy数组和浮点值。NumPy数组作为pad_width的输入支持,并且如果其值不是整数类型,则引发异常。
np.argmax and np.argmin now support an out argument¶
The out parameter was added to np.argmax and np.argmin for consistency with ndarray.argmax and ndarray.argmin. 新参数的行为与这些方法中的行为完全相同。
More system C99 complex functions detected and used¶
现在检测到 t> complex.h中的所有函数。有以下函数的新的回退实现。
- npy_ctan,
- npy_cacos,npy_casin,npy_catan
- npy_ccosh,npy_csinh,npy_ctanh,
- npy_cacosh,npy_casinh,npy_catanh
作为这些改进的结果,返回值将有一些小的变化,特别是对于角落情况。
np.loadtxt support for the strings produced by the float.hex method¶
由float.hex产生的字符串看起来像0x1.921fb54442d18p+1,因此这不是用于表示无符号整数类型的十六进制。
np.isclose properly handles minimal values of integer dtypes¶
为了正确处理整数类型的最小值,在比较期间,np.isclose现在将转换为float dtype。这将其行为与由np.allclose提供的行为对齐。
np.allclose uses np.isclose internally.¶
np.allclose现在内部使用np.isclose,并继承通过设置equal_nan=True将NaNs相等的能力。子类,例如np.ma.MaskedArray,现在也被保留。
np.genfromtxt now handles large integers correctly¶
np.genfromtxt现在可以在32位系统上正确处理大于2**31-1的整数,并大于2**63-1 (在这些情况下,它先前曾以OverflowError崩溃)。大于2**63-1的整数将转换为浮点值。
np.load, np.save have pickle backward compatibility flags¶
函数np.load和np.save有用于控制pickled Python对象的向后兼容性的其他关键字参数。这使得Python 3上的Numpy加载在Python 2上生成的包含对象数组的npy文件。
MaskedArray support for more complicated base classes¶
正在移除内建的假设,即基本表现得像一个简单的数组。特别是,设置和获取元素和范围将尊重__setitem__和__getitem__的基类覆盖,并且算术将遵循__add__,__sub__等
Changes¶
dotblas functionality moved to multiarray¶
dot,inner和vdot的cblas版本已集成到多阵列模块中。特别是,vdot现在是一个多阵列函数,它不是以前。
stricter check of gufunc signature compliance¶
现在对函数的签名更严格地检查对广义通用函数的输入:现在需要在输入数组中存在所有核心维度;具有相同标签的核心维度必须具有完全相同的大小;和输出核心维度必须通过相同的标签输入核心维度或通过传入输出数组来指定。
views returned from np.einsum are writeable¶
np.einsum返回的视图现在可以在每次输入数组可写时写入。
np.argmin skips NaT values¶
np.argmin现在跳过datetime64和timedelta64数组中的NaT值,使其与np.min,np.argmax和np .max。
Deprecations¶
Array comparisons involving strings or structured dtypes¶
通常,对数组的比较操作执行元素方法比较并返回布尔的数组。但在某些角落的情况下,特别是涉及字符串是结构化的类型,NumPy历史上返回一个标量。例如:
### Current behaviour
np.arange(2) == "foo"
# -> False
np.arange(2) < "foo"
# -> True on Python 2, error on Python 3
np.ones(2, dtype="i4,i4") == np.ones(2, dtype="i4,i4,i4")
# -> False
继续工作从1.9开始,在1.10中,这些比较现在将提高FutureWarning或DeprecationWarning,并且将来修改它们以与其他比较操作更一致,例如:
### Future behaviour
np.arange(2) == "foo"
# -> array([False, False])
np.arange(2) < "foo"
# -> error, strings and numbers are not orderable
np.ones(2, dtype="i4,i4") == np.ones(2, dtype="i4,i4,i4")
# -> [False, False]
SafeEval¶
numpy / lib / utils.py中的SafeEval类已弃用,并将在下一个版本中删除。
alterdot, restoredot¶
alterdot和restoredot函数不再执行任何操作,已被弃用。
pkgload, PackageLoader¶
这些加载包的方法现已废弃。
bias, ddof arguments to corrcoef¶
corrcoef函数的bias和ddof参数的值在相关系数隐含的除法中取消,因此对返回的值。
我们现在弃用这些参数到corrcoef和掩码的数组版本ma.corrcoef。
因为我们不赞成ma.corrcoef的bias参数,我们也不赞成使用allow_masked参数作为位置参数,将随着bias的移除而改变。allow_masked将在适当时候成为仅关键字参数。
dtype string representation changes¶
从1.6开始,从它的字符串表示创建一个dtype对象,例如。 'f4'会在大小与现有类型不对应时发出弃用警告,并且默认为创建类型的默认大小的dtype。从此版本开始,此时将产生TypeError。
唯一的例外是对象类型,其中'O4'和'O8'仍然会发出废弃警告。此平台相关的表示将在下一个版本中引发错误。
In preparation for this upcoming change, the string representation of an object dtype, i.e. np.dtype(object).str, no longer includes the item size, i.e. will return '|O' instead of '|O4' or '|O8' as before.
NumPy 1.9.2 Release Notes¶
这是1.9.x系列中的仅修复版本。
Issues fixed¶
- #5316:修复字符串和复杂类型的dtype比较过大
- #5424:在ndarrays上使用时修复ma.median
- #5481:为不同字节顺序的结构化数字字段固定astype
- #5354:修复复杂数组时的segfault
- #5524:allow np.argpartition on non ndarrays
- #5612:修复ndarray.fill以接受全范围的uint64
- #5155:使用comments = None和字符串无数据修复loadtxt
- #4476:如果结构化dtype具有datetime组件,则掩码数组视图将失败
- #5388:使RandomState.set_state和RandomState.get_state线程安全
- #5390:使种子,randint和shuffle线程安全
- #5374:修正了不正确的assert_array_almost_equal_nulp文件
- #5393:添加对ATLAS> 3.9.33的支持。
- #5313:PyArray_AsCArray导致3d数组的segfault
- #5492: handle out of memory in rfftf
- #4181:修正random.pareto docstring中的一些错误
- #5359:对linspace文档字符串进行了小的更改
- #4723:修复AIX上的编译问题
这是1.9.x系列中的仅修复版本。
Issues fixed¶
- gh-5184:恢复梯度的线性边缘行为,如它二阶行为可通过edge_order关键字获得
- gh-4007:workaround在OSX 10.9上加速sgemv崩溃
- gh-5100:从没有len()的可迭代对象恢复对象dtype推断
- gh-5163:避免gcc-4.1.2(红帽5)编译错误导致崩溃
- gh-5138:在包含inf的数组上修复nanmedian
- gh-5240:修复不返回数组从ufuncs与subok = False设置
- gh-5203:在MaskedArray中复制继承的掩码._ array_finalize__
- gh-2317:genfromtxt没有正确处理fill_values = 0
- gh-5067:restore api of npy_PyFile_DupClose in python2
- gh-5063:无法将无效序列索引转换为元组
- gh-5082:unicode数组上的argmin()分段故障
- gh-5095:不要从np.where传播子类型
- gh-5104:使用SciPy的稀疏矩阵进行np.inner segfaults
- gh-5251:问题与fromarrays不使用正确的格式unicode数组
- gh-5136:如果导入线程失败,则导入dummy_threading
- gh-5148:使用Python标志'-OO'运行时使numpy导入
- gh-5147:Einsum双收缩特定顺序导致ValueError
- gh-479:使f2py工作与意向(在out)
- gh-5170:使python2 .npy文件在python3中可读
- gh-5027:使用'll'作为long long的默认长度说明符
- gh-4896:修复由C99复杂支持导致的MSVC 2013的构建错误
- gh-4465:使PyArray_PutTo尊重可写标志
- gh-5225:解决崩溃时使用的日期时间没有dtype集
- gh-5231:在c99模式下修复build
此版本支持Python 2.6 - 2.7和3.2 - 3.4。
Highlights¶
- 在各个领域的许多性能改进,最引人注目的是对小数组的索引和操作显着更快。索引操作现在也释放GIL。
- 添加nanmedian和nanpercentile可以舍去纳米函数集。
Dropped Support¶
- oldnumeric和numarray模块已删除。
- doc / pyrex和doc / cython目录已删除。
- doc / numpybook目录已删除。
- numpy / testing / numpytest.py文件已与其包含的importall函数一起删除。
Future Changes¶
- numpy / polynomial / polytemplate.py文件将在NumPy 1.10.0中删除。
- inplace操作的默认转换将在Numpy 1.10.0中更改为“same_kind”。这肯定会打破一些当前忽略警告的代码。
- 轻松的步幅检查将是默认的1.10.0
- 字符串版本检查将中断,因为,例如'1.9'>'1.10'是True。已添加可用于这种比较的NumpyVersion类。
- 对角线和diag函数将返回1.10.0中的可写视图
- S和/或a dtypes可以更改为表示Python字符串而不是字节,在Python 3中,这两种类型非常不同。
Compatibility notes¶
The diagonal and diag functions return readonly views.¶
在NumPy 1.8中,对角线和diag函数只返回只读副本,在NumPy 1.9中,它们返回只读视图,在1.10中,它们将返回可写入的视图。
Special scalar float values don’t cause upcast to double anymore¶
在先前的numpy版本中,涉及包含特殊值NaN,Inf和-Inf的浮点标量的操作导致结果类型至少float64。由于特殊值可以在最小可用浮点类型中表示,因此不再执行上行转换。
例如:dtype:
np.array([1., dtype = np.float32) * / t4>
现在保持float32,而不是投射到float64。涉及非特殊值的操作未更改。
Percentile output changes¶
如果给定多个百分位数以计算numpy.percentile,则返回一个数组而不是一个列表。单个百分位数仍然返回一个标量。数组等效于通过np.array将旧版本中返回的列表转换为数组。
如果使用overwrite_input选项,输入仅部分而不是完全排序。
ndarray.tofile exception type¶
所有tofile异常现在是IOError,有些以前是ValueError。
Invalid fill value exceptions¶
对numpy.ma.core._check_fill_value的两个更改:
- 当填充值是一个字符串,并且数组类型不是“OSUV”之一时,会引发TypeError而不是使用的默认填充值。
- 当填充值溢出数组类型时,会引发TypeError而不是OverflowError。
Polynomial Classes no longer derived from PolyBase¶
这可能导致依赖于从PolyBase派生的多项式类的人的问题。它们现在都是从抽象基类ABCPolyBase派生的。严格来说,应该涉及弃用,但是没有找到使用旧基础类的外部代码。
Using numpy.random.binomial may change the RNG state vs. numpy < 1.9¶
在生成二项随机变量的算法之一中的错误已被修复。这个改变可能改变执行的随机抽取的数量,因此在调用distribution.c :: rk_binomial_btpe之后,序列位置将不同。任何依赖于处于已知状态的RNG的测试都应该作为结果进行检查和/或更新。
Random seed enforced to be a 32 bit unsigned integer¶
np.random.seed和np.random.RandomState现在抛出一个ValueError,如果种子不能安全地转换为32位无符号整数。现在失败的应用程序可以通过将更高的32位值屏蔽为零来修复:种子 = 种子 &amp; / t4> 0xFFFFFFFF。这是在旧版本中静默做的,所以随机流保持不变。
Argmin and argmax out argument¶
现在检查np.argmin和np.argmax的out参数及其等效的C-API函数,以精确匹配所需的输出形状。如果检查失败,则会引发ValueError而不是TypeError。
Einsum¶
删除不必要的广播符号限制。np.einsum('ijk,j->ijk', A, B) can also be written as np.einsum('ij...,j->ij...', A, B) (ellipsis is no longer required on ‘j’)
Indexing¶
NumPy索引已在此版本中完全重写。这使得最先进的整数索引操作更快,并且应该没有其他影响。但是,在高级索引操作中引入了一些细微的更改和弃用:
- 这意味着
array(1)[array(True)]给出array([1]),而不是原始数组。 - 高级索引到一维数组中,当值数组的形状太小或不匹配时,用于具有(未记录的)关于在赋值中重复值数组的特殊处理。使用此代码会产生错误。为了兼容性,您可以使用
arr.flat [index] = 值(例如a = np.ones(10); t4> = [1, 2, 3]) - 高级索引的迭代顺序始终为C顺序。在NumPy 1.9. 迭代顺序适应于输入,并且不能保证(除了单个高级索引,由于兼容性原因,它不会被反转)。这意味着如果多个值分配给同一个元素,结果是未定义的。An example for this is
arr[[0, 0], [1, 1]] = [1, 2], which may setarr[0, 1]to either 1 or 2. - 等同于迭代次序,高级索引结果的存储器布局适于更快的索引并且不能被预测。
- 所有索引操作都返回一个视图或副本。无索引操作将返回原始数组对象。(例如
arr[...]) - 在将来,布尔数组喜欢(例如python bools列表)将始终被视为布尔索引,布尔标量(包括python
True)将是合法的布尔索引。此时,对于标量数组来说已经是这样的情况:允许一般的正 = a [a 0]工作时a - 在NumPy 1.8中,如果操作的结果是标量,则可以使用等于1和0的
array(True)和array(False)。这将在NumPy 1.9中引发错误,并且如上所述,在将来被视为布尔索引。 - 所有非整数数组类似已弃用,对象数组的自定义整数像对象可能必须显式转换。
- 高级索引的错误报告提供更多信息,但在某些情况下错误类型已更改。(索引数组的广播错误报告为
IndexError) - 不推荐使用多于一个省略号(
...)的索引。
Non-integer reduction axis indexes are deprecated¶
不推荐使用非整数轴索引来缩减ufunc,例如add.reduce或sum。
promote_types and string dtype¶
promote_types函数现在返回一个有效的字符串长度,当给定一个整数或float dtype作为一个参数和一个字符串dtype作为另一个参数。以前,它总是返回输入字符串dtype,即使它不够长,不能存储转换为字符串的最大整数/浮点值。
can_cast and string dtype¶
can_cast函数现在在“安全”转换模式下为integer / float dtype和string dtype返回False如果字符串dtype length不足以存储转换为字符串的最大整数/浮点值。之前,在“安全”模式下,can_cast返回True,表示整数/浮点型dtype和任何长度的字符串dtype。
astype and string dtype¶
astype方法现在返回一个错误,如果转换的字符串dtype在“安全”转换模式不够长,以保持正在转换的整数/浮点数组的最大值。以前即使结果被截断也允许转换。
npyio.recfromcsv keyword arguments change¶
npyio.recfromcsv不再接受未记录的更新关键字,该关键字用于覆盖dtype关键字。
The doc/swig directory moved¶
doc/swig目录已移至tools/swig。
The npy_3kcompat.h header changed¶
未使用的simple_capsule_dtor函数已从npy_3kcompat.h中删除。注意,这个头并不意味着在numpy之外使用;其他项目应该在需要时使用自己的这个文件的副本。
Negative indices in C-Api sq_item and sq_ass_item sequence methods¶
当直接访问用于获取项的sq_item或sq_ass_item PyObject插槽时,将不再支持负索引。PySequence_GetItem和PySequence_SetItem固定负索引,以便可以在那里使用。
NDIter¶
当现在调用NpyIter_RemoveAxis时,迭代器范围将被重置。
当跟踪多索引并且迭代器未被缓冲时,可以使用NpyIter_RemoveAxis。在这种情况下,迭代器可以缩小大小。因为迭代器的总大小是有限的,所以迭代器可能在这些调用之前太大。在这种情况下,其大小将设置为-1,并且在构建时不发出错误,但是在删除多索引,设置迭代器范围或获取下一个函数时。
这对当前工作代码没有影响,但突出显示如果这些情况可能发生,检查错误返回的必要性。在大多数情况下,迭代的数组与迭代器一样大,因此不会出现这样的问题。
此更改已应用于1.8.1版本。
zeros_like for string dtypes now returns empty strings¶
要匹配zeros函数zeros_like,现在返回用空字符串初始化的数组,而不是填充'0'的数组。
New Features¶
Percentile supports more interpolation options¶
np.percentile现在具有interpolation关键字参数,用于指定如果百分位数落在两个值之间,点应以哪种方式插值。请参阅可用选项的文档。
Generalized axis support for median and percentile¶
np.median和np.percentile现在支持广义轴参数,例如ufunc reduced。现在可以说axis =(index,index)为缩小选择一个轴列表。还添加了keepdims关键字参数,以允许方便地广播到原始形状的数组。
Dtype parameter added to np.linspace and np.logspace¶
现在可以使用dtype参数指定从linspace和logspace函数返回的数据类型。
More general np.triu and np.tril broadcasting¶
对于ndim超过2的数组,这些函数现在将应用于最后两个轴,而不是引发异常。
tobytes alias for tostring method¶
ndarray.tobytes和MaskedArray.tobytes已作为tostring的别名添加,它将数组导出为bytes。这在Python 3中更加一致,其中str和bytes不一样。
Build system¶
添加了对ppc64le和OpenRISC体系结构的实验支持。
Compatibility to python numbers module¶
现在,所有数字numpy类型都在python numbers模块中的类型层次结构中注册。
increasing parameter added to np.vander¶
Vandermonde矩阵的列的排序可以用这个新的布尔参数指定。
unique_counts parameter added to np.unique¶
现在可以获得每个唯一项目在输入中出现的次数作为可选的返回值。
Support for median and percentile in nanfunctions¶
np.nanmedian和np.nanpercentile函数的行为类似于中位数和百分位数函数,除非NaN被忽略。
NumpyVersion class added¶
类可以从numpy.lib导入,并且可以在numpy版本转到1.10.devel时用于版本比较。例如:
>>> from numpy.lib import NumpyVersion
>>> if NumpyVersion(np.__version__) < '1.10.0'):
... print('Wow, that is an old NumPy version!')
Allow saving arrays with large number of named columns¶
numpy存储格式1.0只允许数组头的总大小为65535字节。这可以被具有大量列的结构化数据组超过。添加了新的格式2.0,将报头大小扩展到4 GiB。np.save将自动保存为2.0格式,如果数据需要它,否则它将始终使用更兼容的1.0格式。
Full broadcasting support for np.cross¶
np.cross现在正确地广播其两个输入数组,即使它们具有不同的维数。在早期版本中,这将导致产生错误或计算错误的结果。
Improvements¶
Better numerical stability for sum in some cases¶
成对求和现在在求和方法中使用,但只能沿快轴和值组在一些常见的情况下,这也应该提高var和std的精度。
Percentile implemented in terms of np.partition¶
np.percentile已按照np.partition实现,它只通过选择算法对数据进行部分排序。这改进了从O(nlog(n))到O(n)的时间复杂度。
Performance improvement for np.array¶
使用np.array将包含数组的列表转换为数组的性能已得到改进。它现在的速度等于np.vstack(list)。
Performance improvement for np.searchsorted¶
对于内置数字类型,np.searchsorted不再依赖数据类型的compare函数来执行搜索,而是通过类型特定函数实现。根据输入的大小,这可以导致超过2x的性能改进。
Optional reduced verbosity for np.distutils¶
设置numpy.distutils.system_info.system_info.verbosity = 0,然后调用numpy.distutils.system_info.get_info('blas_opt')将不会在输出上打印任何内容。这主要是对使用numpy.distutils的其他包。
Covariance check in np.random.multivariate_normal¶
当协方差矩阵不是正半定的时,会出现RuntimeWarning警告。
Polynomial Classes no longer template based¶
多项式类已被重构为使用抽象基类而不是模板,以实现公共接口。这使得导入多项式包更快,因为类不需要在导入时编译。
More GIL releases¶
现在还有更多的函数发布全局解释器锁,允许使用threading模块更有效的并行化。最显着的是GIL现在发布用于花型索引,np.where和random模块现在使用每状态锁而不是GIL。
MaskedArray support for more complicated base classes¶
正在移除内建的假设,即基本表现得像一个简单的数组。在particalur,repr和str现在应该更可靠地工作。
C-API¶
Deprecations¶
Non-integer scalars for sequence repetition¶
使用非整数numpy标量重复python序列已被弃用。For example np.float_(2) * [1] will be an error in the future.
select input deprecations¶
不推荐使用select的整数和空输入。在将来只有布尔数组将是有效条件,并且空的condlist将被认为是输入错误,而不是返回默认值。
rank function¶
已弃用rank函数,以避免与numpy.linalg.matrix_rank混淆。
Object array equality comparisons¶
在将来的对象数组比较中,==和np.equal将不再使用身份检查。例如:
>>> a = np.array([np.array([1, 2, 3]), 1])
>>> b = np.array([np.array([1, 2, 3]), 1])
>>> a == b
即使a和b中的数组是同一个对象,也会一致返回False(以后会有错误)。
如果广播或元素比较等,等于运算符==将在以后引发像np.equal的错误失败。
与arr == None的比较将进行元素比较,而不是只返回False。代码应使用arr为无。
所有这些更改都将在此时提供Deprecation或FutureWarnings。
Issues fixed¶
- gh-4836:分区在等范围内对多个选择产生错误的结果
- gh-4656:make fftpack._raw_fft threadsafe
- gh-4628:np.nanmax,np.nanmin中_copyto的参数顺序不正确
- gh-4642:保持GIL用于转换字段类型
- gh-4733:fix np.linalg.svd(b,compute_uv = False)
- gh-4853:避免在i386上减少不对齐的simd负载
- gh-4722:修复seg fault将空字符串转换为对象
- gh-4613:修复了在array_richcompare中缺少NULL检查
- gh-4774:避免straded byteswap的未对齐访问
- gh-650:从一些缓冲区创建数组时,防止除以零
- gh-4602:ifort有优化标志O2的问题,使用O1
这是1.8.x系列中仅修复的错误修复。
Issues fixed¶
- gh-4276:修复对象数组的mean,var,std方法
- gh-4262:删除不安全的mktemp使用
- gh-2385:absolute(complex(inf))在python3中引发无效警告
- gh-4024:序列赋值不会引起形状不匹配的异常
- gh-4027:修正比BUFFERSIZE长的字符串的读取
- gh-4109:修复对象标量返回0-d数组索引的类型
- gh-4018:解决在ufuncs中内存分配失败的缺失检查
- gh-4156:高阶Linalg.norm丢弃复杂数组的虚数元素
- gh-4144:linalg:norm失败longdouble,signed int
- gh-4094:修复_strided_to_strided_string_to_datetime中的NaT处理
- gh-4051:修复_strided_to_strided_string_to_datetime中的未初始化使用
- gh-4093:加载压缩的.npz文件在Python 2.6.6下失败
- gh-4138:segfault与非本地endian内存视图在python 3.4
- gh-4123:修复lexsort中缺少的NULL检查
- gh-4170:修复native-only long long检查内存视图
- gh-4187:修复32位大文件支持
- gh-4152:fromfile:确保文件句柄位置在python3中同步
- gh-4176:clang兼容性:在conversion_utils中有错别字
- gh-4223:获取非整数项导致数组返回
- gh-4197:修复内存视图故障情况下的小内存泄漏
- gh-4206:使用单线程python修复build
- gh-4220:add versionadded :: 1.8.0 to ufunc.at docstring
- gh-4267:改善内存分配失败的处理
- gh-4267:修复在ufunc.at中使用没有gil的capi
- gh-4261:检测GNU编译器的供应商版本
- gh-4253:IRR返回nan而不是有效的否定回答
- gh-4254:修复字节数组的不必要的字节顺序标志
- gh-3263:numpy.random.shuffle MaskedArray的clobbers掩码
- gh-4270:np.random.shuffle不能使用灵活的类型
- gh-3173:当'size'参数为random.multinomial时的分段故障
- gh-2799:允许使用唯一的复杂列表
- gh-3504:修复整数数组标量的linspace截断
- gh-4191:get_info('openblas')不读库的键
- gh-3348:访问冲突_descriptor_from_pep3118_format
- gh-3175:从bytearray的numpy.array()的分段错误
- gh-4266:histogramdd - 非常接近最后边界的条目的错误结果
- gh-4408:修复对象数组的stride_stricks.as_strided函数
- gh-4225:在Windows编译器构建中修复np.inf的log1p和exmp1返回
- gh-4359:修复flex数组的str.format中的无限递归
- gh-4145:广播结果与指数运算符的形状不正确
- gh-4483:修正{dot,multiply,inner}(scalar,matrix_of_objs)的交换性,
- gh-4466:当大小可能改变时,延迟npyiter大小检查
- gh-4485:缓冲步幅被错误地标记为固定
- gh-4354:byte_bounds失败,datetime dtypes
- gh-4486:segfault /错误从/转换为高精度datetime64对象
- gh-4428:einsum(无,无,无,无)导致segfault
- gh-4134:对于大小为1的对象缩减,未初始化使用
Changes¶
NDIter¶
当现在调用NpyIter_RemoveAxis时,迭代器范围将被重置。
当跟踪多索引并且迭代器未被缓冲时,可以使用NpyIter_RemoveAxis。在这种情况下,迭代器可以缩小大小。因为迭代器的总大小是有限的,所以迭代器可能在这些调用之前太大。在这种情况下,其大小将设置为-1,并且在构建时不发出错误,但是在删除多索引,设置迭代器范围或获取下一个函数时。
这对当前工作代码没有影响,但突出显示如果这些情况可能发生,检查错误返回的必要性。在大多数情况下,迭代的数组与迭代器一样大,因此不会出现这样的问题。
Optional reduced verbosity for np.distutils¶
设置numpy.distutils.system_info.system_info.verbosity = 0,然后调用numpy.distutils.system_info.get_info('blas_opt')将不会在输出上打印任何内容。这主要是对使用numpy.distutils的其他包。
Deprecations¶
Highlights¶
- 新的,没有2to3,Python 2和Python 3由通用代码库支持。
- 新的线性代数的gufuncs,使能对堆叠数组的操作。
- 使用
.at方法为ufuncs创建新的inplace花式索引。 - 新建,
partition功能,通过选择快速中值进行部分排序。 - 新的,
nanmean,nanvar和nanstd功能跳过NaN。 - 新,
full和full_like函数创建值初始化数组。 - 新建,
PyUFunc_RegisterLoopForDescr,更好的ufunc支持用户dtypes。 - 许多领域的许多性能改进。
Future Changes¶
在此版本中,Datetime64类型仍然是实验性的。在1.9中,可能会有一些更改,使其更可用。
对角线方法当前返回一个新的数组,并引发一个FutureWarning。在1.9它将返回一个只读视图。
从结构化类型的数组中选择多个字段当前返回一个新的数组,并生成一个FutureWarning。在1.9它将返回一个只读视图。
numpy / oldnumeric和numpy / numarray兼容性模块将在1.9中删除。
Compatibility notes¶
doc / sphinxext内容已被移入其自己的github存储库,并作为子模块包含在numpy中。有关如何访问内容,请参阅doc / HOWTO_BUILD_DOCS.rst.txt中的说明。
numpy.void标量的哈希函数已更改。以前,指向数据的指针被散列为整数。现在,散列函数使用元组散列算法来组合标量元素的散列函数,但前提是标量是只读的。
Numpy已经将其构建系统切换为默认使用“单独编译”。在以前的版本中,这是支持,但不是默认。这应该产生与旧系统相同的结果,但如果你想做一些复杂的事情,如链接numpy静态或使用不寻常的编译器,那么它可能会遇到问题。如果是这样,请提交一个错误并作为临时解决方法您可以通过导出shell变量NPY_SEPARATE_COMPILATION = 0重新启用旧的构建系统。
对于AdvancedNew迭代器,oa_ndim标志现在应为-1,表示未传递op_axes和itershape。oa_ndim == 0情况,现在表示0-D迭代,op_axes这不会影响NpyIter_New或NpyIter_MultiNew函数。
函数nanargmin和nanargmax现在返回所有NaN切片中的索引的np.iinfo ['intp']。min。以前,函数将为数组返回一个ValueError,并为标量返回产生NaN。
NPY_RELAXED_STRIDES_CHECKING¶
有一个新的编译时环境变量NPY_RELAXED_STRIDES_CHECKING。如果此变量设置为1,则numpy将考虑更多的数组为C或F连续 - 例如,可能具有同时被认为是C和F连续的列向量。新的定义更准确,允许更快的代码,减少不必要的副本,并在内部简化numpy的代码。然而,它也可能会破坏第三方库对C和F连续数组的跨度值做出太强的假设。(目前也知道,这会打破Cython代码使用memoryviews,这将在Cython中修复)。这将会成为未来的未来,所以请立即测试您的代码现在反对NUMPY建立与:
NPY_RELAXED_STRIDES_CHECKING=1 python setup.py install
你可以检查NPY_RELAXED_STRIDES_CHECKING是否生效通过运行:
np.ones((10, 1), order="C").flags.f_contiguous
如果启用了松弛步幅检查,则为True,否则为False。到目前为止,我们看到的典型问题是与C-contiguous数组一起工作的C代码,并且假定可以通过查看PyArray_STRIDES(arr)数组中的最后一个元素来访问itemsize。当放松步幅生效时,这不是真的(事实上,在某些角落情况下它从来不是真的)。而应使用PyArray_ITEMSIZE(arr)。
有关详细信息,请参阅文档中的“内存布局”。
Binary operations with non-arrays as second argument¶
Binary operations of the form <array-or-subclass> * <non-array-subclass> where <non-array-subclass> declares an __array_priority__ higher than that of <array-or-subclass> will now unconditionally return NotImplemented, giving <non-array-subclass> a chance to handle the operation. Previously, NotImplemented would only be returned if <non-array-subclass> actually implemented the reversed operation, and after a (potentially expensive) array conversion of <non-array-subclass> had been attempted. (bug,pull request)
Function median used with overwrite_input only partially sorts array¶
如果median与overwrite_input选项一起使用,则输入数组现在将仅部分排序,而不是完全排序。
Fix to financial.npv¶
npv函数有一个错误。与文档所述相反,它从索引1到M而不是从0到M t7 > - 1。修订更改返回的值。mirr函数调用npv函数,但是解决了这个问题,所以也是固定的,mirr函数的返回值保持不变。
Runtime warnings when comparing NaN numbers¶
比较NaN浮点数现在会引起invalid运行时警告。如果期望使用NaN,则可以使用np.errstate忽略警告。例如。:
with np.errstate(invalid='ignore'):
operation()
New Features¶
Support for linear algebra on stacked arrays¶
gufunc机器现在用于np.linalg,允许对堆栈的数组和向量进行操作。例如:
>>> a
array([[[ 1., 1.],
[ 0., 1.]],
[[ 1., 1.],
[ 0., 1.]]])
>>> np.linalg.inv(a)
array([[[ 1., -1.],
[ 0., 1.]],
[[ 1., -1.],
[ 0., 1.]]])
In place fancy indexing for ufuncs¶
在处的at例如,以下将增加数组中的第一和第二项,并且将第三项增加两次:numpy.add.at(arr, [0, t2> 1, 2, 2], 1)
这是许多人误认为arr [[0, 1, 2, 2]] + = 1会做,但是不工作,因为arr[2]的递增值被简单地复制到在arr中的第三个插槽,两次,不递增两次。
New functions partition and argpartition¶
通过选择算法对数组进行部分排序的新功能。
通过索引k的partition将k最小元素移动到数组的前面。k之前的所有元素小于或等于位置k中的值,并且k之后的所有元素大于或等于位置k。这些边界内的值的顺序是未定义的。可以提供索引序列以在一次迭代分区中将它们全部排序到其排序位置。这可以用于有效地获得诸如样本的中值或百分位数的顺序统计。partition具有O(n)的线性时间复杂度,而完整排序具有O(n log )。
New functions nanmean, nanvar and nanstd¶
添加新的纳米感知统计函数。在这些函数中,结果是如果从所有计算中省略纳米值将获得的结果。
New functions full and full_like¶
新的方便功能创建数组填充一个特定的值;与现有的zeros和zeros_like函数互补。
IO compatibility with large files¶
大型NPZ文件> 2GB可以在64位系统上加载。
Building against OpenBLAS¶
现在可以通过编辑site.cfg来构建对OpenBLAS的numpy。
New constant¶
欧拉常数现在暴露在numpy如euler_gamma。
New modes for qr¶
新模式“完全”,“减少”和“原始”被添加到qr因式分解中,旧的“全”和“经济”模式已被弃用。“reduced”模式替换了旧的“full”模式,并且是“full”模式的默认模式,因此可以通过不指定模式来维持向后兼容性。
“完整”模式返回全尺寸因子分解,其可用于获得范围空间的正交互补的基础。“原始”模式返回包含Householder反射器和缩放因子的数组,可以在将来使用以应用q,而不需要转换为矩阵。“经济”模式被简单地弃用,没有太多的用途,它不比“原始”模式更有效。
New invert argument to in1d¶
函数in1d现在接受反转参数,当True时,导致返回的数组反转。
Advanced indexing using np.newaxis¶
现在可以使用np.newaxis / 无连同索引数组,而不是仅在简单索引中。这意味着数组[np.newaxis, [0, 1]] 在将新轴添加到数组之前的前两行。
C-API¶
新的ufuncs现在可以注册内置输入类型和自定义输出类型。在这个改变之前,当从Python中调用ufunc时,NumPy将无法找到正确的ufunc循环函数,因为ufunc循环签名匹配逻辑没有查看输出操作数类型。现在找到正确的ufunc循环,只要用户提供具有正确输出类型的输出参数即可。
runtests.py¶
添加了一个简单的测试运行脚本runtests.py。它还通过setup.py build构建Numpy,并可用于在开发期间轻松运行测试。
Improvements¶
IO performance improvements¶
通过分块改善了读取大文件的性能(另见IO兼容性)。
Performance improvements to pad¶
pad函数具有新的实现,大大提高了除mode =(为向后兼容性而保留)之外的所有输入的性能。对于等级> = 4,维度的缩放显着地改善。
Performance improvements to isnan, isinf, isfinite and byteswap¶
isnan,isinf,isfinite和byteswap已经改进以利用编译器内建来避免昂贵的libc调用。这在gnu libc系统上将这些操作的性能提高了大约两倍。
Performance improvements via SSE2 vectorization¶
已对几个功能进行了优化,以利用SSE2 CPU SIMD指令。
- Float32和float64:
- 基本数学(add,减去,除数,乘法)
- sqrt
- 最小值/最大值
- absolute
- 布尔:
- logical_or
- logical_and
- logical_not
这将提高这些操作的性能,对于float32 / float64高达4x / 2x,对于bool高达10x,具体取决于CPU高速缓存中数据的位置。就地操作的性能增益最大。
为了使用改进的功能,必须在编译时启用SSE2指令集。默认情况下,它在x86_64系统上启用。在有能力的CPU的x86_32上,必须通过将适当的标志传递给CFLAGS构建变量(-msse2 with gcc)来启用。
Performance improvements to median¶
中位数现在以分区而不是排序实现,这将其时间复杂度从O(nlog(n))减少到O )。如果与overwrite_input选项一起使用,则数组现在将仅部分排序,而不是完全排序。
Overrideable operand flags in ufunc C-API¶
当创建一个ufunc时,默认的ufunc操作数标志可以通过ufunc对象的新的op_flags属性重写。例如,要将第一个输入的操作数标志设置为读/写:
PyObject * ufunc = PyUFunc_FromFuncAndData(...); ufunc-> op_flags [0] = NPY_ITER_READWRITE;
这允许ufunc执行适当的操作。此外,可以通过ufunc对象的新的iter_flags属性覆盖全局标记标记。例如,要为ufunc设置reduce标志:
ufunc-> iter_flags = NPY_ITER_REDUCE_OK;
Changes¶
General¶
函数np.take现在允许0-d数组作为索引。
默认情况下,单独的编译模式已启用。
对np.insert和np.delete的几个更改:
- 以前,指数超过数组结束的负指数和指数被简单地忽略。现在,这将引发未来或弃用警告。在未来,他们将被视为正常的索引处理他们 - 负指数将环绕,超出界限的索引将产生一个错误。
- 以前,布尔指数被视为是整数(总是指数组中的第0项或第1项)。在将来,他们将被视为面具。在这个版本中,他们针对这一变化发出了FutureWarning警告。
- 在Numpy 1.7. np.insert已经允许语法np.insert(arr,3,[1,2,3])在单个位置插入多个项目。在Numpy 1.8. 这也可以用于np.insert(arr,[3],[1,2,3])。
np.pad中的填充区域现在正确圆化,不被截断。
C-API Array Additions¶
数组C-API增加了四个新功能。
- PyArray_Partition
- PyArray_ArgPartition
- PyArray_SelectkindConverter
- PyDataMem_NEW_ZEROED
C-API Developer Improvements¶
PyArray_Type实例创建函数tp_new现在使用tp_basicsize来确定要分配多少内存。在以前的版本中,只分配了sizeof(PyArrayObject)字节的内存,通常需要C-API子类型重新实现tp_new。
Deprecations¶
qr因式分解的“全”和“经济”模式已被弃用。
General¶
对于索引和大多数整数参数使用非整数已被弃用。先前的浮点索引和函数参数(例如轴或形状)会被截断为整数,而不会产生警告。例如arr.reshape(3.,-1)或arr [0. ]将在NumPy 1.8中触发一个弃用警告,并且在将来的NumPy版本中,它们将引发错误。
Authors¶
此版本包含以下人员的工作,这些人至少为此版本提供了一个补丁。名称按字母顺序排列,名字为:
- 87
- 亚当·金斯堡+
- Adam Griffiths +
- 亚历山大Belopolsky +
- Alex Barth +
- 亚历克斯福特+
- Andreas Hilboll +
- 安德烈亚斯Kloeckner +
- Andreas Schwab +
- 安德鲁·霍顿+
- argriffing +
- Arink Verma +
- Bago Amirbekian +
- Bartosz Telenczuk +
- bebert218 +
- 本杰明根+
- Bill Spotz +
- Bradley M. Froehle
- Carwyn Pelley +
- 查尔斯·哈里斯
- 克里斯
- 基督教Brueffer +
- Christoph Dann +
- Christoph Gohlke
- Dan Hipschman +
- 丹尼尔+
- Dan Miller +
- daveydave400 +
- 大卫Cournapeau
- David Warde-Farley
- 丹尼斯Laxalde
- dmuellner +
- 爱德华Catmur +
- Egor Zindy +
- 内胆
- Eric Firing
- 埃里克·福德
- Eric Moore +
- Eric Price +
- Fazlul Shahriar +
- FélixHartmann +
- Fernando Perez
- 弗兰克B +
- 弗兰克Breitling +
- 弗雷德里克
- 加布里埃尔
- GaelVaroquaux
- 纪尧姆同志+
- 韩根
- HaroldMills +
- hklemm +
- jamestwebber +
- 杰森·马登+
- 杰伊·布尔克
- jeromekelleher +
- JesúsGómez+
- jnothman +
- JohannesSchönberger+
- 约翰·本尼迪克特+
- John Salvatier +
- John Stechschulte +
- 乔纳森·沃尔特曼
- Joon Ro +
- Jos de Kloe +
- 约瑟夫·马丁 - 拉加德+
- 乔希·华纳(Mac)+
- JosteinBøFløystad
- Juan Luis CanoRodríguez+
- 朱利安·泰勒+
- Julien Phalip +
- K.-Michael Aye +
- Kumar Appaiah +
- Lars Buitinck
- Leon Weber +
- Luis Pedro Coelho
- Marcin Juszkiewicz
- Mark Wiebe
- Marten van Kerkwijk +
- Martin Baeuml +
- 马丁·斯塔克
- Martin Teichmann +
- Matt Davis +
- 马修·布雷特
- Maximilian Albert +
- m-d-w +
- 迈克尔Droettboom
- mwtoews +
- Nathaniel J. Smith
- Nicolas Scheffer +
- Nils Werner +
- ochoadavid +
- OndřejČertík
- ovillellas +
- 保罗·伊万诺夫
- Pauli Virtanen
- peterjc
- Ralf Gommers
- Raul Cota +
- 理查德·哈特斯利+
- 罗伯特·科斯塔+
- 罗伯特·凯恩
- Rob Ruana +
- Ronan Lamy
- Sandro Tosi
- Sascha Peilicke +
- 塞巴斯蒂安·伯格
- 船长海鸟
- Stefan van der Walt
- 史蒂夫+
- Arakaki +
- Thomas Robitaille +
- Tomas Tomecek +
- Travis E. Oliphant
- Valentin Haenel
- Vladimir Rutsky +
- Warren Weckesser
- 雅罗斯拉夫Halchenko
- Yury V. Zaytsev +
共有119人贡献了这个版本。人们用他们的名字“+”第一次提供补丁。
这是1.7.x系列中的仅修复版本。它支持Python 2.4 - 2.7和3.1 - 3.3,是支持Python 2.4 - 2.5的最后一个系列。
Issues fixed¶
- gh-3153:不充分填充时不要重复使用nditer缓冲区
- gh-3192:f2py崩溃与UnboundLocalError异常
- gh-442:Concatenate with axis = None现在需要相等数量的数组元素
- gh-2485:修正astype('S')string truncate问题
- gh-3312:count_nonzero中的错误
- gh-2684:numpy.ma.average在某些条件下将复合体转换为float
- gh-2403:具有命名组件的masked数组的行为不符合预期
- gh-2495:np.ma.compress处理输入错误的顺序
- gh-576:将__len__方法添加到ma.mvoid
- gh-3364:降低mmap切片的性能退化
- gh-3421:修复GetStridedCopySwap中的非交换跨域副本
- gh-3373:修复datetime元数据初始化中的小泄漏
- gh-2791:添加平台特定的python include目录到搜索路径
- gh-3168:修复未定义的函数并添加整数除法
- gh-3301:memmap不能使用临时文件在python3
- gh-3057:distutils.misc_util.get_shared_lib_extension返回错误的调试扩展
- gh-3472:将模块扩展添加到load_library搜索列表
- gh-3324:比较函数(gt,ge,...)__array_priority__
- gh-3497:np.insert不正确地与参数'axis = -1'
- gh-3541:使预处理器测试在halffloat.c中一致
- gh-3458:array_ass_boolean_subscript()将不存在的数据写入数组
- gh-2892:在零尺度索引数组中的回归
- gh-3608:从tuple填充struct时的回归
- gh-3701:添加对Python 3.4 ast.NameConstant的支持
- gh-3712:不要假定xerbla中启用了GIL
- gh-3712:修复lapack_litemodule中的LAPACK错误处理
- gh-3728:f2py修复对错误的对象
- gh-3743:哈希改变了签名在Python 3.3
- gh-3793:标量int哈希在64位python3上断开
- gh-3160:SandboxViolation在Mac OS X 10.8.3上轻松安装1.7.0
- gh-3871:npy_math.h对于具有SUNWspro12.2的Solaris具有无效的isinf
- gh-2561:禁用检查python3中的oldstyle类
- gh-3900:确保未实现在MaskedArray ufunc的传递
- gh-2052:del标量下标引起segfault
- gh-3832:修复一些未初始化的用法和memleaks
- gh-3971:f2py将string.lowercase更改为string.ascii_lowercase(对于python3)
- gh-3480:numpy.random.binomial nError = 0的ValueError
- gh-3992:hypot(inf,0)不应该引起警告,hypot(inf,inf)错误的结果
- gh-4018:处理非常大的数组的分段故障
- gh-4094:修复_strided_to_strided_string_to_datetime中的NaT处理
- gh-4051:修复_strided_to_strided_string_to_datetime中的未初始化使用
- gh-4123:lexsort segfault
- gh-4141:修复了一些问题,显示与python 3.4b1
这是1.7.x系列中的仅修复版本。它支持Python 2.4 - 2.7和3.1 - 3.3,是支持Python 2.4 - 2.5的最后一个系列。
Issues fixed¶
- gh-2973:修复1在numpy.test()
- gh-2983:BUG:gh-2969:Backport内存泄漏修复80b3a34。
- gh-3007:Backport gh-3006
- gh-2984:反向固定复杂多项式拟合
- gh-2982:BUG:使nansum与布尔运行。
- gh-2985:Backport大排序修复
- gh-3039:Backport对象接受
- gh-3105:反向端口修复op axis初始化
- gh-3108:BUG:Bento构建后缺少npy-pkg-config ini文件。
- gh-3124:BUG:PyArray_LexSort分配了太多的临时内存。
- gh-3131:BUG:导出的f2py_size符号阻止链接多个f2py模块。
- gh-3117:Backport gh-2992
- gh-3135:DOC:添加提到PyArray_SetBaseObject窃取引用
- gh-3134:DOC:在fft docs中修正拼写错误(索引变量为“m”,而不是“n”)。
- gh-3136:Backport#3128
此版本包括几个新功能以及许多错误修复和重构。它支持Python 2.4 - 2.7和3.1 - 3.3,是最后一个支持Python 2.4 - 2.5的版本。
Highlights¶
where=参数到ufuncs(允许使用布尔数组来选择计算应该在哪里完成)vectorize改进(添加了“excluded”和“cache”关键字,一般清理和错误修复)numpy.random.choice(随机样本生成函数)
Compatibility notes¶
在未来版本的numpy中,函数np.diag,np.diagonal和ndarrays的对角线方法将返回一个视图到原始数组,而不是像现在那样产生一个副本。如果你写到由任何这些函数返回的数组,这将产生不同。为了方便这个转换,numpy 1.7生成一个FutureWarning,如果它检测到你可能试图写入这样的数组。有关详细信息,请参阅np.diagonal的文档。
与上面的np.diagonal类似,在将来的numpy版本中,通过字段名称列表对记录数组进行索引,将会将视图返回到原始数组,而不是像现在那样生成副本。和np.diagonal一样,numpy 1.7如果检测到你可能试图写入这样一个数组,则会生成一个FutureWarning。有关详细信息,请参阅数组索引的文档。
在未来版本的numpy中,UFunc out =参数的默认转换规则将从“unsafe”更改为“same_kind”。(这也适用于就地操作,如a + = b,它等效于np.add(a,b,out = a)。)大多数违反“same_kind”规则的用法可能是错误,因此此更改可能会暴露之前在依赖于NumPy的项目中未检测到的错误。在这个版本的numpy中,这样的用法将继续成功,但会引发DeprecationWarning。
全数组布尔索引已优化,以使用不同的优化代码路径。这个代码路径应该产生相同的结果,但任何反馈关于您的代码的更改将不胜感激。
尝试写入只读数组(一个arr.flags.writeable设置为False)用于提高RuntimeError,ValueError或TypeError不一致,具体取决于代码路径被采取。它现在一直引发一个ValueError。
如果从1.5升级,则通常在1.6和1.7中已经添加了大量代码,并且改变了一些代码路径,特别是在类型分辨率和通用函数上的缓冲迭代的领域。这可能会对你的代码有影响,特别是如果你依赖于过去的意外行为。
New features¶
Reduction UFuncs Generalize axis= Parameter¶
任何ufunc.reduce函数调用,以及其他减少像sum,prod,any,all,max和min支持选择轴的子集来减少。以前,可以说axis = None表示所有轴,或者axis =#选择单个轴。现在,还可以说axis =(#,#)选择一个要进行缩小的轴列表。
Reduction UFuncs New keepdims= Parameter¶
有一个新的keepdims =参数,如果设置为True,不会抛弃还原轴,而是将它们设置为大小1。设置此选项时,缩小结果将正确地广播到缩小的原始操作数。
Datetime support¶
注意
datetime API在1.7.0中是实验,并且可能在未来版本的NumPy中进行更改。
与NumPy 1.6相比,datetime64有很多修复和增强功能:
- 解析器是相当严格的只接受ISO 8601日期,有一些方便的扩展
- 正确转换单位
- datetime算术正常工作
- 工作日功能(允许在仅一周中的某些天有效的上下文中使用日期时间)
更多详细信息,请参考doc / source / reference / arrays.datetime.rst中的注释(也可在数组.datetime.html的在线文档中找到)。
Custom formatter for printing arrays¶
请参阅numpy.set_printoptions函数的新formatter参数。
New function numpy.random.choice¶
已添加通用采样函数,其将从给定的数组样生成样本。样本可以具有或不具有替换,并且具有统一或给定的非均匀概率。
New function isclose¶
返回一个布尔数组,其中两个数组在容差内在元素方面相等。可以指定相对和绝对公差。
Preliminary multi-dimensional support in the polynomial package¶
Axis关键字已添加到积分和微分函数中,并且在评估函数中添加了张量关键字。这些添加允许在这些函数中使用多维系数数组。用于评估网格或点集上的2-D和3-D系数数组的新功能与可用于拟合的2-D和3-D伪Vandermonde矩阵一起添加。
Ability to pad rank-n arrays¶
添加了包含用于填充n维数组的功能的填充模块。各种私有填充函数作为选项暴露给公共“填充”函数。例:
pad(a, 5, mode='mean')
电流模式为constant,edge,linear_ramp,maximum,mean,median,minimum,reflect,symmetric,wrap和<function>。
New argument to searchsorted¶
搜索排序函数现在接受“排序器”参数,它是排序数组以进行搜索的排列数组。
Build system¶
增加了对AArch64架构的实验支持。
C API¶
新函数PyArray_RequireWriteable提供了一个用于检查数组可写性的一致性接口 - 任何与数组一起工作的C代码,其WRITEABLE标志不知道为真先验,应确保在写入之前调用此函数。
已添加NumPy C样式指南(doc/C_STYLE_GUIDE.rst.txt)。
Changes¶
General¶
函数np.concatenate尝试匹配其输入数组的布局。以前,布局没有遵循任何特定的原因,并且在选择用于级联的特定轴上以不期望的方式。一个错误也被修正,默默允许超出轴参数。
ufuncs logical_or,logical_and和logical_not现在跟随Python对象数组的行为,而不是尝试调用对象上的方法。例如,表达式(3和'test')产生字符串'test',现在np.logical_and(np.array(3,'O'),np.array('test','O'))测试“。
ndarrays上的.base属性用于视图,以确保拥有内存的基础数组不会被过早解除分配,现在当您拥有视图视图时会折叠引用。例如:
a = np.arange(10)
b = a[1:]
c = b[1:]
在numpy 1.6中,c.base是b,c.base.base是a。在numpy 1.7中,c.base是a。
为了增加依赖于.base的旧行为的软件的向后兼容性,我们只“跳过”与新创建的视图具有完全相同类型的对象。如果你使用ndarray子类,这会产生不同。例如,如果我们混合了ndarray和matrix对象,它们是同一个原始ndarray上的所有视图:
a = np.arange(10)
b = np.asmatrix(a)
c = b[0, 1:]
d = c[0, 1:]
那么d.base将是b。这是因为d是matrix对象,因此只要遇到其他matrix对象,折叠过程才会继续。它以该顺序考虑c,b和a,并且b是该列表中的最后一个条目是matrix对象。
Casting Rules¶
由于与NA相关的工作,铸造规则在角落情况下经历了一些变化。特别是对于标量+标量的组合:
- 之前对于任何其他数字(?bhilqp BHI)的操作,longlong t>类型(q)现在保持longlong它被转换为int _(1)。ulonglong t>类型(Q)现在保持为ulonglong而不是uint(L )。
- timedelta64类型(m)现在可以与任何整数类型(bhilqp BHILQP)混合,以前提出TypeError t3 >。
对于数组+标量,上述规则只是广播,除了数组和标量是无符号/有符号整数的情况,然后结果转换为数组类型(可能更大的大小),如下例所示:
>>> (np.zeros((2,), dtype=np.uint8) + np.int16(257)).dtype
dtype('uint16')
>>> (np.zeros((2,), dtype=np.int8) + np.uint16(257)).dtype
dtype('int16')
>>> (np.zeros((2,), dtype=np.int16) + np.uint32(2**17)).dtype
dtype('int32')
大小是否增加取决于标量的大小,例如:
>>> (np.zeros((2,), dtype=np.uint8) + np.int16(255)).dtype
dtype('uint8')
>>> (np.zeros((2,), dtype=np.uint8) + np.int16(256)).dtype
dtype('uint16')
此外,还将complex128标量+ float32数组转换为complex64。
在NumPy 1.7中,必须通过明确指定类型作为第二个参数来构造datetime64类型(M)(例如np.datetime64(2000, / t3> 'Y'))。
Deprecations¶
General¶
不推荐使用_format数组属性指定自定义字符串格式化程序。可以使用numpy.set_printoptions或numpy.array2string中的新formatter关键字。
多项式包中已弃用的导入已删除。
concatenate现在在轴 != 0提高1D数组的DepractionWarning。numpy的版本我们现在允许这样做,但在适当的时候,我们会引发一个错误。
C-API¶
直接访问PyArrayObject *的字段已被弃用。对于许多版本,已建议直接访问。期待类似的弃用PyArray_Descr *和其他核心对象在未来为准备NumPy 2.0。
old_defines.h中的宏已弃用,将在下一个主要版本(> = 2.0)中删除。sed脚本工具/ replace_old_macros.sed可用于将这些宏替换为较新版本。
您可以在包含任何NumPy标头之前,将#defining NPY_NO_DEPRECATED_API设为目标版本号,例如NPY_1_7_API_VERSION,借此针对已弃用的C API测试您的程式码。
NPY_TYPES枚举的NPY_CHAR成员已弃用,将在NumPy 1.8中删除。有关详细信息,请参阅gh-2801上的讨论。
NumPy 1.6.2 Release Notes¶
这是1.6.x系列中的一个修正版本。由于NumPy 1.7.0版本的延迟,此版本包含比常规NumPy bugfix版本更多的修复。它还包括一些文档和构建改进。
Issues fixed¶
numpy.core¶
- #2063:make unique()返回一致的索引
- #1138:允许从空缓冲区或空切片创建数组
- #1446:关于vstack和concatenate的正确注释
- #1149:make argmin()适用于datetime
- #1672:fix allclose()为标量inf工作
- #1747:make np.median()适用于0-D数组
- #1776:使复数除以零以正确产生inf
- #1675:为format()函数添加标量支持
- #1905:明确检查allclose中的NaNs()
- #1952:允许在std()和var()中浮动ddof,
- #1948:修正用空列表索引字符串的回归
- #2017:fix type hashing
- #2046:删除数组属性会导致segfault
- #2033:a ** 2.0类型不正确
- #2045:make attribute / iterator_element删除不是segfault
- #2021:fixsfault in searchsorted()
- #2073:fix float16 __array_interface__ bug
numpy.lib¶
- #2048:在NpzFile中断参考循环
- #1573:savetxt()现在处理复杂的数组
- #1387:allow bincount()接受空数组
- #1899:fixed histogramdd()bug with empty inputs
- #1793:修复py3k下的npyio测试失败
- #1936:修复子阵列类型的额外嵌套
- #1848:make tril / triu返回与原数组相同的dtype
- #1918:使用Py_TYPE访问ob_type,因此它也适用于Py3
numpy.distutils¶
- #1261:将AIX上的编译标志从-O5更改为-O3
- #1377:更新HP编译器标志
- #1383:为HPUX上的C ++代码提供更好的支持
- #1857:fix build for py3k + pip
- BLD:在建筑物没有清理的情况下提高清晰的警告
- BLD:遵循build_clib中的build_ext编码惯例
- BLD:在system_info.py中修复对OS X上的Intel CPU的检测
- BLD:在Ubuntu&co上添加对新X11目录结构的支持。
- BLD:将ufsparse添加到库搜索路径。
- BLD:将“pgfortran”添加为波特兰集团中的有效编译器
- BLD:更新版本匹配regexp为IBM AIX Fortran编译器。
numpy.random¶
- BUG:在mtrand中使用npy_intp而不是long
Changes¶
numpy.f2py¶
- ENH:引入新选项extra_f77_compiler_args和extra_f90_compiler_args
- BLD:改进fcompiler值的报告
- BUG:修复f2py test_kind.py测试
Issues Fixed¶
- #1834:einsum对于特定形状失败
- #1837:einsum throws nan或者冻结特定数组形状的python
- #1838:object structured type数组回归
- #1851:1.6.0中基于SWIG的代码的回归
- #1863:在使用astype()复制的数组上操作时出现错误结果
- #1870:修正对象数组分配的角点
- #1843:Py3k:使用recarray修复错误
- #1885:nditer:检测双缩减循环时出错
- #1874:f2py:fix -include_paths bug
- #1749:Fix ctypes.load_library()
- #1895/1896:iter:writeonly操作数并不总是被正确缓冲
此版本包括几个新功能,以及许多错误修复和改进的文档。它向后兼容1.5.0版本,并支持Python 2.4 - 2.7和3.1 - 3.2。
Highlights¶
- 重新引入datetime dtype支持以处理数组中的日期。
- 一种新的16位浮点类型。
- 一个新的迭代器,它提高了许多函数的性能。
New features¶
New 16-bit floating point type¶
此版本添加对IEEE 754-2008 binary16格式的支持,可用作数据类型numpy.half。在Python中,类型的行为类似于float或double,C扩展可以使用暴露的半浮点API添加对它的支持。
New iterator¶
添加了一个新的迭代器,用单个对象和API替代现有迭代器和多迭代器的功能。此迭代器适用于不同于C或Fortran连续的一般内存布局,并处理标准NumPy和自定义广播。ufuncs提供的缓冲,自动数据类型转换和可选的输出参数,但是很难在其他地方复制,现在这个迭代器暴露。
Legendre, Laguerre, Hermite, HermiteE polynomials in numpy.polynomial¶
扩展多项式包中可用的多项式数量。此外,为了指定domain映射到的范围,已经向类添加了新的window属性。这对于Laguerre,Hermite和HermiteE多项式最有用,它们的自然域是无限的,并且提供了一种更直观的方式来获得值的正确映射,而不会对域执行非自然的技巧。
Fortran assumed shape array and size function support in numpy.f2py¶
F2py现在支持使用假定形状数组的Fortran 90例程。在这样的例程可以从Python调用,但相应的Fortran例程接收假设形状数组为零长度数组,导致不可预测的结果。感谢LorenzHüdepohl指出了使用假设形状数组的接口例程的正确方法。
此外,f2py现在支持在尺寸规范中使用两个参数size函数的Fortran例程的自动包装。
Other new functions¶
numpy.ravel_multi_index:将多索引元组转换为平面索引的数组,将边界模式应用于索引。
numpy.einsum:评估爱因斯坦求和约定。使用爱因斯坦求和约定,许多常见的多维数组操作可以以简单的方式表示。此函数提供一种计算这种求和的方法。
numpy.count_nonzero:计算数组中非零元素的数量。
numpy.result_type和numpy.min_scalar_type:这些函数公开ufuncs和其他操作使用的底层类型提升,以确定输出的类型。这些改进了提供类似功能但不匹配ufunc实现的numpy.common_type和numpy.mintypecode。
Changes¶
default error handling¶
默认错误处理已从print更改为warn,除了underflow(仍保留为ignore)。
numpy.distutils¶
支持几个新的编译器来构建Numpy:OS X上的Portland Group Fortran编译器,Linux上的PathScale编译器套件和64位Intel C编译器。
numpy.testing¶
测试框架获得了numpy.testing.assert_allclose,其提供比比较浮点数组更方便的方法比assert_almost_equal,assert_approx_equal和assert_array_almost_equal。
C API¶
除了用于新迭代器和半数据类型的API之外,还对C API进行了一些其他添加。ufuncs使用的类型提升机制通过PyArray_PromoteTypes,PyArray_ResultType和PyArray_MinScalarType来公开。添加了一个新的枚举NPY_CASTING,用于控制允许的转换类型。这由新函数PyArray_CanCastArrayTo和PyArray_CanCastTypeTo使用。处理将任意python对象转换为数组的更灵活的方法是由PyArray_GetArrayParamsFromObject显示。
Deprecated features¶
不推荐使用numpy.histogram中的“normed”关键字。其功能将由新的“density”关键字替换。
Removed features¶
numpy.fft¶
函数refft,refft2,refftn,irefft,irefft2,irefftn,它们是相同函数的别名,而名称中没有'e'。
numpy.memmap¶
已删除memmap的sync()和close()方法。请改用flush()和“del memmap”。
numpy.lib¶
已弃用的函数numpy.unique1d,numpy.setmember1d,numpy.intersect1d_nu和numpy.lib.ufunclike.log2被去除。
numpy.ma¶
从numpy.ma模块中删除了几个已弃用的项目:
* ``numpy.ma.MaskedArray`` "raw_data" method
* ``numpy.ma.MaskedArray`` constructor "flag" keyword
* ``numpy.ma.make_mask`` "flag" keyword
* ``numpy.ma.allclose`` "fill_value" keyword
Highlights¶
Python 3 compatibility¶
这是第一个与Python 3兼容的NumPy版本。支持Python 3和Python 2是从单个代码库完成的。有关更改的详细说明可以在http://projects.scipy.org/numpy/browser/trunk/doc/Py3K.txt找到。
请注意,Numpy测试框架依赖于nose,它没有Python 3兼容的版本。可以在http://bitbucket.org/jpellerin/nose3/找到可用的Python 3分支的鼻子。
将SciPy移植到Python 3预计很快就会完成。
New features¶
Warning on casting complex to real¶
当一个复数转换成一个实数时,Numpy现在发出numpy.ComplexWarning。例如:
>>> x = np.array([1,2,3])
>>> x[:2] = np.array([1+2j, 1-2j])
ComplexWarning: Casting complex values to real discards the imaginary part
演员确实丢弃了虚部,这可能不是在所有情况下的预期行为,因此警告。此警告可以以标准方式关闭:
>>> import warnings
>>> warnings.simplefilter("ignore", np.ComplexWarning)
Dot method for ndarrays¶
Ndarrays现在有点积也是一种方法,它允许写矩阵产品链
>>> a.dot(b).dot(c)
而不是更长的选择
>>> np.dot(a, np.dot(b, c))
linalg.slogdet function¶
slogdet函数返回矩阵行列式的符号和对数。因为行列式可能涉及许多小/大值的乘积,所以结果通常比通过简单乘法获得的结果更精确。
new header¶
新的头文件ndarraytypes.h包含来自ndarrayobject.h的不依赖于PY_ARRAY_UNIQUE_SYMBOL和NO_IMPORT / _ARRAY宏的符号。概括地说,这些符号是类型,typedef和枚举;数组函数调用留在ndarrayobject.h中。这允许用户包括阵列相关类型和枚举,而不需要关心宏扩展及其副作用。
Changes¶
polynomial.polynomial¶
- polyint和polyder函数现在检查指定数量的积分或推导是非负整数。数字0是两个函数的有效值。
- 多项式类已添加度法。
- trimdeg方法已添加到多项式类中。它操作类似truncate,除了参数是所需的结果的程度,而不是系数的数量。
- Polynomial.fit现在使用None作为拟合的默认域。可以使用[]作为域值来指定默认多项式域。
- 权重可以在polyfit和Polynomial.fit中使用
- 一个linspace方法已添加到Polynomial类中,以方便绘图。
- 加入polymulx功能。
polynomial.chebyshev¶
- chebint和chebder函数现在检查指定数量的积分或推导是非负整数。数字0是两个函数的有效值。
- Chebyshev类已经增加了一个度数方法。
- 一个trimdeg方法已经添加到切比雪夫类。它操作类似truncate,除了参数是所需的结果的程度,而不是系数的数量。
- Chebyshev.fit现在使用None作为默认域。可以使用[]作为域值来指定默认Chebyshev域。
- 重量可以用于chebfit和Chebyshev.fit
- 一个linspace方法已经添加到Chebyshev类中,以减轻绘图。
- 加入chebmulx功能。
- 添加了第一和第二种Chebyshev点的功能。
histogram¶
在两年过渡期之后,直方图函数的旧行为已被淘汰,并且“新”关键字已被移除。
Highlights¶
- 新的datetime dtype支持处理数组中的日期
- 更快的导入时间
- ufuncs的扩展数组包装机制
- 新邻域迭代器(仅C级)
- npymath中的C99样复杂函数
New features¶
Extended array wrapping mechanism for ufuncs¶
已经向ndarray添加了一个__array_prepare__方法,以便为子类提供与ufuncs和ufunc-like函数交互更大的灵活性。ndarray已经提供了__array_wrap__,它允许子类为结果设置数组类型,并在离开ufunc之前填充元数据(如在MaskedArray的实现中所见)。对于某些应用程序,有必要在中提供检查并填充元数据。__array_prepare__因此在ufunc初始化输出数组之后,但在计算结果并填充它之前调用。这样,可以在可能修改数据的操作之前进行检查并产生错误。
Automatic detection of forward incompatibilities¶
以前,如果扩展是针对NumPy的版本N构建的,并且在具有NumPy M的系统上使用
New iterators¶
一个新的邻域迭代器已添加到C API。它可以用于遍历数组的邻域中的项目,并且可以自动处理边界条件。可以使用零和一个填充,以及任意常数值,镜像和圆形填充。
New polynomial support¶
新模块chebyshev和多项式已添加。新的多项式模块与numpy中的当前多项式支持不兼容,但是很像新的chebyshev模块。最显着的差别是,从低到高功率指定系数,低电平函数不使用切比雪夫和多项式类作为争论,并且切比雪夫和多项式类包括域。域之间的映射是线性替换,并且两个类可以彼此转换,允许例如一个域中的切比雪夫序列被扩展为另一域中的多项式。通常应该使用新类而不是低级函数,后者用于希望构建自己的类的人。
新模块不会自动导入到numpy命名空间中,它们必须使用“import numpy.polynomial”语句显式引入。
New C API¶
以下C函数已添加到C API:
- PyArray_GetNDArrayCFeatureVersion:返回加载的numpy的API版本。
- PyArray_Correlate2 - 像PyArray_Correlate,但实现相关的通常定义。输入不交换,并且共轭用于复数数组。
- PyArray_NeighborhoodIterNew - 一个新的迭代器,迭代一个点的邻域,具有自动边界处理。它在C-API参考的迭代器部分中有记录,你可以在numpy.core的multiarray_test.c.src文件中找到一些例子。
New ufuncs¶
以下ufunc已添加到C API:
- copysign - 返回第一个参数的值和从第二个参数复制的符号。
- nextafter - 将第一个参数的下一个可表示浮点值返回到第二个参数。
New defines¶
alpha处理器现在已定义并且可在numpy / npy_cpu.h中使用。PARISC处理器的检测失败已修复。定义如下:
- NPY_CPU_HPPA:PARISC
- NPY_CPU_ALPHA:Alpha
Testing¶
- deprecated decorator:这个装饰器可以用来避免在测试时杂乱的测试输出DeprecationWarning通过装饰测试有效地提高。
- assert_array_almost_equal_nulps:用于比较两个数组的浮点值的新方法。使用此函数,如果两个值之间没有多少可表示的浮点值,则认为两个值接近,因此当值波动很大时,比assert_array_almost_equal更稳健。
- assert_array_max_ulp:如果在两个浮点值之间有多于N个可表示的数字,则产生一个断言。
- assert_warns:如果可调用方不会生成相应类的警告,而不改变警告状态,则抛出AssertionError。
Reusing npymath¶
在1.3.0中,我们开始将可移植C数学例程放在npymath库中,以便人们可以使用它们来编写便携式扩展。不幸的是,它是不可能轻松地链接到这个库:在1.4.0,支持已添加到numpy.distutils,以便第三方可以重用这个库。有关更多信息,请参阅coremath文档。
Improved set operations¶
在以前版本的NumPy中,如果输入数组包含重复项,某些设置函数(intersect1d,setxor1d,setdiff1d和setmember1d)可能返回不正确的结果。这些现在可以正确工作输入数组与副本。setmember1d已经重命名为in1d,与接受具有重复的数组的更改不同,它不再是集合操作,并且在概念上类似于Python运算符“in”的元素化版本。所有这些函数现在接受布尔关键字假设_unique。默认情况下这是False,但是如果输入数组已知不包含重复,则可以设置为True,这可以提高函数的执行速度。
Improvements¶
numpy导入明显更快(从20到30%,具体取决于平台和计算机)
排序功能现在排序到最后。
- 实际排序顺序是[R,nan]
- 复杂排序顺序为[R + Rj,R + nanj,nan + Rj,nan + nanj]
具有相同纳米位置的复数根据非纳米部分(如果存在)进行排序。
类型比较函数已经与新的排序顺序一致。现在,搜索排序适用于包含纳米值的排序数组。
复杂分裂已经使得更多的抗溢出。
复杂的地面分裂已经使得更多的抗溢出。
Deprecations¶
以下函数已弃用:
- correlate:它需要一个新的关键字参数old_behavior。当为True(默认值)时,它返回与之前相同的结果。当False时,计算常规相关性,并取复数数组的共轭。旧的行为将在NumPy 1.5中删除,并在1.4中引发DeprecationWarning。
- unique1d:使用unique。unique1d在1.4中引发了弃用警告,并将在1.5中删除。
- intersect1d_nu:改为使用intersect1d。intersect1d_nu在1.4中引发了弃用警告,将在1.5中删除。
- setmember1d:改为使用in1d。setmember1d在1.4中引发了弃用警告,将在1.5中删除。
以下引发错误:
- 当操作0-d数组时,
numpy.max和其他函数仅接受axis=0,axis=-1和axis=None。使用out-of-bounds轴是一个错误的指示,所以Numpy现在为这些情况引发一个错误。- 不再允许指定
轴 > MAX_DIMSNumpy现在提出一个错误,而不是类似于axis=None的行为。
Internal changes¶
Use C99 complex functions when available¶
numpy复杂类型现在保证与ABI兼容C99复杂类型,如果availble在平台上。更多,复杂的ufunc现在使用我们自己的平台C99功能intead。
split multiarray and umath source code¶
多阵列和umath的源代码已经被拆分成单独的逻辑编译单元。这应该使源代码更适合新手。
Separate compilation¶
默认情况下,multiarray(和umath)的每个文件都合并为一个用于编译,如前所述,但如果NPY_SEPARATE_COMPILATION env变量设置为非负值,则启用每个文件的实验性单独编译。这使得编译/调试周期在处理核心numpy时更快。
Highlights¶
Generalized ufuncs¶
通常需要循环不仅是标量上的函数,而且还包括向量(或数组)上的函数,如http://scipy.org/scipy/numpy/wiki/GeneralLoopingFunctions上所述。我们建议通过泛化通用函数(ufuncs)来实现这个概念,并提供一个C语言实现,在numpy代码库中增加约500行。在当前(专用)ufunc中,基本函数限于逐元素操作,而通用版本通过“子数组”操作支持“子数组”。Perl向量库PDL提供了类似的功能,其术语在下面被重复使用。
每个广义ufunc具有与其相关联的信息,其具有输入的“核心”维度以及输出的对应维度(元素方式ufunc具有零核心维度)。所有参数的核心维度列表称为ufunc的“签名”。例如,ufunc numpy.add有签名“(),() - >()”定义两个标量输入和一个标量输出。
另一个例子是(见GeneralLoopingFunctions页)具有签名“(i),(i) - >()”的函数inner1d(a,b)。这将沿着每个输入的最后一个轴应用内积,但保持其余索引完整。基本的基本函数称为3×5次。在签名中,我们为每个输入指定一个核心维度“(i)”,为输出指定零核心维度“()”,因为它需要两个1-d数组并返回一个标量。通过使用相同的名称“i”,我们指定两个对应的维度应该是相同的大小(或其中一个大小为1,将被广播)。
超过核心尺寸的尺寸称为“环”尺寸。在上述示例中,这对应于(3,5)。
通常的numpy“广播”规则适用,其中签名确定每个输入/输出对象的维度如何分裂为核心和环路维度:
虽然输入数组具有比相应数量的核心维度更小的维度,但是1是预先考虑其形状。核心尺寸从所有输入中删除,剩余尺寸被广播;定义环路尺寸。输出由环尺寸加上输出芯尺寸给出。
Experimental Windows 64 bits support¶
Numpy现在可以建立在windows 64位(仅amd64,而不是IA64),与MS编译器和mingw-w64编译器:
这是高度实验:不要用于生产使用。有关限制和如何自己构建的更多信息,请参阅INSTALL.txt,Windows 64位部分。
New features¶
Formatting issues¶
浮点格式现在由numpy而不是C运行时处理:这使得区域设置独立格式化,更强健的字符串和相关方法。特殊值(inf和nan)在不同平台(nan vs IND / NaN等)也更一致,并且与最近的python格式化工作(在2.6和更高版本中)更一致。
Nan handling in max/min¶
最大/最小ufuncs现在可靠地传播nans。如果其中一个参数是一个纳米,那么纳米就会退化。这影响np.min / np.max,amin / amax和数组方法max / min。新的ufuncs fmax和fmin已被添加以处理非传播的nans。
Nan handling in sign¶
ufunc符号现在返回anan的符号的nan。
New ufuncs¶
- fmax - 与整数类型和非nan浮点的最大值相同。如果一个参数是nan,则返回非nan参数,如果两个参数均为nan,则返回nan。
- fmin - 与整数类型和非nan浮点的最小值相同。如果一个参数是nan,则返回非nan参数,如果两个参数均为nan,则返回nan。
- deg2rad - 将度数转换为弧度,与弧度ufunc相同。
- rad2deg - 将弧度转换为度,与度ufunc相同。
- log2 - 基2对数。
- exp2 - 基数2指数。
- 截断浮点到零的最接近的整数。
- logaddexp - 添加作为对数存储的数字,并返回结果的对数。
- logaddexp2 - 添加以2为底的对数存储的数字,并返回结果结果的以2为底的对数。
Masked arrays¶
几个新功能和错误修复,包括:
- 结构化数组现在应该完全支持MaskedArray(r6463,r6324,r6305,r6300,r6294 ...)
- 小错误修复(r6356,r6352,r6335,r6299,r6298)
- 改进对__iter__(r6326)的支持
- 制作的基础类,共享掩码和硬掩码可供用户访问(但只读)
- doc更新
gfortran support on windows¶
Gfortran现在可以用作windows上的numpy的fortran编译器,即使C编译器是Visual Studio(VS 2005及更高版本; VS 2003将不工作)。Gfortran + Visual studio不工作在窗口64位(但gcc + gfortran)。目前还不清楚是否可以在x64上使用gfortran和visual studio。
Arch option for windows binary¶
现在可以从安装的superpack的命令行旁路绕过自动的拱形检测:
numpy-1.3.0-superpack-win32.exe / arch = nosse
将安装一个工作在任何x86的numpy,即使正在运行的计算机支持SSE设置。
Deprecated features¶
Histogram¶
直方图的语义已经修改,以解决长期存在的异常值处理问题。主要变化关注
- bin边缘的定义,现在包括最右边缘,和
- 处理上层异常值,现在忽略,而不是在最右边的bin中。
以前的行为仍然可以使用new = False访问,但这已被弃用,并将完全在1.4.0中删除。
Documentation changes¶
已经添加了很多文档。用户指南和引用都可以从sphinx构建。
New C API¶
New defines¶
新的公共C定义可通过numpy / npy_cpu.h获得ARCH特定的代码:
- NPY_CPU_X86:x86 arch(32位)
- NPY_CPU_AMD64:amd64 arch(x86_64,而不是Itanium)
- NPY_CPU_PPC:32位ppc
- NPY_CPU_PPC64:64位ppc
- NPY_CPU_SPARC:32位sparc
- NPY_CPU_SPARC64:64位sparc
- NPY_CPU_S390:S390
- NPY_CPU_IA64:ia64
- NPY_CPU_PARISC:PARISC
还添加了用于CPU端点的新宏(有关详情,请参阅下面的内部更改):
- NPY_BYTE_ORDER:整数
- NPY_LITTLE_ENDIAN / NPY_BIG_ENDIAN定义
那些提供便携式替代glibc endian.h宏的平台没有它。
Portable NAN, INFINITY, etc...¶
npy_math.h现在提供了几个便携式宏来获得NAN,INFINITY:
- NPY_NAN:等同于NAN,其是GNU扩展
- NPY_INFINITY:相当于C99 INFINITY
- NPY_PZERO,NPY_NZERO:分别为正和负零
也可以使用相应的单精度宏和扩展精度宏。为了一致性,已经去除了对NAN的所有引用,或者NAN的本地计算。
Internal changes¶
numpy.core math configuration revamp¶
这应该使移植到新平台更容易,更强大。特别地,配置阶段不需要在目标平台上执行任何代码,这是交叉编译的第一步。
http://projects.scipy.org/numpy/browser/trunk/doc/neps/math_config_clean.txt
umath refactor¶
很多代码清理为umath / ufunc代码(charris)。
Improvements to build warnings¶
Numpy现在可以用-W -Wall构建而不会出现警告
http://projects.scipy.org/numpy/browser/trunk/doc/neps/warnfix.txt
Separate core math library¶
核心数学函数(sin,cos等...对于基本的C类型)已被放入一个单独的库;它充当兼容性层,支持大多数C99数学函数(仅现在是真实的)。库包括针对各种数学函数的平台特定修复,例如使用那些版本应该比直接使用平台函数更加健壮。现有函数的API与C99数学函数API完全相同;唯一的区别是npy前缀(npy_cos vs cos)。
核心库将提供给1.4.0中的任何扩展。
CPU arch detection¶
npy_cpu.h定义了numpy特定的CPU定义,例如NPY_CPU_X86等等。这些可以跨操作系统和工具链进行移植,并在解析头时设置,以便即使在交叉编译的情况下也可以安全使用在构建numpy时不设置值)或多拱二进制文件(例如Max OS X上的胖二进制文件)。
npy_endian.h定义了numpy特定的endianness定义,在glibc endian.h上建模。NPY_BYTE_ORDER等效于BYTE_ORDER,并定义了NPY_LITTLE_ENDIAN或NPY_BIG_ENDIAN中的一个。对于CPU拱门,当编译器解析头文件时设置它们,因此可以用于交叉编译和多拱二进制。